 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiO-DETR: DETR for Real-time Oriented Object Detection
Mar 10, 2026We present RiO-DETR: DETR for Real-time Oriented Object Detection, the first real-time oriented detection transformer to the best of our knowledge. Adapting DETR to oriented bounding boxes (OBBs) poses three challenges: semantics-dependent orientation, angle periodicity that breaks standard Euclidean refinement, and an enlarged search space that slows convergence. RiO-DETR resolves these issues with task-native designs while preserving real-time efficiency. First, we propose Content-Driven Angle Estimation by decoupling angle from positional queries, together with Rotation-Rectified Orthogonal Attention to capture complementary cues for reliable orientation. Second, Decoupled Periodic Refinement combines bounded coarse-to-fine updates with a Shortest-Path Periodic Loss for stable learning across angular seams. Third, Oriented Dense O2O injects angular diversity into dense supervision to speed up angle convergence at no extra cost. Extensive experiments on DOTA-1.0, DIOR-R, and FAIR-1M-2.0 demonstrate RiO-DETR establishes a new speed--accuracy trade-off for real-time oriented detection. Code will be made publicly available.
ReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
Feb 05, 2026Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85\%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1\%} AP on COCO object detection and \textbf{3.6\%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.
Visual Bridge: Universal Visual Perception Representations Generating
Nov 11, 2025Recent advances in diffusion models have achieved remarkable success in isolated computer vision tasks such as text-to-image generation, depth estimation, and optical flow. However, these models are often restricted by a ``single-task-single-model'' paradigm, severely limiting their generalizability and scalability in multi-task scenarios. Motivated by the cross-domain generalization ability of large language models, we propose a universal visual perception framework based on flow matching that can generate diverse visual representations across multiple tasks. Our approach formulates the process as a universal flow-matching problem from image patch tokens to task-specific representations rather than an independent generation or regression problem. By leveraging a strong self-supervised foundation model as the anchor and introducing a multi-scale, circular task embedding mechanism, our method learns a universal velocity field to bridge the gap between heterogeneous tasks, supporting efficient and flexible representation transfer. Extensive experiments on classification, detection, segmentation, depth estimation, and image-text retrieval demonstrate that our model achieves competitive performance in both zero-shot and fine-tuned settings, outperforming prior generalist and several specialist models. Ablation studies further validate the robustness, scalability, and generalization of our framework. Our work marks a significant step towards general-purpose visual perception, providing a solid foundation for future research in universal vision modeling.
Boosting Open-Domain Continual Learning via Leveraging Intra-domain Category-aware Prototype
Aug 19, 2024Despite recent progress in enhancing the efficacy of Open-Domain Continual Learning (ODCL) in Vision-Language Models (VLM), failing to (1) correctly identify the Task-ID of a test image and (2) use only the category set corresponding to the Task-ID, while preserving the knowledge related to each domain, cannot address the two primary challenges of ODCL: forgetting old knowledge and maintaining zero-shot capabilities, as well as the confusions caused by category-relatedness between domains. In this paper, we propose a simple yet effective solution: leveraging intra-domain category-aware prototypes for ODCL in CLIP (DPeCLIP), where the prototype is the key to bridging the above two processes. Concretely, we propose a training-free Task-ID discriminator method, by utilizing prototypes as classifiers for identifying Task-IDs. Furthermore, to maintain the knowledge corresponding to each domain, we incorporate intra-domain category-aware prototypes as domain prior prompts into the training process. Extensive experiments conducted on 11 different datasets demonstrate the effectiveness of our approach, achieving 2.37% and 1.14% average improvement in class-incremental and task-incremental settings, respectively.
Improving Image Restoration through Removing Degradations in Textual Representations
Dec 28, 2023

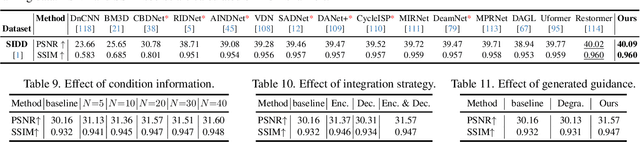
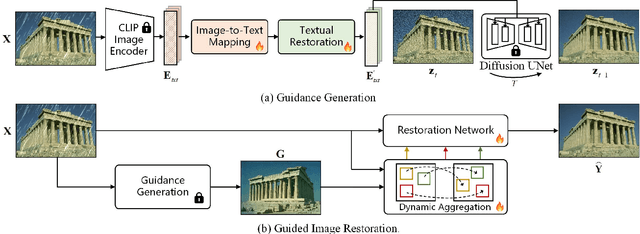
In this paper, we introduce a new perspective for improving image restoration by removing degradation in the textual representations of a given degraded image. Intuitively, restoration is much easier on text modality than image one. For example, it can be easily conducted by removing degradation-related words while keeping the content-aware words. Hence, we combine the advantages of images in detail description and ones of text in degradation removal to perform restoration. To address the cross-modal assistance, we propose to map the degraded images into textual representations for removing the degradations, and then convert the restored textual representations into a guidance image for assisting image restoration. In particular, We ingeniously embed an image-to-text mapper and text restoration module into CLIP-equipped text-to-image models to generate the guidance. Then, we adopt a simple coarse-to-fine approach to dynamically inject multi-scale information from guidance to image restoration networks. Extensive experiments are conducted on various image restoration tasks, including deblurring, dehazing, deraining, and denoising, and all-in-one image restoration. The results showcase that our method outperforms state-of-the-art ones across all these tasks. The codes and models are available at \url{https://github.com/mrluin/TextualDegRemoval}.
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.
From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
Oct 18, 2023Multi-modal Large Language Models (MLLMs) have made significant strides in expanding the capabilities of Large Language Models (LLMs) through the incorporation of visual perception interfaces. Despite the emergence of exciting applications and the availability of diverse instruction tuning data, existing approaches often rely on CLIP or its variants as the visual branch, and merely extract features from the deep layers. However, these methods lack a comprehensive analysis of the visual encoders in MLLMs. In this paper, we conduct an extensive investigation into the effectiveness of different vision encoders within MLLMs. Our findings reveal that the shallow layer features of CLIP offer particular advantages for fine-grained tasks such as grounding and region understanding. Surprisingly, the vision-only model DINO, which is not pretrained with text-image alignment, demonstrates promising performance as a visual branch within MLLMs. By simply equipping it with an MLP layer for alignment, DINO surpasses CLIP in fine-grained related perception tasks. Building upon these observations, we propose a simple yet effective feature merging strategy, named COMM, that integrates CLIP and DINO with Multi-level features Merging, to enhance the visual capabilities of MLLMs. We evaluate COMM through comprehensive experiments on a wide range of benchmarks, including image captioning, visual question answering, visual grounding, and object hallucination. Experimental results demonstrate the superior performance of COMM compared to existing methods, showcasing its enhanced visual capabilities within MLLMs. Code will be made available at https://github.com/YuchenLiu98/COMM.
ControlVideo: Training-free Controllable Text-to-Video Generation
May 22, 2023Text-driven diffusion models have unlocked unprecedented abilities in image generation, whereas their video counterpart still lags behind due to the excessive training cost of temporal modeling. Besides the training burden, the generated videos also suffer from appearance inconsistency and structural flickers, especially in long video synthesis. To address these challenges, we design a \emph{training-free} framework called \textbf{ControlVideo} to enable natural and efficient text-to-video generation. ControlVideo, adapted from ControlNet, leverages coarsely structural consistency from input motion sequences, and introduces three modules to improve video generation. Firstly, to ensure appearance coherence between frames, ControlVideo adds fully cross-frame interaction in self-attention modules. Secondly, to mitigate the flicker effect, it introduces an interleaved-frame smoother that employs frame interpolation on alternated frames. Finally, to produce long videos efficiently, it utilizes a hierarchical sampler that separately synthesizes each short clip with holistic coherency. Empowered with these modules, ControlVideo outperforms the state-of-the-arts on extensive motion-prompt pairs quantitatively and qualitatively. Notably, thanks to the efficient designs, it generates both short and long videos within several minutes using one NVIDIA 2080Ti. Code is available at https://github.com/YBYBZhang/ControlVideo.
Segment Anything in 3D with NeRFs
Apr 26, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
USAGE: A Unified Seed Area Generation Paradigm for Weakly Supervised Semantic Segmentation
Mar 14, 2023
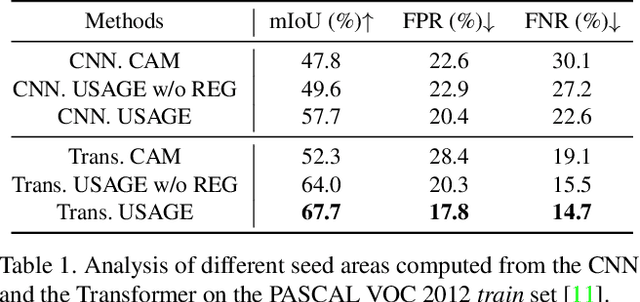
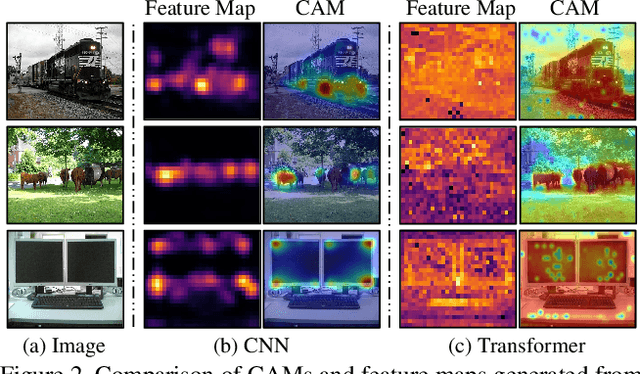
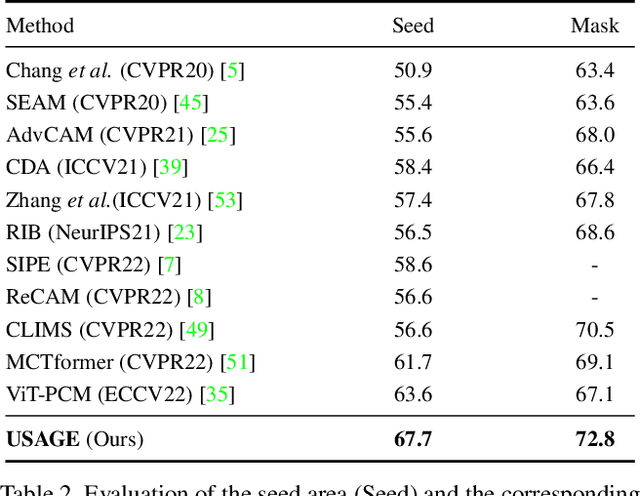
Seed area generation is usually the starting point of weakly supervised semantic segmentation (WSSS). Computing the Class Activation Map (CAM) from a multi-label classification network is the de facto paradigm for seed area generation, but CAMs generated from Convolutional Neural Networks (CNNs) and Transformers are prone to be under- and over-activated, respectively, which makes the strategies to refine CAMs for CNNs usually inappropriate for Transformers, and vice versa. In this paper, we propose a Unified optimization paradigm for Seed Area GEneration (USAGE) for both types of networks, in which the objective function to be optimized consists of two terms: One is a generation loss, which controls the shape of seed areas by a temperature parameter following a deterministic principle for different types of networks; The other is a regularization loss, which ensures the consistency between the seed areas that are generated by self-adaptive network adjustment from different views, to overturn false activation in seed areas. Experimental results show that USAGE consistently improves seed area generation for both CNNs and Transformers by large margins, e.g., outperforming state-of-the-art methods by a mIoU of 4.1% on PASCAL VOC. Moreover, based on the USAGE-generated seed areas on Transformers, we achieve state-of-the-art WSSS results on both PASCAL VOC and MS COCO.