 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Towards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
OneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
Sep 03, 2025
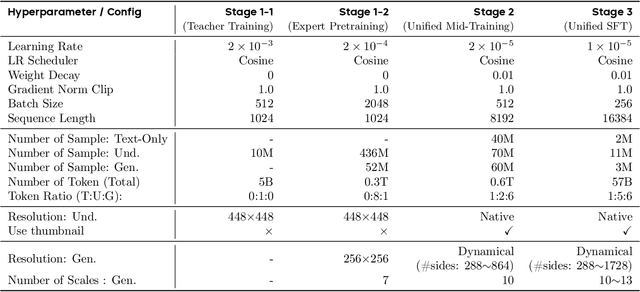


We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
METEOR: Multi-Encoder Collaborative Token Pruning for Efficient Vision Language Models
Jul 28, 2025Vision encoders serve as the cornerstone of multimodal understanding. Single-encoder architectures like CLIP exhibit inherent constraints in generalizing across diverse multimodal tasks, while recent multi-encoder fusion methods introduce prohibitive computational overhead to achieve superior performance using complementary visual representations from multiple vision encoders. To address this, we propose a progressive pruning framework, namely Multi-Encoder collaboraTivE tOken pRuning (METEOR), that eliminates redundant visual tokens across the encoding, fusion, and decoding stages for multi-encoder MLLMs. For multi-vision encoding, we discard redundant tokens within each encoder via a rank guided collaborative token assignment strategy. Subsequently, for multi-vision fusion, we combine the visual features from different encoders while reducing cross-encoder redundancy with cooperative pruning. Finally, we propose an adaptive token pruning method in the LLM decoding stage to further discard irrelevant tokens based on the text prompts with dynamically adjusting pruning ratios for specific task demands. To our best knowledge, this is the first successful attempt that achieves an efficient multi-encoder based vision language model with multi-stage pruning strategies. Extensive experiments on 11 benchmarks demonstrate the effectiveness of our proposed approach. Compared with EAGLE, a typical multi-encoder MLLMs, METEOR reduces 76% visual tokens with only 0.3% performance drop in average. The code is available at https://github.com/YuchenLiu98/METEOR.
Noise Conditional Variational Score Distillation
Jun 11, 2025
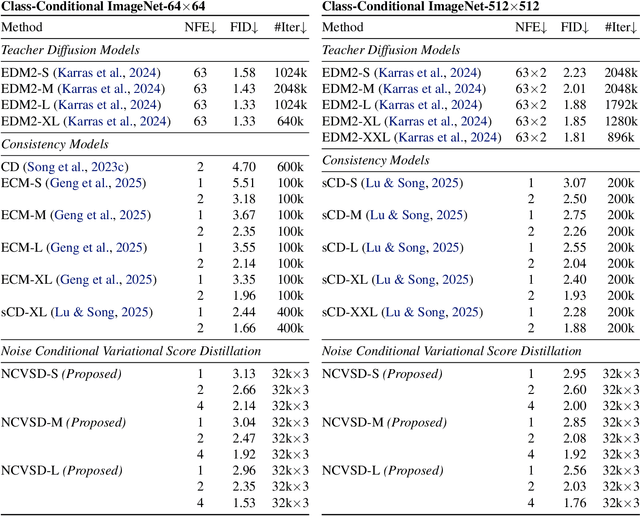
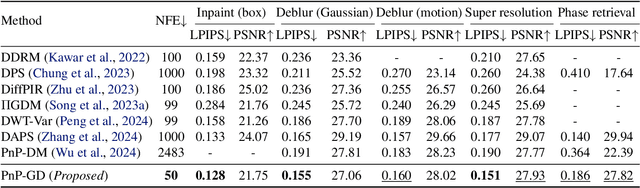

We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.
Learning Unsupervised Gaze Representation via Eye Mask Driven Information Bottleneck
Jun 29, 2024



Appearance-based supervised methods with full-face image input have made tremendous advances in recent gaze estimation tasks. However, intensive human annotation requirement inhibits current methods from achieving industrial level accuracy and robustness. Although current unsupervised pre-training frameworks have achieved success in many image recognition tasks, due to the deep coupling between facial and eye features, such frameworks are still deficient in extracting useful gaze features from full-face. To alleviate above limitations, this work proposes a novel unsupervised/self-supervised gaze pre-training framework, which forces the full-face branch to learn a low dimensional gaze embedding without gaze annotations, through collaborative feature contrast and squeeze modules. In the heart of this framework is an alternating eye-attended/unattended masking training scheme, which squeezes gaze-related information from full-face branch into an eye-masked auto-encoder through an injection bottleneck design that successfully encourages the model to pays more attention to gaze direction rather than facial textures only, while still adopting the eye self-reconstruction objective. In the same time, a novel eye/gaze-related information contrastive loss has been designed to further boost the learned representation by forcing the model to focus on eye-centered regions. Extensive experimental results on several gaze benchmarks demonstrate that the proposed scheme achieves superior performances over unsupervised state-of-the-art.
Parameter-efficient Fine-tuning in Hyperspherical Space for Open-vocabulary Semantic Segmentation
May 29, 2024



Open-vocabulary semantic segmentation seeks to label each pixel in an image with arbitrary text descriptions. Vision-language foundation models, especially CLIP, have recently emerged as powerful tools for acquiring open-vocabulary capabilities. However, fine-tuning CLIP to equip it with pixel-level prediction ability often suffers three issues: 1) high computational cost, 2) misalignment between the two inherent modalities of CLIP, and 3) degraded generalization ability on unseen categories. To address these issues, we propose H-CLIP a symmetrical parameter-efficient fine-tuning (PEFT) strategy conducted in hyperspherical space for both of the two CLIP modalities. Specifically, the PEFT strategy is achieved by a series of efficient block-diagonal learnable transformation matrices and a dual cross-relation communication module among all learnable matrices. Since the PEFT strategy is conducted symmetrically to the two CLIP modalities, the misalignment between them is mitigated. Furthermore, we apply an additional constraint to PEFT on the CLIP text encoder according to the hyperspherical energy principle, i.e., minimizing hyperspherical energy during fine-tuning preserves the intrinsic structure of the original parameter space, to prevent the destruction of the generalization ability offered by the CLIP text encoder. Extensive evaluations across various benchmarks show that H-CLIP achieves new SOTA open-vocabulary semantic segmentation results while only requiring updating approximately 4% of the total parameters of CLIP.
UMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding
Jan 18, 2024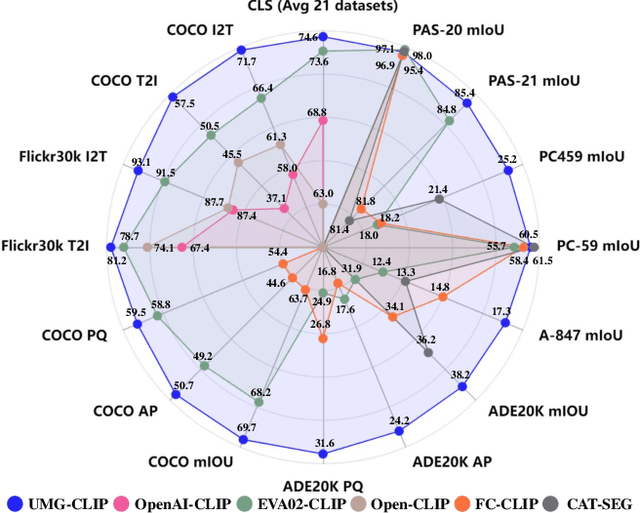
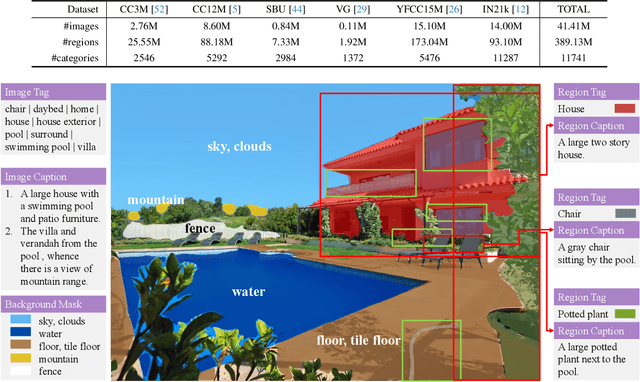
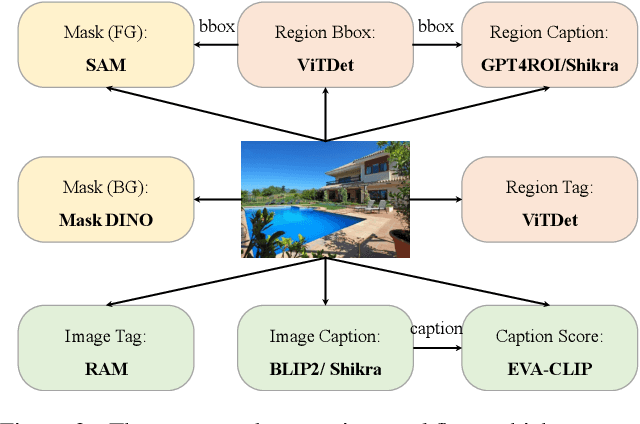
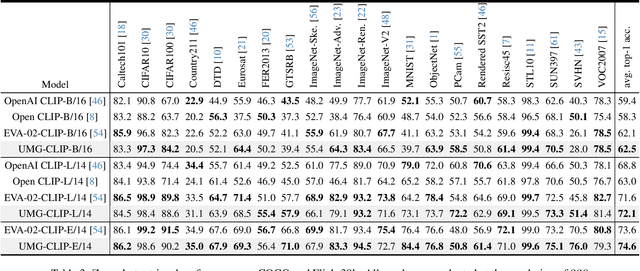
Vision-language foundation models, represented by Contrastive language-image pre-training (CLIP), have gained increasing attention for jointly understanding both vision and textual tasks. However, existing approaches primarily focus on training models to match global image representations with textual descriptions, thereby overlooking the critical alignment between local regions and corresponding text tokens. This paper extends CLIP with multi-granularity alignment. Notably, we deliberately construct a new dataset comprising pseudo annotations at various levels of granularities, encompassing image-level, region-level, and pixel-level captions/tags. Accordingly, we develop a unified multi-granularity learning framework, named UMG-CLIP, that simultaneously empowers the model with versatile perception abilities across different levels of detail. Equipped with parameter efficient tuning, UMG-CLIP surpasses current widely used CLIP models and achieves state-of-the-art performance on diverse image understanding benchmarks, including open-world recognition, retrieval, semantic segmentation, and panoptic segmentation tasks. We hope UMG-CLIP can serve as a valuable option for advancing vision-language foundation models.
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.
Hybrid Distillation: Connecting Masked Autoencoders with Contrastive Learners
Jun 28, 2023



Representation learning has been evolving from traditional supervised training to Contrastive Learning (CL) and Masked Image Modeling (MIM). Previous works have demonstrated their pros and cons in specific scenarios, i.e., CL and supervised pre-training excel at capturing longer-range global patterns and enabling better feature discrimination, while MIM can introduce more local and diverse attention across all transformer layers. In this paper, we explore how to obtain a model that combines their strengths. We start by examining previous feature distillation and mask feature reconstruction methods and identify their limitations. We find that their increasing diversity mainly derives from the asymmetric designs, but these designs may in turn compromise the discrimination ability. In order to better obtain both discrimination and diversity, we propose a simple but effective Hybrid Distillation strategy, which utilizes both the supervised/CL teacher and the MIM teacher to jointly guide the student model. Hybrid Distill imitates the token relations of the MIM teacher to alleviate attention collapse, as well as distills the feature maps of the supervised/CL teacher to enable discrimination. Furthermore, a progressive redundant token masking strategy is also utilized to reduce the distilling costs and avoid falling into local optima. Experiment results prove that Hybrid Distill can achieve superior performance on different benchmarks.