 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Super-Resolution for Imbalanced Textures: A Texture-Aware Diffusion Framework
Apr 15, 2026Generative diffusion priors have recently achieved state-of-the-art performance in natural image super-resolution, demonstrating a powerful capability to synthesize photorealistic details. However, their direct application to remote sensing image super-resolution (RSISR) reveals significant shortcomings. Unlike natural images, remote sensing images exhibit a unique texture distribution where ground objects are globally stochastic yet locally clustered, leading to highly imbalanced textures. This imbalance severely hinders the model's spatial perception. To address this, we propose TexADiff, a novel framework that begins by estimating a Relative Texture Density Map (RTDM) to represent the texture distribution. TexADiff then leverages this RTDM in three synergistic ways: as an explicit spatial conditioning to guide the diffusion process, as a loss modulation term to prioritize texture-rich regions, and as a dynamic adapter for the sampling schedule. These modifications are designed to endow the model with explicit texture-aware capabilities. Experiments demonstrate that TexADiff achieves superior or competitive quantitative metrics. Furthermore, qualitative results show that our model generates faithful high-frequency details while effectively suppressing texture hallucinations. This improved reconstruction quality also results in significant gains in downstream task performance. The source code of our method can be found at https://github.com/ZezFuture/TexAdiff.
OpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation
Mar 23, 2026Earth Observation (EO) is essential for perceiving dynamic land surface changes, yet deploying autonomous EO in open environments is hindered by the immense diversity of multi-source data and heterogeneous tasks. While remote sensing agents have emerged to streamline EO workflows, existing tool-calling agents are confined to closed environments. They rely on pre-defined tools and are restricted to narrow scope, limiting their generalization to the diverse data and tasks. To overcome these limitations, we introduce OpenEarth-Agent, the first tool-creation agent framework tailored for open-environment EO. Rather than calling predefined tools, OpenEarth-Agent employs adaptive workflow planning and tool creation to generalize to unseen data and tasks. This adaptability is bolstered by an open-ended integration of multi-stage tools and cross-domain knowledge bases, enabling robust execution in the entire EO pipeline across multiple application domains. To comprehensively evaluate EO agents in open environments, we propose OpenEarth-Bench, a novel benchmark comprising 596 real-world, full-pipeline cases across seven application domains, explicitly designed to assess agents' adaptive planning and tool creation capabilities. Only essential pre-trained model tools are provided in this benchmark, devoid of any other predefined task-specific tools. Extensive experiments demonstrate that OpenEarth-Agent successfully masters full-pipeline EO across multiple domains in the open environment. Notably, on the cross-benchmark Earth-Bench, our tool-creating agent equipped with 6 essential pre-trained models achieves performance comparable to tool-calling agents relying on 104 specialized tools, and significantly outperforms them when provided with the complete toolset. In several cases, the created tools exhibit superior robustness to data anomalies compared to human-engineered counterparts.
FarSLIP: Discovering Effective CLIP Adaptation for Fine-Grained Remote Sensing Understanding
Nov 18, 2025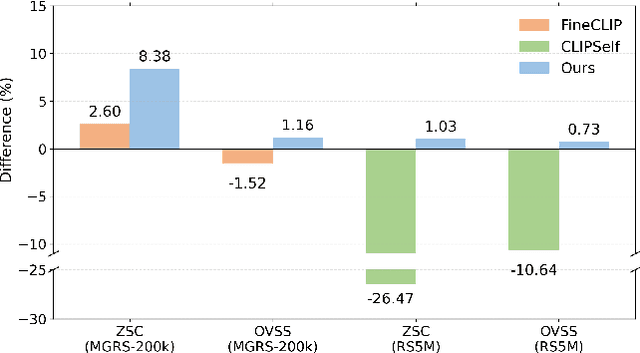
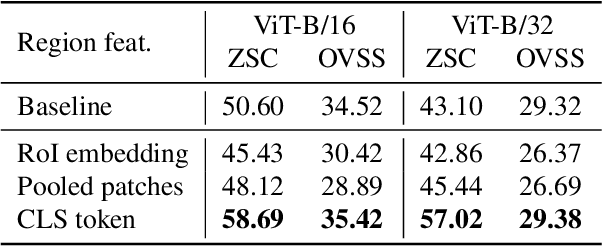
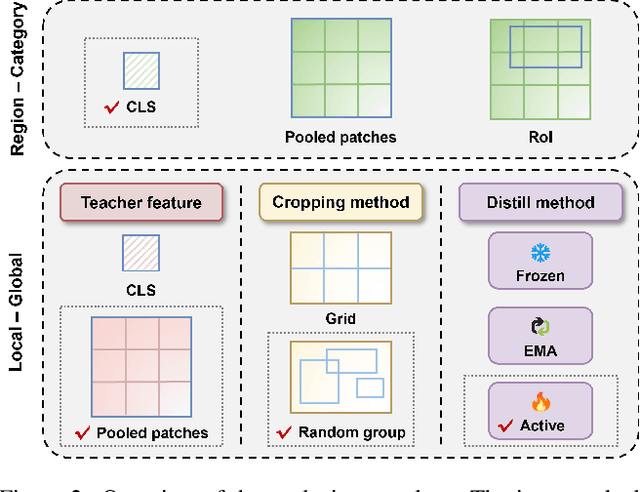
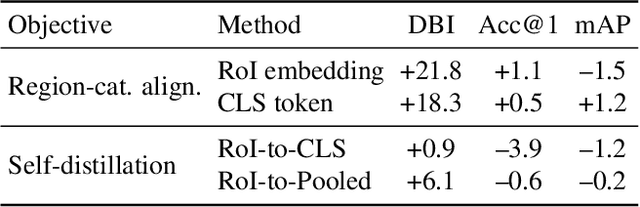
As CLIP's global alignment limits its ability to capture fine-grained details, recent efforts have focused on enhancing its region-text alignment. However, current remote sensing (RS)-specific CLIP variants still inherit this limited spatial awareness. We identify two key limitations behind this: (1) current RS image-text datasets generate global captions from object-level labels, leaving the original object-level supervision underutilized; (2) despite the success of region-text alignment methods in general domain, their direct application to RS data often leads to performance degradation. To address these, we construct the first multi-granularity RS image-text dataset, MGRS-200k, featuring rich object-level textual supervision for RS region-category alignment. We further investigate existing fine-grained CLIP tuning strategies and find that current explicit region-text alignment methods, whether in a direct or indirect way, underperform due to severe degradation of CLIP's semantic coherence. Building on these, we propose FarSLIP, a Fine-grained Aligned RS Language-Image Pretraining framework. Rather than the commonly used patch-to-CLS self-distillation, FarSLIP employs patch-to-patch distillation to align local and global visual cues, which improves feature discriminability while preserving semantic coherence. Additionally, to effectively utilize region-text supervision, it employs simple CLS token-based region-category alignment rather than explicit patch-level alignment, further enhancing spatial awareness. FarSLIP features improved fine-grained vision-language alignment in RS domain and sets a new state of the art not only on RS open-vocabulary semantic segmentation, but also on image-level tasks such as zero-shot classification and image-text retrieval. Our dataset, code, and models are available at https://github.com/NJU-LHRS/FarSLIP.
ARiSE: Auto-Regressive Multi-Channel Speech Enhancement
May 28, 2025We propose ARiSE, an auto-regressive algorithm for multi-channel speech enhancement. ARiSE improves existing deep neural network (DNN) based frame-online multi-channel speech enhancement models by introducing auto-regressive connections, where the estimated target speech at previous frames is leveraged as extra input features to help the DNN estimate the target speech at the current frame. The extra input features can be derived from (a) the estimated target speech in previous frames; and (b) a beamformed mixture with the beamformer computed based on the previous estimated target speech. On the other hand, naively training the DNN in an auto-regressive manner is very slow. To deal with this, we propose a parallel training mechanism to speed up the training. Evaluation results in noisy-reverberant conditions show the effectiveness and potential of the proposed algorithms.
Two-stage Audio-Visual Target Speaker Extraction System for Real-Time Processing On Edge Device
May 28, 2025Audio-Visual Target Speaker Extraction (AVTSE) aims to isolate a target speaker's voice in a multi-speaker environment with visual cues as auxiliary. Most of the existing AVTSE methods encode visual and audio features simultaneously, resulting in extremely high computational complexity and making it impractical for real-time processing on edge devices. To tackle this issue, we proposed a two-stage ultra-compact AVTSE system. Specifically, in the first stage, a compact network is employed for voice activity detection (VAD) using visual information. In the second stage, the VAD results are combined with audio inputs to isolate the target speaker's voice. Experiments show that the proposed system effectively suppresses background noise and interfering voices while spending little computational resources.
Multi-Channel Acoustic Echo Cancellation Based on Direction-of-Arrival Estimation
May 26, 2025Acoustic echo cancellation (AEC) is an important speech signal processing technology that can remove echoes from microphone signals to enable natural-sounding full-duplex speech communication. While single-channel AEC is widely adopted, multi-channel AEC can leverage spatial cues afforded by multiple microphones to achieve better performance. Existing multi-channel AEC approaches typically combine beamforming with deep neural networks (DNN). This work proposes a two-stage algorithm that enhances multi-channel AEC by incorporating sound source directional cues. Specifically, a lightweight DNN is first trained to predict the sound source directions, and then the predicted directional information, multi-channel microphone signals, and single-channel far-end signal are jointly fed into an AEC network to estimate the near-end signal. Evaluation results show that the proposed algorithm outperforms baseline approaches and exhibits robust generalization across diverse acoustic environments.
Room Impulse Response as a Prompt for Acoustic Echo Cancellation
May 26, 2025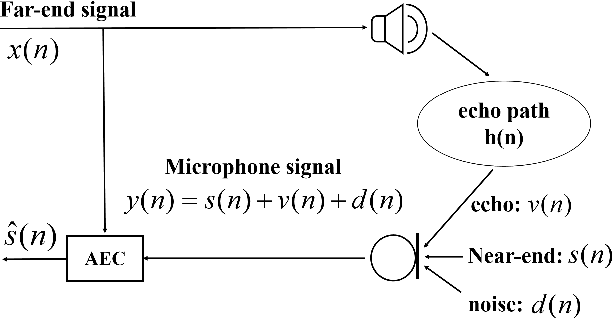
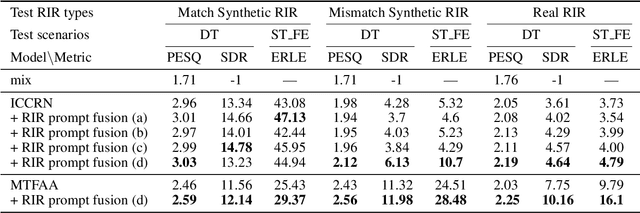
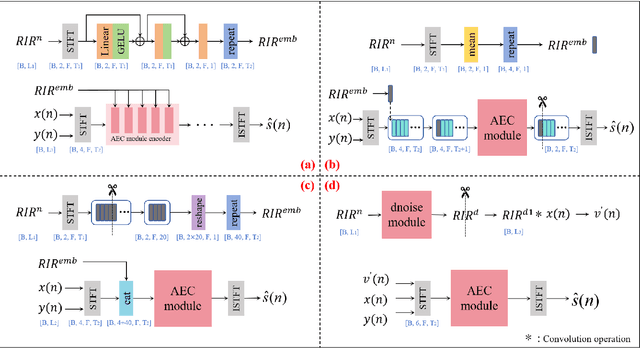
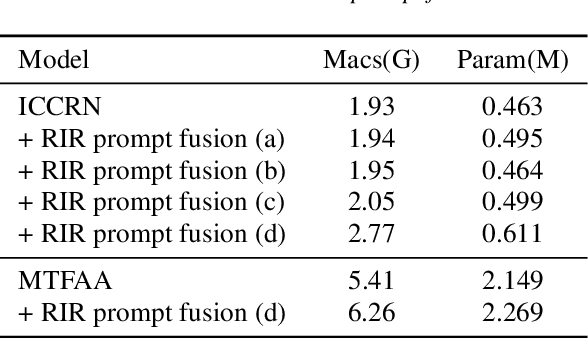
Data-driven acoustic echo cancellation (AEC) methods, predominantly trained on synthetic or constrained real-world datasets, encounter performance declines in unseen echo scenarios, especially in real environments where echo paths are not directly observable. Our proposed method counters this limitation by integrating room impulse response (RIR) as a pivotal training prompt, aiming to improve the generalization of AEC models in such unforeseen conditions. We also explore four RIR prompt fusion methods. Comprehensive evaluations, including both simulated RIR under unknown conditions and recorded RIR in real, demonstrate that the proposed approach significantly improves performance compared to baseline models. These results substantiate the effectiveness of our RIR-guided approach in strengthening the model's generalization capabilities.
Temporal-Spectral-Spatial Unified Remote Sensing Dense Prediction
May 18, 2025The proliferation of diverse remote sensing data has spurred advancements in dense prediction tasks, yet significant challenges remain in handling data heterogeneity. Remote sensing imagery exhibits substantial variability across temporal, spectral, and spatial (TSS) dimensions, complicating unified data processing. Current deep learning models for dense prediction tasks, such as semantic segmentation and change detection, are typically tailored to specific input-output configurations. Consequently, variations in data dimensionality or task requirements often lead to significant performance degradation or model incompatibility, necessitating costly retraining or fine-tuning efforts for different application scenarios. This paper introduces the Temporal-Spectral-Spatial Unified Network (TSSUN), a novel architecture designed for unified representation and modeling of remote sensing data across diverse TSS characteristics and task types. TSSUN employs a Temporal-Spectral-Spatial Unified Strategy that leverages meta-information to decouple and standardize input representations from varied temporal, spectral, and spatial configurations, and similarly unifies output structures for different dense prediction tasks and class numbers. Furthermore, a Local-Global Window Attention mechanism is proposed to efficiently capture both local contextual details and global dependencies, enhancing the model's adaptability and feature extraction capabilities. Extensive experiments on multiple datasets demonstrate that a single TSSUN model effectively adapts to heterogeneous inputs and unifies various dense prediction tasks. The proposed approach consistently achieves or surpasses state-of-the-art performance, highlighting its robustness and generalizability for complex remote sensing applications without requiring task-specific modifications.
Listen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025



We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.
Transforming Weather Data from Pixel to Latent Space
Mar 09, 2025The increasing impact of climate change and extreme weather events has spurred growing interest in deep learning for weather research. However, existing studies often rely on weather data in pixel space, which presents several challenges such as smooth outputs in model outputs, limited applicability to a single pressure-variable subset (PVS), and high data storage and computational costs. To address these challenges, we propose a novel Weather Latent Autoencoder (WLA) that transforms weather data from pixel space to latent space, enabling efficient weather task modeling. By decoupling weather reconstruction from downstream tasks, WLA improves the accuracy and sharpness of weather task model results. The incorporated Pressure-Variable Unified Module transforms multiple PVS into a unified representation, enhancing the adaptability of the model in multiple weather scenarios. Furthermore, weather tasks can be performed in a low-storage latent space of WLA rather than a high-storage pixel space, thus significantly reducing data storage and computational costs. Through extensive experimentation, we demonstrate its superior compression and reconstruction performance, enabling the creation of the ERA5-latent dataset with unified representations of multiple PVS from ERA5 data. The compressed full PVS in the ERA5-latent dataset reduces the original 244.34 TB of data to 0.43 TB. The downstream task further demonstrates that task models can apply to multiple PVS with low data costs in latent space and achieve superior performance compared to models in pixel space. Code, ERA5-latent data, and pre-trained models are available at https://anonymous.4open.science/r/Weather-Latent-Autoencoder-8467.