 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSdAE: Self-distillated Masked Autoencoder
Paper and Code
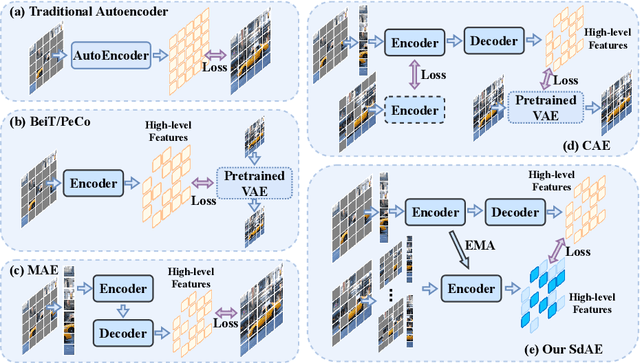

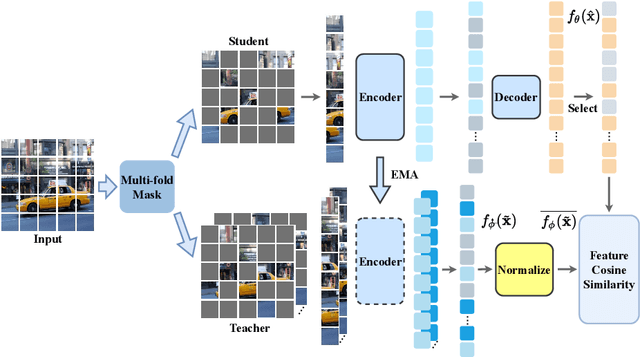
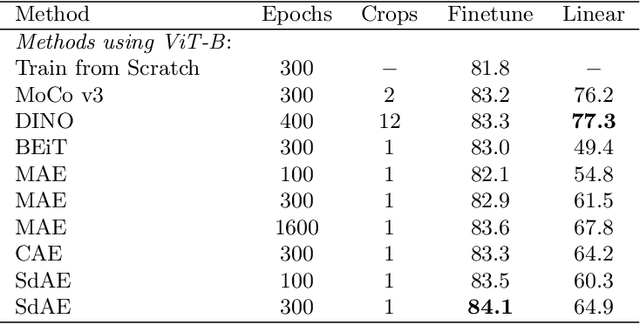
With the development of generative-based self-supervised learning (SSL) approaches like BeiT and MAE, how to learn good representations by masking random patches of the input image and reconstructing the missing information has grown in concern. However, BeiT and PeCo need a "pre-pretraining" stage to produce discrete codebooks for masked patches representing. MAE does not require a pre-training codebook process, but setting pixels as reconstruction targets may introduce an optimization gap between pre-training and downstream tasks that good reconstruction quality may not always lead to the high descriptive capability for the model. Considering the above issues, in this paper, we propose a simple Self-distillated masked AutoEncoder network, namely SdAE. SdAE consists of a student branch using an encoder-decoder structure to reconstruct the missing information, and a teacher branch producing latent representation of masked tokens. We also analyze how to build good views for the teacher branch to produce latent representation from the perspective of information bottleneck. After that, we propose a multi-fold masking strategy to provide multiple masked views with balanced information for boosting the performance, which can also reduce the computational complexity. Our approach generalizes well: with only 300 epochs pre-training, a vanilla ViT-Base model achieves an 84.1% fine-tuning accuracy on ImageNet-1k classification, 48.6 mIOU on ADE20K segmentation, and 48.9 mAP on COCO detection, which surpasses other methods by a considerable margin. Code is available at https://github.com/AbrahamYabo/SdAE.