 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-Discontinuity Mining for Generalized Deepfake Detection
Dec 26, 2025The rapid advancement of generative artificial intelligence has enabled the creation of highly realistic fake facial images, posing serious threats to personal privacy and the integrity of online information. Existing deepfake detection methods often rely on handcrafted forensic cues and complex architectures, achieving strong performance in intra-domain settings but suffering significant degradation when confronted with unseen forgery patterns. In this paper, we propose GenDF, a simple yet effective framework that transfers a powerful large-scale vision model to the deepfake detection task with a compact and neat network design. GenDF incorporates deepfake-specific representation learning to capture discriminative patterns between real and fake facial images, feature space redistribution to mitigate distribution mismatch, and a classification-invariant feature augmentation strategy to enhance generalization without introducing additional trainable parameters. Extensive experiments demonstrate that GenDF achieves state-of-the-art generalization performance in cross-domain and cross-manipulation settings while requiring only 0.28M trainable parameters, validating the effectiveness and efficiency of the proposed framework.
NEARL-CLIP: Interacted Query Adaptation with Orthogonal Regularization for Medical Vision-Language Understanding
Aug 06, 2025



Computer-aided medical image analysis is crucial for disease diagnosis and treatment planning, yet limited annotated datasets restrict medical-specific model development. While vision-language models (VLMs) like CLIP offer strong generalization capabilities, their direct application to medical imaging analysis is impeded by a significant domain gap. Existing approaches to bridge this gap, including prompt learning and one-way modality interaction techniques, typically focus on introducing domain knowledge to a single modality. Although this may offer performance gains, it often causes modality misalignment, thereby failing to unlock the full potential of VLMs. In this paper, we propose \textbf{NEARL-CLIP} (i\underline{N}teracted qu\underline{E}ry \underline{A}daptation with o\underline{R}thogona\underline{L} Regularization), a novel cross-modality interaction VLM-based framework that contains two contributions: (1) Unified Synergy Embedding Transformer (USEformer), which dynamically generates cross-modality queries to promote interaction between modalities, thus fostering the mutual enrichment and enhancement of multi-modal medical domain knowledge; (2) Orthogonal Cross-Attention Adapter (OCA). OCA introduces an orthogonality technique to decouple the new knowledge from USEformer into two distinct components: the truly novel information and the incremental knowledge. By isolating the learning process from the interference of incremental knowledge, OCA enables a more focused acquisition of new information, thereby further facilitating modality interaction and unleashing the capability of VLMs. Notably, NEARL-CLIP achieves these two contributions in a parameter-efficient style, which only introduces \textbf{1.46M} learnable parameters.
Parameter-Free Fine-tuning via Redundancy Elimination for Vision Foundation Models
Apr 11, 2025Vision foundation models (VFMs) are large pre-trained models that form the backbone of various vision tasks. Fine-tuning VFMs can further unlock their potential for downstream tasks or scenarios. However, VFMs often contain significant feature redundancy, which may limit their adaptability to new tasks. In this paper, we investigate the redundancies in the segment anything model (SAM) and then propose a parameter-free fine-tuning method to address this issue. Unlike traditional fine-tuning methods that adjust parameters, our method emphasizes selecting, reusing, and enhancing pre-trained features, offering a new perspective on model fine-tuning. Specifically, we introduce a channel selection algorithm based on the model's output difference to identify redundant and effective channels. By selectively replacing the redundant channels with more effective ones, we filter out less useful features and reuse the more relevant features to downstream tasks, thereby enhancing the task-specific feature representation. Experiments on both out-of-domain and in-domain datasets demonstrate the efficiency and effectiveness of our method. Notably, our approach can seamlessly integrate with existing fine-tuning strategies (e.g., LoRA, Adapter), further boosting the performance of already fine-tuned models. Moreover, since our channel selection involves only model inference, our method significantly reduces computational and GPU memory overhead.
Robust SAM: On the Adversarial Robustness of Vision Foundation Models
Apr 11, 2025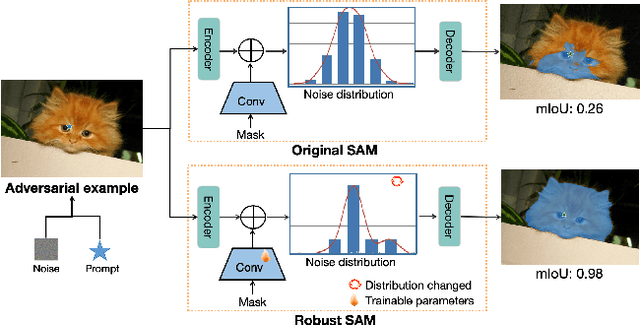
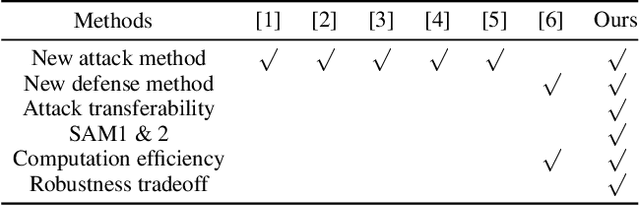
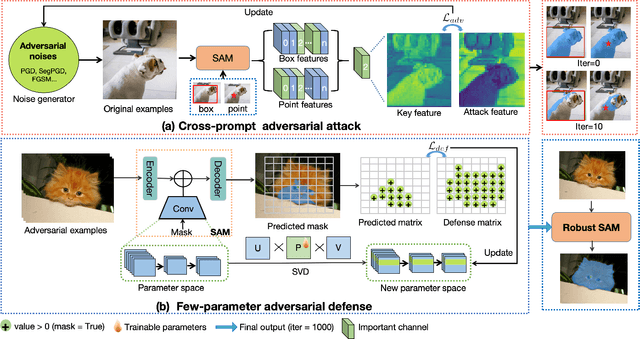
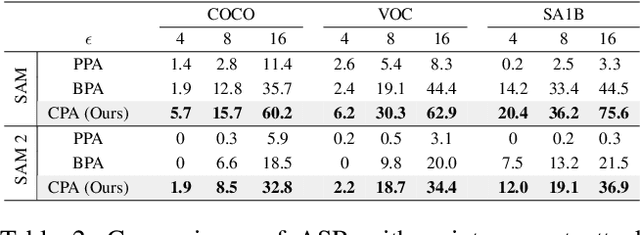
The Segment Anything Model (SAM) is a widely used vision foundation model with diverse applications, including image segmentation, detection, and tracking. Given SAM's wide applications, understanding its robustness against adversarial attacks is crucial for real-world deployment. However, research on SAM's robustness is still in its early stages. Existing attacks often overlook the role of prompts in evaluating SAM's robustness, and there has been insufficient exploration of defense methods to balance the robustness and accuracy. To address these gaps, this paper proposes an adversarial robustness framework designed to evaluate and enhance the robustness of SAM. Specifically, we introduce a cross-prompt attack method to enhance the attack transferability across different prompt types. Besides attacking, we propose a few-parameter adaptation strategy to defend SAM against various adversarial attacks. To balance robustness and accuracy, we use the singular value decomposition (SVD) to constrain the space of trainable parameters, where only singular values are adaptable. Experiments demonstrate that our cross-prompt attack method outperforms previous approaches in terms of attack success rate on both SAM and SAM 2. By adapting only 512 parameters, we achieve at least a 15\% improvement in mean intersection over union (mIoU) against various adversarial attacks. Compared to previous defense methods, our approach enhances the robustness of SAM while maximally maintaining its original performance.
Parameter-efficient Fine-tuning in Hyperspherical Space for Open-vocabulary Semantic Segmentation
May 29, 2024



Open-vocabulary semantic segmentation seeks to label each pixel in an image with arbitrary text descriptions. Vision-language foundation models, especially CLIP, have recently emerged as powerful tools for acquiring open-vocabulary capabilities. However, fine-tuning CLIP to equip it with pixel-level prediction ability often suffers three issues: 1) high computational cost, 2) misalignment between the two inherent modalities of CLIP, and 3) degraded generalization ability on unseen categories. To address these issues, we propose H-CLIP a symmetrical parameter-efficient fine-tuning (PEFT) strategy conducted in hyperspherical space for both of the two CLIP modalities. Specifically, the PEFT strategy is achieved by a series of efficient block-diagonal learnable transformation matrices and a dual cross-relation communication module among all learnable matrices. Since the PEFT strategy is conducted symmetrically to the two CLIP modalities, the misalignment between them is mitigated. Furthermore, we apply an additional constraint to PEFT on the CLIP text encoder according to the hyperspherical energy principle, i.e., minimizing hyperspherical energy during fine-tuning preserves the intrinsic structure of the original parameter space, to prevent the destruction of the generalization ability offered by the CLIP text encoder. Extensive evaluations across various benchmarks show that H-CLIP achieves new SOTA open-vocabulary semantic segmentation results while only requiring updating approximately 4% of the total parameters of CLIP.
FLoRA: Low-Rank Core Space for N-dimension
May 23, 2024



Adapting pre-trained foundation models for various downstream tasks has been prevalent in artificial intelligence. Due to the vast number of tasks and high costs, adjusting all parameters becomes unfeasible. To mitigate this, several fine-tuning techniques have been developed to update the pre-trained model weights in a more resource-efficient manner, such as through low-rank adjustments. Yet, almost all of these methods focus on linear weights, neglecting the intricacies of parameter spaces in higher dimensions like 4D. Alternatively, some methods can be adapted for high-dimensional parameter space by compressing changes in the original space into two dimensions and then employing low-rank matrix decomposition. However, these approaches destructs the structural integrity of the involved high-dimensional spaces. To tackle the diversity of dimensional spaces across different foundation models and provide a more precise representation of the changes within these spaces, this paper introduces a generalized parameter-efficient fine-tuning framework, FLoRA, designed for various dimensional parameter space. Specifically, utilizing Tucker decomposition, FLoRA asserts that changes in each dimensional parameter space are based on a low-rank core space which maintains the consistent topological structure with the original space. It then models the changes through this core space alongside corresponding weights to reconstruct alterations in the original space. FLoRA effectively preserves the structural integrity of the change of original N-dimensional parameter space, meanwhile decomposes it via low-rank tensor decomposition. Extensive experiments on computer vision, natural language processing and multi-modal tasks validate FLoRA's effectiveness. Codes are available at https://github.com/SJTU-DeepVisionLab/FLoRA.
Vision-Informed Flow Image Super-Resolution with Quaternion Spatial Modeling and Dynamic Flow Convolution
Jan 29, 2024Flow image super-resolution (FISR) aims at recovering high-resolution turbulent velocity fields from low-resolution flow images. Existing FISR methods mainly process the flow images in natural image patterns, while the critical and distinct flow visual properties are rarely considered. This negligence would cause the significant domain gap between flow and natural images to severely hamper the accurate perception of flow turbulence, thereby undermining super-resolution performance. To tackle this dilemma, we comprehensively consider the flow visual properties, including the unique flow imaging principle and morphological information, and propose the first flow visual property-informed FISR algorithm. Particularly, different from natural images that are constructed by independent RGB channels in the light field, flow images build on the orthogonal UVW velocities in the flow field. To empower the FISR network with an awareness of the flow imaging principle, we propose quaternion spatial modeling to model this orthogonal spatial relationship for improved FISR. Moreover, due to viscosity and surface tension characteristics, fluids often exhibit a droplet-like morphology in flow images. Inspired by this morphological property, we design the dynamic flow convolution to effectively mine the morphological information to enhance FISR. Extensive experiments on the newly acquired flow image datasets demonstrate the state-of-the-art performance of our method. Code and data will be made available.
Domain Prompt Learning with Quaternion Networks
Dec 12, 2023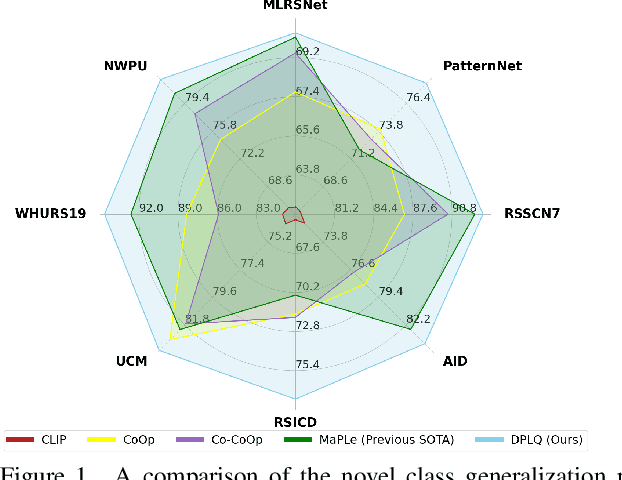


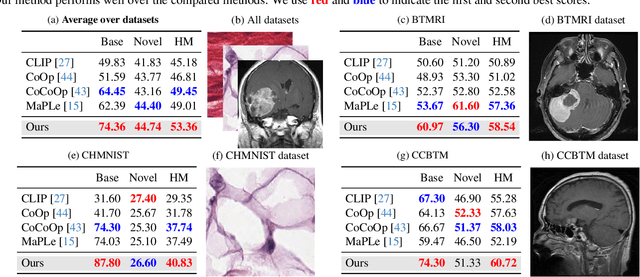
Prompt learning has emerged as an effective and data-efficient technique in large Vision-Language Models (VLMs). However, when adapting VLMs to specialized domains such as remote sensing and medical imaging, domain prompt learning remains underexplored. While large-scale domain-specific foundation models can help tackle this challenge, their concentration on a single vision level makes it challenging to prompt both vision and language modalities. To overcome this, we propose to leverage domain-specific knowledge from domain-specific foundation models to transfer the robust recognition ability of VLMs from generalized to specialized domains, using quaternion networks. Specifically, the proposed method involves using domain-specific vision features from domain-specific foundation models to guide the transformation of generalized contextual embeddings from the language branch into a specialized space within the quaternion networks. Moreover, we present a hierarchical approach that generates vision prompt features by analyzing intermodal relationships between hierarchical language prompt features and domain-specific vision features. In this way, quaternion networks can effectively mine the intermodal relationships in the specific domain, facilitating domain-specific vision-language contrastive learning. Extensive experiments on domain-specific datasets show that our proposed method achieves new state-of-the-art results in prompt learning.
Parameter Efficient Fine-tuning via Cross Block Orchestration for Segment Anything Model
Nov 28, 2023Parameter-efficient fine-tuning (PEFT) is an effective methodology to unleash the potential of large foundation models in novel scenarios with limited training data. In the computer vision community, PEFT has shown effectiveness in image classification, but little research has studied its ability for image segmentation. Fine-tuning segmentation models usually require a heavier adjustment of parameters to align the proper projection directions in the parameter space for new scenarios. This raises a challenge to existing PEFT algorithms, as they often inject a limited number of individual parameters into each block, which prevents substantial adjustment of the projection direction of the parameter space due to the limitation of Hidden Markov Chain along blocks. In this paper, we equip PEFT with a cross-block orchestration mechanism to enable the adaptation of the Segment Anything Model (SAM) to various downstream scenarios. We introduce a novel inter-block communication module, which integrates a learnable relation matrix to facilitate communication among different coefficient sets of each PEFT block's parameter space. Moreover, we propose an intra-block enhancement module, which introduces a linear projection head whose weights are generated from a hyper-complex layer, further enhancing the impact of the adjustment of projection directions on the entire parameter space. Extensive experiments on diverse benchmarks demonstrate that our proposed approach consistently improves the segmentation performance significantly on novel scenarios with only around 1K additional parameters.
Domain-Controlled Prompt Learning
Sep 30, 2023



Large pre-trained vision-language models, such as CLIP, have shown remarkable generalization capabilities across various tasks when appropriate text prompts are provided. However, adapting these models to specialized domains, like remote sensing images (RSIs), medical images, etc, remains unexplored and challenging. Existing prompt learning methods often lack domain-awareness or domain-transfer mechanisms, leading to suboptimal performance due to the misinterpretation of specialized images in natural image patterns. To tackle this dilemma, we proposed a Domain-Controlled Prompt Learning for the specialized domains. Specifically, the large-scale specialized domain foundation model (LSDM) is first introduced to provide essential specialized domain knowledge. Using lightweight neural networks, we transfer this knowledge into domain biases, which control both the visual and language branches to obtain domain-adaptive prompts in a directly incorporating manner. Simultaneously, to overcome the existing overfitting challenge, we propose a novel noisy-adding strategy, without extra trainable parameters, to help the model escape the suboptimal solution in a global domain oscillation manner. Experimental results show our method achieves state-of-the-art performance in specialized domain image recognition datasets. Our code is available at https://anonymous.4open.science/r/DCPL-8588.