 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Channel Speech Enhancement Using Temporal Convolutional Recurrent Neural Networks
Paper and Code
Feb 02, 2020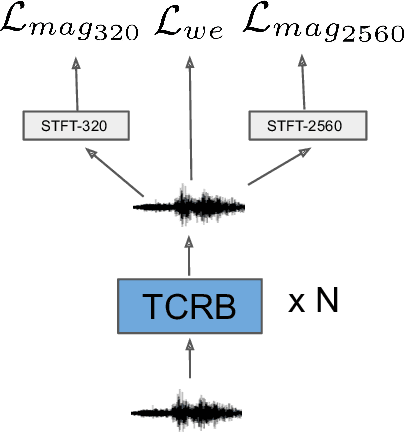
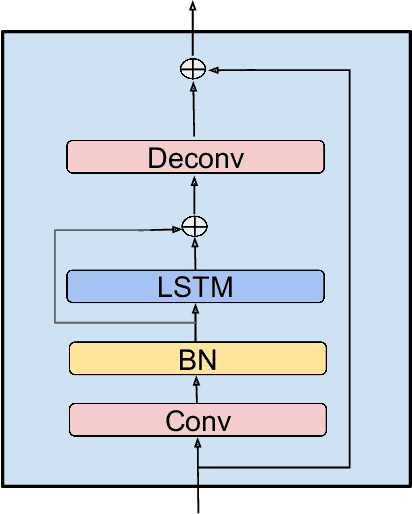

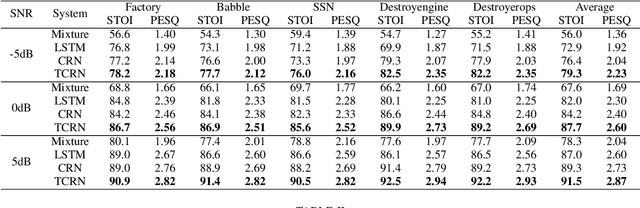
In recent decades, neural network based methods have significantly improved the performace of speech enhancement. Most of them estimate time-frequency (T-F) representation of target speech directly or indirectly, then resynthesize waveform using the estimated T-F representation. In this work, we proposed the temporal convolutional recurrent network (TCRN), an end-to-end model that directly map noisy waveform to clean waveform. The TCRN, which is combined convolution and recurrent neural network, is able to efficiently and effectively leverage short-term ang long-term information. Futuremore, we present the architecture that repeatedly downsample and upsample speech during forward propagation. We show that our model is able to improve the performance of model, compared with existing convolutional recurrent networks. Futuremore, We present several key techniques to stabilize the training process. The experimental results show that our model consistently outperforms existing speech enhancement approaches, in terms of speech intelligibility and quality.