 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWeave: Unlocking Geometric Consistency in Video Generation via Joint Geometry-Video Modeling
Jun 12, 2026Large-scale video diffusion models often fail to preserve 3D structure over time, causing geometric drift and implausible motion under viewpoint changes. Existing methods usually enforce geometric consistency by using explicit geometry reconstructions, such as depth maps, point clouds, or reconstructed 3D structures, to define conditions, supervision, or reward signals, making the generator sensitive to errors from upstream geometry pipelines. We propose VideoWeave, a latent-space post-training framework that uses implicit geometry-model features to constrain the generative distribution, providing a more flexible and non-rigid form of guidance that mitigates the impact of reconstruction errors from geometry models. Specifically, VideoWeave adapts these features into geometry latents and jointly models them with video latents in a shared denoising space, allowing geometry to shape the generative distribution during training. To support this process, we build GeoVid-80K, an 80K-video dataset with paired appearance and geometry representations. Experiments on text-to-video and image-to-video generation show that VideoWeave improves geometric coherence while preserving strong visual quality. VideoWeave project page at https://videoweave.github.io/
Full-4D: Generating Full-Scope 4D Scenes from a Single-View Video
May 25, 2026Generating 4D scenes from a single-view video is inherently ill-posed: a single viewpoint lacks the information needed to recover a complete, dynamic scene with full coverage. Existing methods are typically limited to monocular videos, simple 3D effects, or only small viewpoint perturbations around the original viewpoint, falling short of true 4D generation. Meanwhile, the lack of large-scale datasets capturing full-scope 4D scenes with synchronized multi-view videos further hinders progress in this direction. We propose a novel single-view video-to-4D framework that casts full-scope 4D generation as a multi-view video synthesis followed by optimization-based 4D reconstruction from the generated views. To instantiate this formulation end-to-end, we make three key contributions. First, we introduce Real-MV-4D, a large-scale dataset of synchronized multi-view videos captured in diverse real-world environments to provide the 4D supervision. Second, we train a multi-view video diffusion model driven by a novel fused time(T)-view(V) attention mechanism that directly embeds geometric reprojection priors and explicit camera conditioning into its view-time interactions. Unlike basic feature fusion, this direct binding strictly aligns the generation process with physical 3D priors to produce a dense, synchronized T$\times $V video grid. Third, rather than relying on non-interactive and inconsistent 2D video interpolations, we lift the synthesized multi-view videos into an explicit 4D representation (i.e. 4DGS), regularized by a Flow Matching Distillation loss that exploits the multi-view prior to improve novel-view rendering. Extensive experiments demonstrate that our method outperforms existing approaches in both visual fidelity and geometric consistency, enabling full-scope 4D scene generation from single-view videos.
TelePhysics: Physics-Grounded Multi-Object Scene Generation from a Single Image with Real-Time Interaction
May 19, 2026Recent generative video models achieve impressive visual quality but remain constrained by limited physical consistency and controllability. Existing video generation methods provide minimal physical control, and single-image-to-3D conversion approaches often suffer from object interpenetration. Furthermore, physics-based scene-level 3D generation methods exhibit spatial misalignment, stylized artifacts, and inconsistencies with the input data, restricting their use in realistic interactive video synthesis. We propose TelePhysics, a training-free framework that converts a single image into a physically consistent and controllable video through holistic scene-level 3D reconstruction. By representing the full scene geometry in a unified spatial coordinate system, TelePhysics resolves object penetration and alignment ambiguity. Unlike prior methods, this formulation enables accurate scenelevel multi-object interactions and introduces richer, complex control types for advanced mechanicsbased manipulation. By decoupling simulation from rendering, TelePhysics bypasses latency-heavy priors, achieving real-time physical interaction previews paired while preserving photorealistic visual fidelity. Experimental results demonstrate that TelePhysics substantially outperforms prior methods in physical fidelity, spatial coherence, and controllability. The open-source code is available at https://github.com/xinzhang007/TelePhysics.
SymphoMotion: Joint Control of Camera Motion and Object Dynamics for Coherent Video Generation
Apr 04, 2026Controlling both camera motion and object dynamics is essential for coherent and expressive video generation, yet current methods typically handle only one motion type or rely on ambiguous 2D cues that entangle camera-induced parallax with true object movement. We present SymphoMotion, a unified motion-control framework that jointly governs camera trajectories and object dynamics within a single model. SymphoMotion features a Camera Trajectory Control mechanism that integrates explicit camera paths with geometry-aware cues to ensure stable, structurally consistent viewpoint transitions, and an Object Dynamics Control mechanism that combines 2D visual guidance with 3D trajectory embeddings to enable depth-aware, spatially coherent object manipulation. To support large-scale training and evaluation, we further construct RealCOD-25K, a comprehensive real-world dataset containing paired camera poses and object-level 3D trajectories across diverse indoor and outdoor scenes, addressing a key data gap in unified motion control. Extensive experiments and user studies show that SymphoMotion significantly outperforms existing methods in visual fidelity, camera controllability, and object-motion accuracy, establishing a new benchmark for unified motion control in video generation.Codes and data are publicly available at https://grenoble-zhang.github.io/SymphoMotion/.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Denoising Vision Transformer Autoencoder with Spectral Self-Regularization
Nov 16, 2025Variational autoencoders (VAEs) typically encode images into a compact latent space, reducing computational cost but introducing an optimization dilemma: a higher-dimensional latent space improves reconstruction fidelity but often hampers generative performance. Recent methods attempt to address this dilemma by regularizing high-dimensional latent spaces using external vision foundation models (VFMs). However, it remains unclear how high-dimensional VAE latents affect the optimization of generative models. To our knowledge, our analysis is the first to reveal that redundant high-frequency components in high-dimensional latent spaces hinder the training convergence of diffusion models and, consequently, degrade generation quality. To alleviate this problem, we propose a spectral self-regularization strategy to suppress redundant high-frequency noise while simultaneously preserving reconstruction quality. The resulting Denoising-VAE, a ViT-based autoencoder that does not rely on VFMs, produces cleaner, lower-noise latents, leading to improved generative quality and faster optimization convergence. We further introduce a spectral alignment strategy to facilitate the optimization of Denoising-VAE-based generative models. Our complete method enables diffusion models to converge approximately 2$\times$ faster than with SD-VAE, while achieving state-of-the-art reconstruction quality (rFID = 0.28, PSNR = 27.26) and competitive generation performance (gFID = 1.82) on the ImageNet 256$\times$256 benchmark.
Metric-Solver: Sliding Anchored Metric Depth Estimation from a Single Image
Apr 16, 2025Accurate and generalizable metric depth estimation is crucial for various computer vision applications but remains challenging due to the diverse depth scales encountered in indoor and outdoor environments. In this paper, we introduce Metric-Solver, a novel sliding anchor-based metric depth estimation method that dynamically adapts to varying scene scales. Our approach leverages an anchor-based representation, where a reference depth serves as an anchor to separate and normalize the scene depth into two components: scaled near-field depth and tapered far-field depth. The anchor acts as a normalization factor, enabling the near-field depth to be normalized within a consistent range while mapping far-field depth smoothly toward zero. Through this approach, any depth from zero to infinity in the scene can be represented within a unified representation, effectively eliminating the need to manually account for scene scale variations. More importantly, for the same scene, the anchor can slide along the depth axis, dynamically adjusting to different depth scales. A smaller anchor provides higher resolution in the near-field, improving depth precision for closer objects while a larger anchor improves depth estimation in far regions. This adaptability enables the model to handle depth predictions at varying distances and ensure strong generalization across datasets. Our design enables a unified and adaptive depth representation across diverse environments. Extensive experiments demonstrate that Metric-Solver outperforms existing methods in both accuracy and cross-dataset generalization.
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Dec 12, 2024



Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs' generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.
Cascade-Zero123: One Image to Highly Consistent 3D with Self-Prompted Nearby Views
Dec 07, 2023



Synthesizing multi-view 3D from one single image is a significant and challenging task. For this goal, Zero-1-to-3 methods aim to extend a 2D latent diffusion model to the 3D scope. These approaches generate the target-view image with a single-view source image and the camera pose as condition information. However, the one-to-one manner adopted in Zero-1-to-3 incurs challenges for building geometric and visual consistency across views, especially for complex objects. We propose a cascade generation framework constructed with two Zero-1-to-3 models, named Cascade-Zero123, to tackle this issue, which progressively extracts 3D information from the source image. Specifically, a self-prompting mechanism is designed to generate several nearby views at first. These views are then fed into the second-stage model along with the source image as generation conditions. With self-prompted multiple views as the supplementary information, our Cascade-Zero123 generates more highly consistent novel-view images than Zero-1-to-3. The promotion is significant for various complex and challenging scenes, involving insects, humans, transparent objects, and stacked multiple objects etc. The project page is at https://cascadezero123.github.io/.
Motion-inductive Self-supervised Object Discovery in Videos
Oct 01, 2022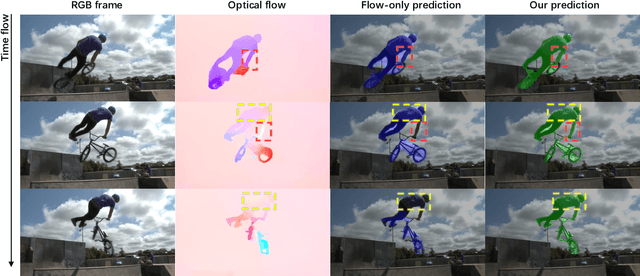
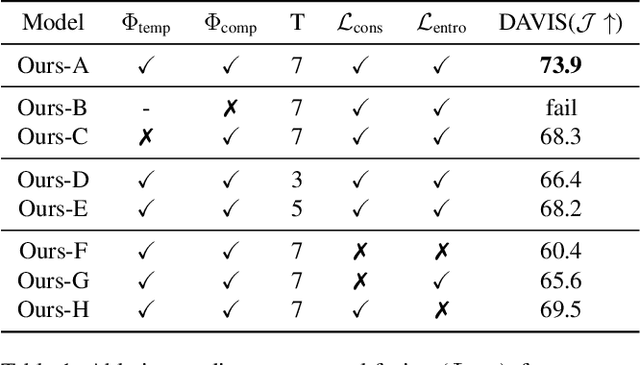
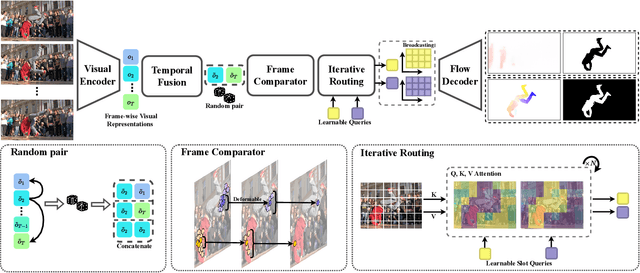
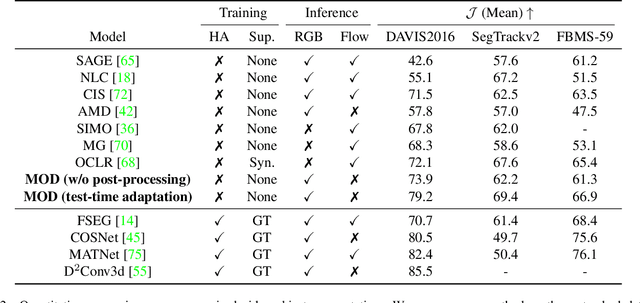
In this paper, we consider the task of unsupervised object discovery in videos. Previous works have shown promising results via processing optical flows to segment objects. However, taking flow as input brings about two drawbacks. First, flow cannot capture sufficient cues when objects remain static or partially occluded. Second, it is challenging to establish temporal coherency from flow-only input, due to the missing texture information. To tackle these limitations, we propose a model for directly processing consecutive RGB frames, and infer the optical flow between any pair of frames using a layered representation, with the opacity channels being treated as the segmentation. Additionally, to enforce object permanence, we apply temporal consistency loss on the inferred masks from randomly-paired frames, which refer to the motions at different paces, and encourage the model to segment the objects even if they may not move at the current time point. Experimentally, we demonstrate superior performance over previous state-of-the-art methods on three public video segmentation datasets (DAVIS2016, SegTrackv2, and FBMS-59), while being computationally efficient by avoiding the overhead of computing optical flow as input.