 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRestorer: Universal Image Restoration via Adaptively Estimating Image Degradation at Proper Granularity
Dec 28, 2024



Recently, considerable progress has been made in allin-one image restoration. Generally, existing methods can be degradation-agnostic or degradation-aware. However, the former are limited in leveraging degradation-specific restoration, and the latter suffer from the inevitable error in degradation estimation. Consequently, the performance of existing methods has a large gap compared to specific single-task models. In this work, we make a step forward in this topic, and present our UniRestorer with improved restoration performance. Specifically, we perform hierarchical clustering on degradation space, and train a multi-granularity mixture-of-experts (MoE) restoration model. Then, UniRestorer adopts both degradation and granularity estimation to adaptively select an appropriate expert for image restoration. In contrast to existing degradation-agnostic and -aware methods, UniRestorer can leverage degradation estimation to benefit degradationspecific restoration, and use granularity estimation to make the model robust to degradation estimation error. Experimental results show that our UniRestorer outperforms stateof-the-art all-in-one methods by a large margin, and is promising in closing the performance gap to specific single task models. The code and pre-trained models will be publicly available at https://github.com/mrluin/UniRestorer.
Improving Image Restoration through Removing Degradations in Textual Representations
Dec 28, 2023

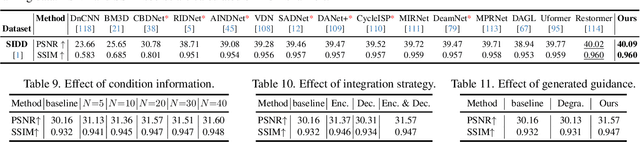
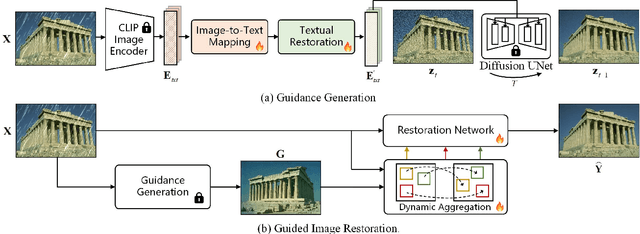
In this paper, we introduce a new perspective for improving image restoration by removing degradation in the textual representations of a given degraded image. Intuitively, restoration is much easier on text modality than image one. For example, it can be easily conducted by removing degradation-related words while keeping the content-aware words. Hence, we combine the advantages of images in detail description and ones of text in degradation removal to perform restoration. To address the cross-modal assistance, we propose to map the degraded images into textual representations for removing the degradations, and then convert the restored textual representations into a guidance image for assisting image restoration. In particular, We ingeniously embed an image-to-text mapper and text restoration module into CLIP-equipped text-to-image models to generate the guidance. Then, we adopt a simple coarse-to-fine approach to dynamically inject multi-scale information from guidance to image restoration networks. Extensive experiments are conducted on various image restoration tasks, including deblurring, dehazing, deraining, and denoising, and all-in-one image restoration. The results showcase that our method outperforms state-of-the-art ones across all these tasks. The codes and models are available at \url{https://github.com/mrluin/TextualDegRemoval}.
SAN: Scale-Aware Network for Semantic Segmentation of High-Resolution Aerial Images
Jul 06, 2019
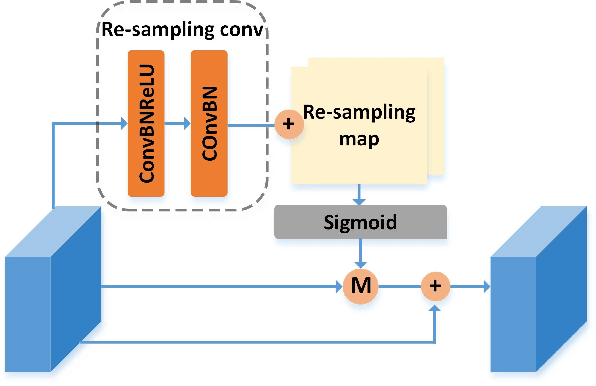
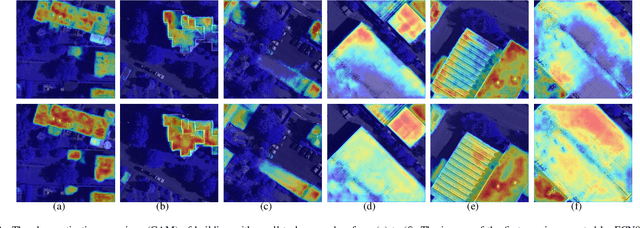

High-resolution aerial images have a wide range of applications, such as military exploration, and urban planning. Semantic segmentation is a fundamental method extensively used in the analysis of high-resolution aerial images. However, the ground objects in high-resolution aerial images have the characteristics of inconsistent scales, and this feature usually leads to unexpected predictions. To tackle this issue, we propose a novel scale-aware module (SAM). In SAM, we employ the re-sampling method aimed to make pixels adjust their positions to fit the ground objects with different scales, and it implicitly introduces spatial attention by employing a re-sampling map as the weighted map. As a result, the network with the proposed module named scale-aware network (SANet) has a stronger ability to distinguish the ground objects with inconsistent scale. Other than this, our proposed modules can easily embed in most of the existing network to improve their performance. We evaluate our modules on the International Society for Photogrammetry and Remote Sensing Vaihingen Dataset, and the experimental results and comprehensive analysis demonstrate the effectiveness of our proposed module.
ESFNet: Efficient Network for Building Extraction from High-Resolution Aerial Images
Apr 19, 2019
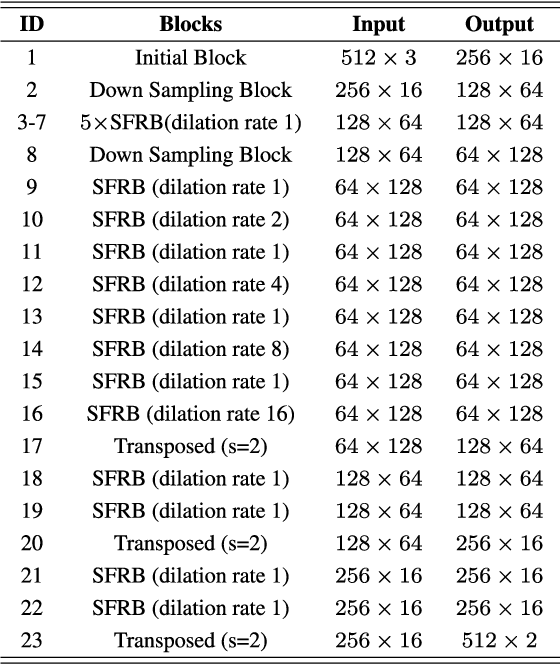
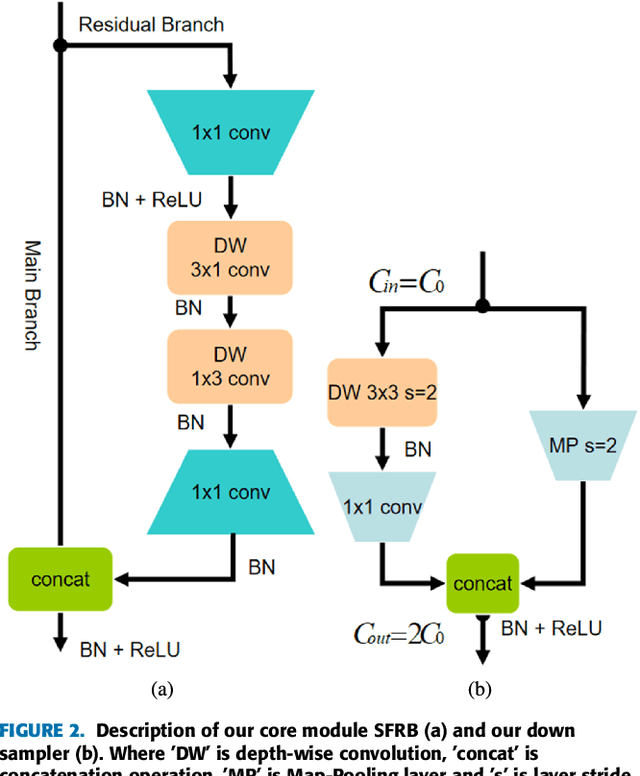
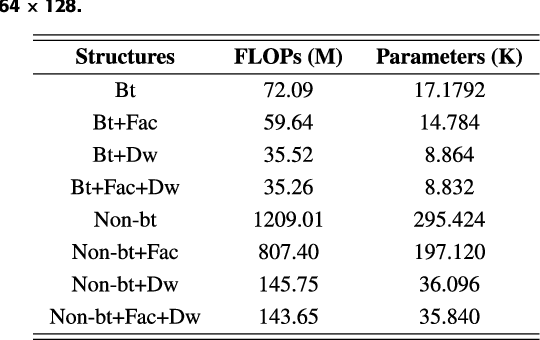
Building footprint extraction from high-resolution aerial images is always an essential part of urban dynamic monitoring, planning and management. It has also been a challenging task in remote sensing research. In recent years, deep neural networks have made great achievement in improving accuracy of building extraction from remote sensing imagery. However, most of existing approaches usually require large amount of parameters and floating point operations for high accuracy, it leads to high memory consumption and low inference speed which are harmful to research. In this paper, we proposed a novel efficient network named ESFNet which employs separable factorized residual block and utilizes the dilated convolutions, aiming to preserve slight accuracy loss with low computational cost and memory consumption. Our ESFNet obtains a better trade-off between accuracy and efficiency, it can run at over 100 FPS on single Tesla V100, requires 6x fewer FLOPs and has 18x fewer parameters than state-of-the-art real-time architecture ERFNet while preserving similar accuracy without any additional context module, post-processing and pre-trained scheme. We evaluated our networks on WHU Building Dataset and compared it with other state-of-the-art architectures. The result and comprehensive analysis show that our networks are benefit for efficient remote sensing researches, and the idea can be further extended to other areas. The code is public available at: https://github.com/mrluin/ESFNet-Pytorch