 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
Feb 19, 2025Recent success in large multimodal models (LMMs) has sparked promising applications of agents capable of autonomously completing complex web tasks. While open-source LMM agents have made significant advances in offline evaluation benchmarks, their performance still falls substantially short of human-level capabilities in more realistic online settings. A key bottleneck is the lack of diverse and large-scale trajectory-level datasets across various domains, which are expensive to collect. In this paper, we address this challenge by developing a scalable recipe to synthesize the largest and most diverse trajectory-level dataset to date, containing over 94K successful multimodal web trajectories, spanning 49K unique URLs, 720K screenshots, and 33M web elements. In particular, we leverage extensive web exploration and refinement to obtain diverse task intents. The average cost is 28 cents per successful trajectory, making it affordable to a wide range of users in the community. Leveraging this dataset, we train Explorer, a multimodal web agent, and demonstrate strong performance on both offline and online web agent benchmarks such as Mind2Web-Live, Multimodal-Mind2Web, and MiniWob++. Additionally, our experiments highlight data scaling as a key driver for improving web agent capabilities. We hope this study makes state-of-the-art LMM-based agent research at a larger scale more accessible.
StreamAdapter: Efficient Test Time Adaptation from Contextual Streams
Nov 14, 2024



In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks directly from the given demonstrations without requiring gradient updates. While recent advances have expanded context windows to accommodate more demonstrations, this approach increases inference costs without necessarily improving performance. To mitigate these issues, We propose StreamAdapter, a novel approach that directly updates model parameters from context at test time, eliminating the need for explicit in-context demonstrations. StreamAdapter employs context mapping and weight absorption mechanisms to dynamically transform ICL demonstrations into parameter updates with minimal additional parameters. By reducing reliance on numerous in-context examples, StreamAdapter significantly reduce inference costs and allows for efficient inference with constant time complexity, regardless of demonstration count. Extensive experiments across diverse tasks and model architectures demonstrate that StreamAdapter achieves comparable or superior adaptation capability to ICL while requiring significantly fewer demonstrations. The superior task adaptation and context encoding capabilities of StreamAdapter on both language understanding and generation tasks provides a new perspective for adapting LLMs at test time using context, allowing for more efficient adaptation across scenarios and more cost-effective inference
Boosting Open-Domain Continual Learning via Leveraging Intra-domain Category-aware Prototype
Aug 19, 2024Despite recent progress in enhancing the efficacy of Open-Domain Continual Learning (ODCL) in Vision-Language Models (VLM), failing to (1) correctly identify the Task-ID of a test image and (2) use only the category set corresponding to the Task-ID, while preserving the knowledge related to each domain, cannot address the two primary challenges of ODCL: forgetting old knowledge and maintaining zero-shot capabilities, as well as the confusions caused by category-relatedness between domains. In this paper, we propose a simple yet effective solution: leveraging intra-domain category-aware prototypes for ODCL in CLIP (DPeCLIP), where the prototype is the key to bridging the above two processes. Concretely, we propose a training-free Task-ID discriminator method, by utilizing prototypes as classifiers for identifying Task-IDs. Furthermore, to maintain the knowledge corresponding to each domain, we incorporate intra-domain category-aware prototypes as domain prior prompts into the training process. Extensive experiments conducted on 11 different datasets demonstrate the effectiveness of our approach, achieving 2.37% and 1.14% average improvement in class-incremental and task-incremental settings, respectively.
OmniParser for Pure Vision Based GUI Agent
Aug 01, 2024



The recent success of large vision language models shows great potential in driving the agent system operating on user interfaces. However, we argue that the power multimodal models like GPT-4V as a general agent on multiple operating systems across different applications is largely underestimated due to the lack of a robust screen parsing technique capable of: 1) reliably identifying interactable icons within the user interface, and 2) understanding the semantics of various elements in a screenshot and accurately associate the intended action with the corresponding region on the screen. To fill these gaps, we introduce \textsc{OmniParser}, a comprehensive method for parsing user interface screenshots into structured elements, which significantly enhances the ability of GPT-4V to generate actions that can be accurately grounded in the corresponding regions of the interface. We first curated an interactable icon detection dataset using popular webpages and an icon description dataset. These datasets were utilized to fine-tune specialized models: a detection model to parse interactable regions on the screen and a caption model to extract the functional semantics of the detected elements. \textsc{OmniParser} significantly improves GPT-4V's performance on ScreenSpot benchmark. And on Mind2Web and AITW benchmark, \textsc{OmniParser} with screenshot only input outperforms the GPT-4V baselines requiring additional information outside of screenshot.
AgentInstruct: Toward Generative Teaching with Agentic Flows
Jul 03, 2024



Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns around model collapse and drawbacks of imitating other models. This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data. We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching. We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds. We demonstrate the utility of AgentInstruct by creating a post training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc. The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks. For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
Jun 11, 2024
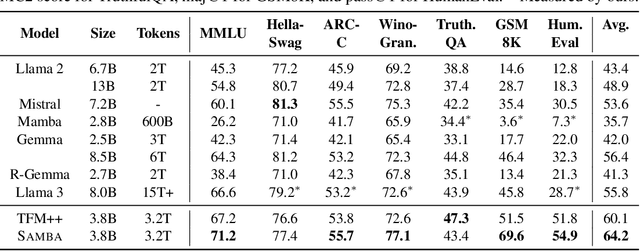

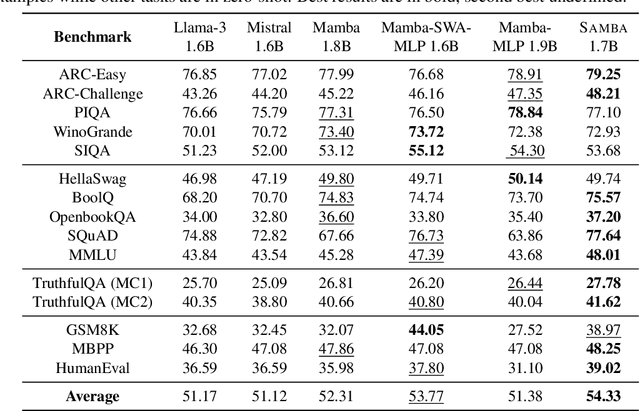
Efficiently modeling sequences with infinite context length has been a long-standing problem. Past works suffer from either the quadratic computation complexity or the limited extrapolation ability on length generalization. In this work, we present Samba, a simple hybrid architecture that layer-wise combines Mamba, a selective State Space Model (SSM), with Sliding Window Attention (SWA). Samba selectively compresses a given sequence into recurrent hidden states while still maintaining the ability to precisely recall memories with the attention mechanism. We scale Samba up to 3.8B parameters with 3.2T training tokens and show that Samba substantially outperforms the state-of-the-art models based on pure attention or SSMs on a wide range of benchmarks. When trained on 4K length sequences, Samba can be efficiently extrapolated to 256K context length with perfect memory recall and show improved token predictions up to 1M context length. As a linear-time sequence model, Samba enjoys a 3.73x higher throughput compared to Transformers with grouped-query attention when processing user prompts of 128K length, and 3.64x speedup when generating 64K tokens with unlimited streaming. A sample implementation of Samba is publicly available in https://github.com/microsoft/Samba.
Multi-LoRA Composition for Image Generation
Feb 26, 2024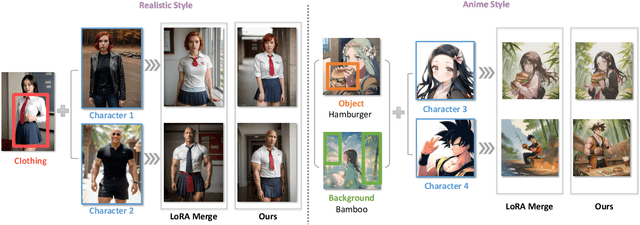

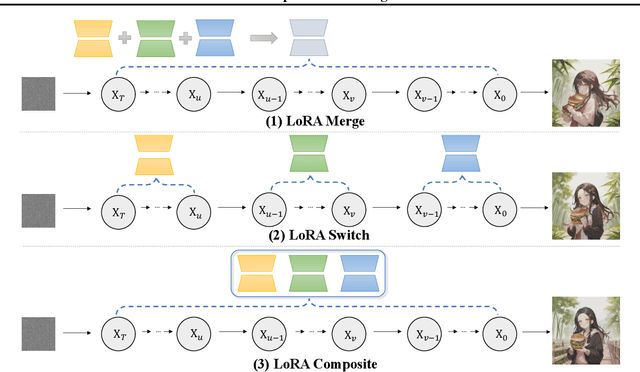
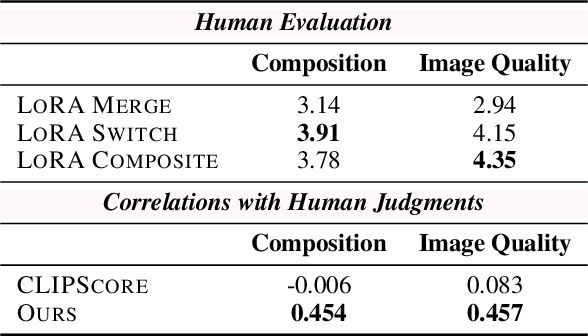
Low-Rank Adaptation (LoRA) is extensively utilized in text-to-image models for the accurate rendition of specific elements like distinct characters or unique styles in generated images. Nonetheless, existing methods face challenges in effectively composing multiple LoRAs, especially as the number of LoRAs to be integrated grows, thus hindering the creation of complex imagery. In this paper, we study multi-LoRA composition through a decoding-centric perspective. We present two training-free methods: LoRA Switch, which alternates between different LoRAs at each denoising step, and LoRA Composite, which simultaneously incorporates all LoRAs to guide more cohesive image synthesis. To evaluate the proposed approaches, we establish ComposLoRA, a new comprehensive testbed as part of this research. It features a diverse range of LoRA categories with 480 composition sets. Utilizing an evaluation framework based on GPT-4V, our findings demonstrate a clear improvement in performance with our methods over the prevalent baseline, particularly evident when increasing the number of LoRAs in a composition.
Causal-CoG: A Causal-Effect Look at Context Generation for Boosting Multi-modal Language Models
Dec 09, 2023



While Multi-modal Language Models (MLMs) demonstrate impressive multimodal ability, they still struggle on providing factual and precise responses for tasks like visual question answering (VQA). In this paper, we address this challenge from the perspective of contextual information. We propose Causal Context Generation, Causal-CoG, which is a prompting strategy that engages contextual information to enhance precise VQA during inference. Specifically, we prompt MLMs to generate contexts, i.e, text description of an image, and engage the generated contexts for question answering. Moreover, we investigate the advantage of contexts on VQA from a causality perspective, introducing causality filtering to select samples for which contextual information is helpful. To show the effectiveness of Causal-CoG, we run extensive experiments on 10 multimodal benchmarks and show consistent improvements, e.g., +6.30% on POPE, +13.69% on Vizwiz and +6.43% on VQAv2 compared to direct decoding, surpassing existing methods. We hope Casual-CoG inspires explorations of context knowledge in multimodal models, and serves as a plug-and-play strategy for MLM decoding.
Adapting LLM Agents Through Communication
Oct 10, 2023



Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Through iterative exploration and PPO training, LTC empowers the agent to assimilate short-term experiences into long-term memory. To optimize agent interactions for task-specific learning, we introduce three structured communication patterns: Monologue, Dialogue, and Analogue-tailored for common tasks such as decision-making, knowledge-intensive reasoning, and numerical reasoning. We evaluated LTC on three datasets: ALFWorld (decision-making), HotpotQA (knowledge-intensive reasoning), and GSM8k (numerical reasoning). On ALFWorld, it exceeds the instruction tuning baseline by 12% in success rate. On HotpotQA, LTC surpasses the instruction-tuned LLaMA-7B agent by 5.1% in EM score, and it outperforms the instruction-tuned 9x larger PaLM-62B agent by 0.6%. On GSM8k, LTC outperforms the CoT-Tuning baseline by 3.6% in accuracy. The results showcase the versatility and efficiency of the LTC approach across diverse domains. We will open-source our code to promote further development of the community.
An Empirical Study of Scaling Instruct-Tuned Large Multimodal Models
Sep 18, 2023Visual instruction tuning has recently shown encouraging progress with open-source large multimodal models (LMM) such as LLaVA and MiniGPT-4. However, most existing studies of open-source LMM are performed using models with 13B parameters or smaller. In this paper we present an empirical study of scaling LLaVA up to 33B and 65B/70B, and share our findings from our explorations in image resolution, data mixing and parameter-efficient training methods such as LoRA/QLoRA. These are evaluated by their impact on the multi-modal and language capabilities when completing real-world tasks in the wild. We find that scaling LMM consistently enhances model performance and improves language capabilities, and performance of LoRA/QLoRA tuning of LMM are comparable to the performance of full-model fine-tuning. Additionally, the study highlights the importance of higher image resolutions and mixing multimodal-language data to improve LMM performance, and visual instruction tuning can sometimes improve LMM's pure language capability. We hope that this study makes state-of-the-art LMM research at a larger scale more accessible, thus helping establish stronger baselines for future research. Code and checkpoints will be made public.