 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterophilic Graph Neural Networks Optimization with Causal Message-passing
Nov 21, 2024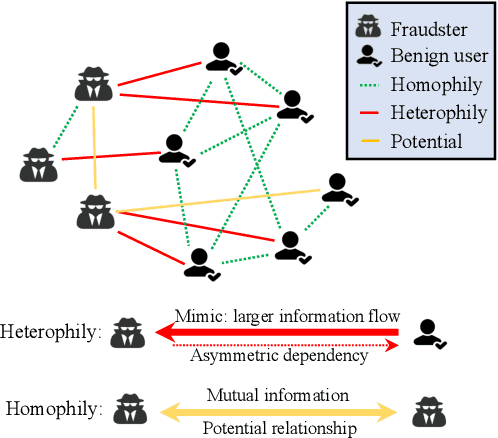
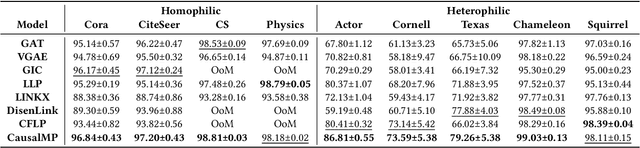
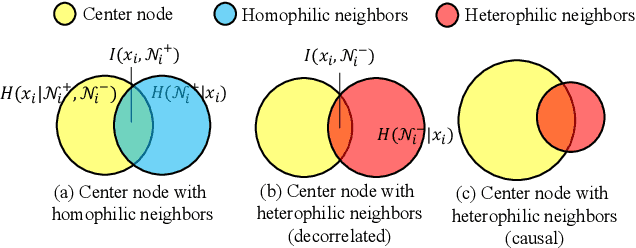
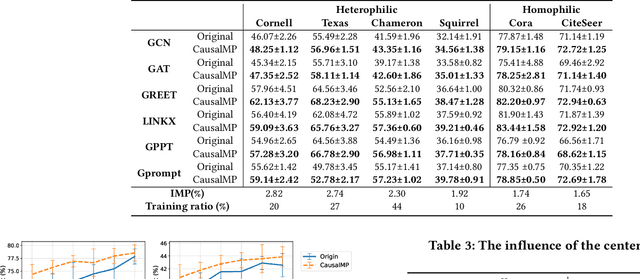
In this work, we discover that causal inference provides a promising approach to capture heterophilic message-passing in Graph Neural Network (GNN). By leveraging cause-effect analysis, we can discern heterophilic edges based on asymmetric node dependency. The learned causal structure offers more accurate relationships among nodes. To reduce the computational complexity, we introduce intervention-based causal inference in graph learning. We first simplify causal analysis on graphs by formulating it as a structural learning model and define the optimization problem within the Bayesian scheme. We then present an analysis of decomposing the optimization target into a consistency penalty and a structure modification based on cause-effect relations. We then estimate this target by conditional entropy and present insights into how conditional entropy quantifies the heterophily. Accordingly, we propose CausalMP, a causal message-passing discovery network for heterophilic graph learning, that iteratively learns the explicit causal structure of input graphs. We conduct extensive experiments in both heterophilic and homophilic graph settings. The result demonstrates that the our model achieves superior link prediction performance. Training on causal structure can also enhance node representation in classification task across different base models.
Deep Insights into Noisy Pseudo Labeling on Graph Data
Oct 02, 2023



Pseudo labeling (PL) is a wide-applied strategy to enlarge the labeled dataset by self-annotating the potential samples during the training process. Several works have shown that it can improve the graph learning model performance in general. However, we notice that the incorrect labels can be fatal to the graph training process. Inappropriate PL may result in the performance degrading, especially on graph data where the noise can propagate. Surprisingly, the corresponding error is seldom theoretically analyzed in the literature. In this paper, we aim to give deep insights of PL on graph learning models. We first present the error analysis of PL strategy by showing that the error is bounded by the confidence of PL threshold and consistency of multi-view prediction. Then, we theoretically illustrate the effect of PL on convergence property. Based on the analysis, we propose a cautious pseudo labeling methodology in which we pseudo label the samples with highest confidence and multi-view consistency. Finally, extensive experiments demonstrate that the proposed strategy improves graph learning process and outperforms other PL strategies on link prediction and node classification tasks.
Pose-Oriented Transformer with Uncertainty-Guided Refinement for 2D-to-3D Human Pose Estimation
Feb 15, 2023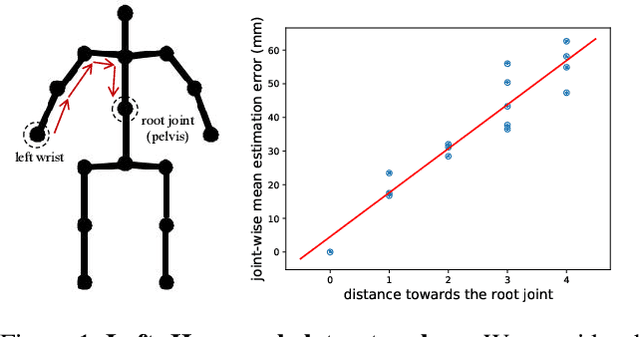



There has been a recent surge of interest in introducing transformers to 3D human pose estimation (HPE) due to their powerful capabilities in modeling long-term dependencies. However, existing transformer-based methods treat body joints as equally important inputs and ignore the prior knowledge of human skeleton topology in the self-attention mechanism. To tackle this issue, in this paper, we propose a Pose-Oriented Transformer (POT) with uncertainty guided refinement for 3D HPE. Specifically, we first develop novel pose-oriented self-attention mechanism and distance-related position embedding for POT to explicitly exploit the human skeleton topology. The pose-oriented self-attention mechanism explicitly models the topological interactions between body joints, whereas the distance-related position embedding encodes the distance of joints to the root joint to distinguish groups of joints with different difficulties in regression. Furthermore, we present an Uncertainty-Guided Refinement Network (UGRN) to refine pose predictions from POT, especially for the difficult joints, by considering the estimated uncertainty of each joint with uncertainty-guided sampling strategy and self-attention mechanism. Extensive experiments demonstrate that our method significantly outperforms the state-of-the-art methods with reduced model parameters on 3D HPE benchmarks such as Human3.6M and MPI-INF-3DHP
Hierarchical Graph Networks for 3D Human Pose Estimation
Nov 23, 2021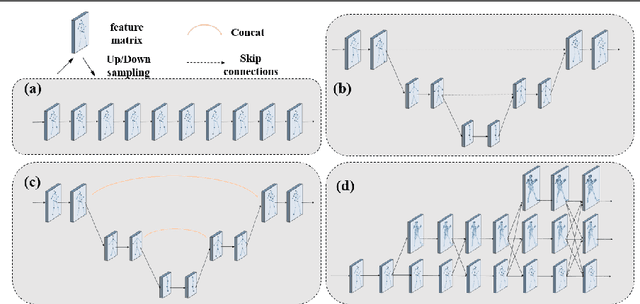

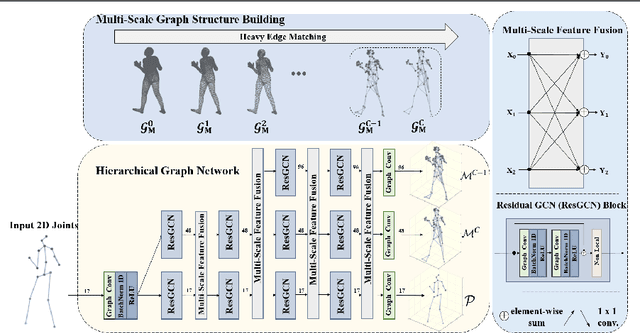
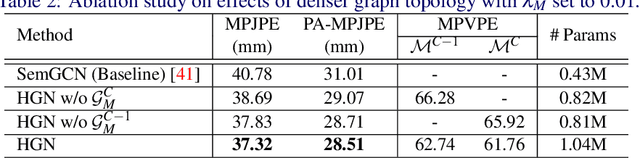
Recent 2D-to-3D human pose estimation works tend to utilize the graph structure formed by the topology of the human skeleton. However, we argue that this skeletal topology is too sparse to reflect the body structure and suffer from serious 2D-to-3D ambiguity problem. To overcome these weaknesses, we propose a novel graph convolution network architecture, Hierarchical Graph Networks (HGN). It is based on denser graph topology generated by our multi-scale graph structure building strategy, thus providing more delicate geometric information. The proposed architecture contains three sparse-to-fine representation subnetworks organized in parallel, in which multi-scale graph-structured features are processed and exchange information through a novel feature fusion strategy, leading to rich hierarchical representations. We also introduce a 3D coarse mesh constraint to further boost detail-related feature learning. Extensive experiments demonstrate that our HGN achieves the state-of-the art performance with reduced network parameters
TRP: Trained Rank Pruning for Efficient Deep Neural Networks
Apr 30, 2020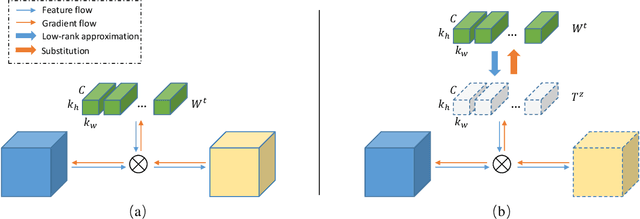
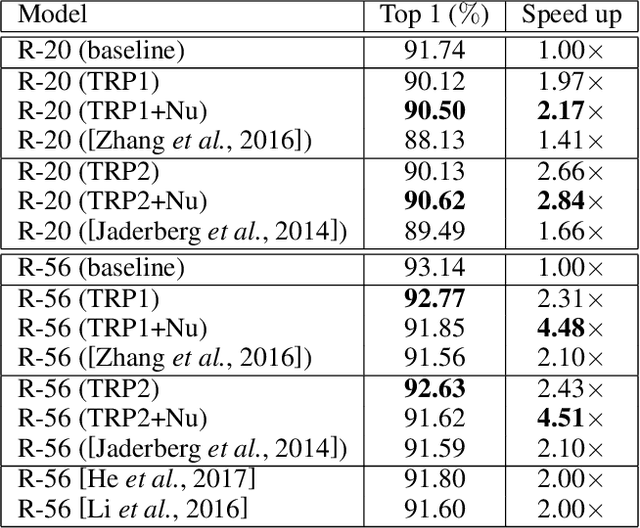
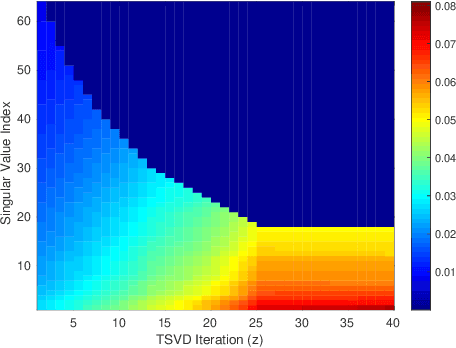
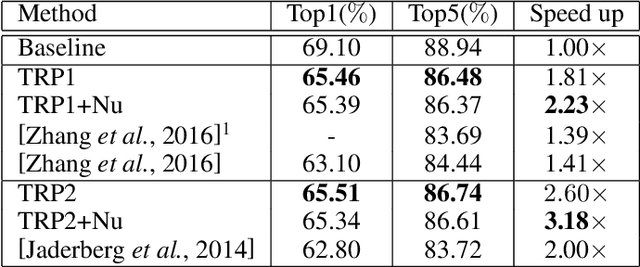
To enable DNNs on edge devices like mobile phones, low-rank approximation has been widely adopted because of its solid theoretical rationale and efficient implementations. Several previous works attempted to directly approximate a pretrained model by low-rank decomposition; however, small approximation errors in parameters can ripple over a large prediction loss. As a result, performance usually drops significantly and a sophisticated effort on fine-tuning is required to recover accuracy. Apparently, it is not optimal to separate low-rank approximation from training. Unlike previous works, this paper integrates low rank approximation and regularization into the training process. We propose Trained Rank Pruning (TRP), which alternates between low rank approximation and training. TRP maintains the capacity of the original network while imposing low-rank constraints during training. A nuclear regularization optimized by stochastic sub-gradient descent is utilized to further promote low rank in TRP. The TRP trained network inherently has a low-rank structure, and is approximated with negligible performance loss, thus eliminating the fine-tuning process after low rank decomposition. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet, outperforming previous compression methods using low rank approximation.
Trained Rank Pruning for Efficient Deep Neural Networks
Oct 11, 2019
To accelerate DNNs inference, low-rank approximation has been widely adopted because of its solid theoretical rationale and efficient implementations. Several previous works attempted to directly approximate a pre-trained model by low-rank decomposition; however, small approximation errors in parameters can ripple over a large prediction loss. Apparently, it is not optimal to separate low-rank approximation from training. Unlike previous works, this paper integrates low rank approximation and regularization into the training process. We propose Trained Rank Pruning (TRP), which alternates between low rank approximation and training. TRP maintains the capacity of the original network while imposing low-rank constraints during training. A nuclear regularization optimized by stochastic sub-gradient descent is utilized to further promote low rank in TRP. Networks trained with TRP has a low-rank structure in nature, and is approximated with negligible performance loss, thus eliminating fine-tuning after low rank approximation. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet, outperforming previous compression counterparts using low rank approximation. Our code is available at: https://github.com/yuhuixu1993/Trained-Rank-Pruning.