 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBizFinBench.v2: A Unified Dual-Mode Bilingual Benchmark for Expert-Level Financial Capability Alignment
Jan 10, 2026Large language models have undergone rapid evolution, emerging as a pivotal technology for intelligence in financial operations. However, existing benchmarks are often constrained by pitfalls such as reliance on simulated or general-purpose samples and a focus on singular, offline static scenarios. Consequently, they fail to align with the requirements for authenticity and real-time responsiveness in financial services, leading to a significant discrepancy between benchmark performance and actual operational efficacy. To address this, we introduce BizFinBench.v2, the first large-scale evaluation benchmark grounded in authentic business data from both Chinese and U.S. equity markets, integrating online assessment. We performed clustering analysis on authentic user queries from financial platforms, resulting in eight fundamental tasks and two online tasks across four core business scenarios, totaling 29,578 expert-level Q&A pairs. Experimental results demonstrate that ChatGPT-5 achieves a prominent 61.5% accuracy in main tasks, though a substantial gap relative to financial experts persists; in online tasks, DeepSeek-R1 outperforms all other commercial LLMs. Error analysis further identifies the specific capability deficiencies of existing models within practical financial business contexts. BizFinBench.v2 transcends the limitations of current benchmarks, achieving a business-level deconstruction of LLM financial capabilities and providing a precise basis for evaluating efficacy in the widespread deployment of LLMs within the financial domain. The data and code are available at https://github.com/HiThink-Research/BizFinBench.v2.
Patch-Discontinuity Mining for Generalized Deepfake Detection
Dec 26, 2025The rapid advancement of generative artificial intelligence has enabled the creation of highly realistic fake facial images, posing serious threats to personal privacy and the integrity of online information. Existing deepfake detection methods often rely on handcrafted forensic cues and complex architectures, achieving strong performance in intra-domain settings but suffering significant degradation when confronted with unseen forgery patterns. In this paper, we propose GenDF, a simple yet effective framework that transfers a powerful large-scale vision model to the deepfake detection task with a compact and neat network design. GenDF incorporates deepfake-specific representation learning to capture discriminative patterns between real and fake facial images, feature space redistribution to mitigate distribution mismatch, and a classification-invariant feature augmentation strategy to enhance generalization without introducing additional trainable parameters. Extensive experiments demonstrate that GenDF achieves state-of-the-art generalization performance in cross-domain and cross-manipulation settings while requiring only 0.28M trainable parameters, validating the effectiveness and efficiency of the proposed framework.
PapMOT: Exploring Adversarial Patch Attack against Multiple Object Tracking
Apr 12, 2025Tracking multiple objects in a continuous video stream is crucial for many computer vision tasks. It involves detecting and associating objects with their respective identities across successive frames. Despite significant progress made in multiple object tracking (MOT), recent studies have revealed the vulnerability of existing MOT methods to adversarial attacks. Nevertheless, all of these attacks belong to digital attacks that inject pixel-level noise into input images, and are therefore ineffective in physical scenarios. To fill this gap, we propose PapMOT, which can generate physical adversarial patches against MOT for both digital and physical scenarios. Besides attacking the detection mechanism, PapMOT also optimizes a printable patch that can be detected as new targets to mislead the identity association process. Moreover, we introduce a patch enhancement strategy to further degrade the temporal consistency of tracking results across video frames, resulting in more aggressive attacks. We further develop new evaluation metrics to assess the robustness of MOT against such attacks. Extensive evaluations on multiple datasets demonstrate that our PapMOT can successfully attack various architectures of MOT trackers in digital scenarios. We also validate the effectiveness of PapMOT for physical attacks by deploying printed adversarial patches in the real world.
Robust SAM: On the Adversarial Robustness of Vision Foundation Models
Apr 11, 2025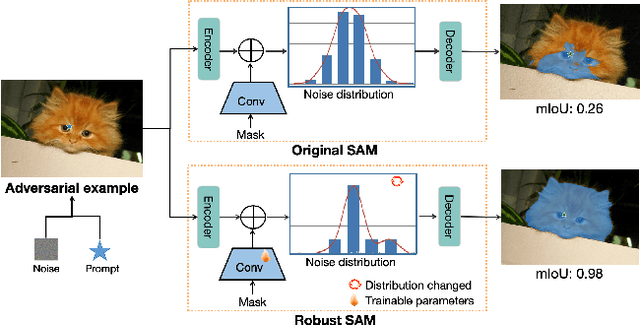
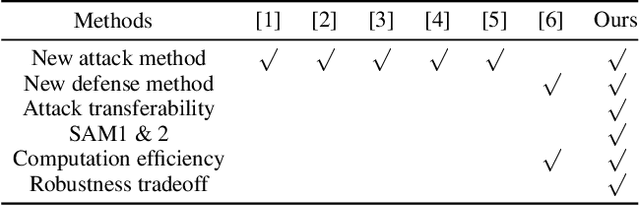
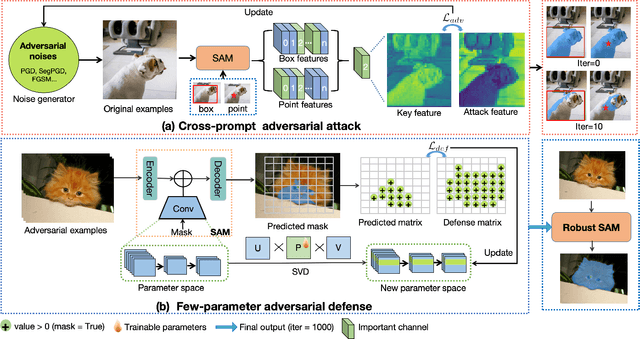
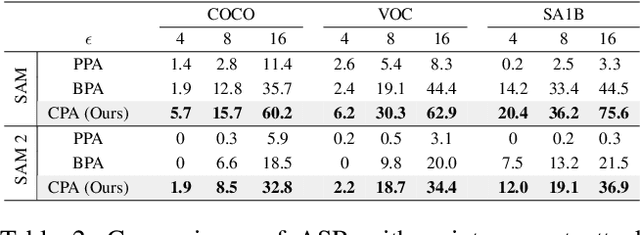
The Segment Anything Model (SAM) is a widely used vision foundation model with diverse applications, including image segmentation, detection, and tracking. Given SAM's wide applications, understanding its robustness against adversarial attacks is crucial for real-world deployment. However, research on SAM's robustness is still in its early stages. Existing attacks often overlook the role of prompts in evaluating SAM's robustness, and there has been insufficient exploration of defense methods to balance the robustness and accuracy. To address these gaps, this paper proposes an adversarial robustness framework designed to evaluate and enhance the robustness of SAM. Specifically, we introduce a cross-prompt attack method to enhance the attack transferability across different prompt types. Besides attacking, we propose a few-parameter adaptation strategy to defend SAM against various adversarial attacks. To balance robustness and accuracy, we use the singular value decomposition (SVD) to constrain the space of trainable parameters, where only singular values are adaptable. Experiments demonstrate that our cross-prompt attack method outperforms previous approaches in terms of attack success rate on both SAM and SAM 2. By adapting only 512 parameters, we achieve at least a 15\% improvement in mean intersection over union (mIoU) against various adversarial attacks. Compared to previous defense methods, our approach enhances the robustness of SAM while maximally maintaining its original performance.
Parameter-Free Fine-tuning via Redundancy Elimination for Vision Foundation Models
Apr 11, 2025Vision foundation models (VFMs) are large pre-trained models that form the backbone of various vision tasks. Fine-tuning VFMs can further unlock their potential for downstream tasks or scenarios. However, VFMs often contain significant feature redundancy, which may limit their adaptability to new tasks. In this paper, we investigate the redundancies in the segment anything model (SAM) and then propose a parameter-free fine-tuning method to address this issue. Unlike traditional fine-tuning methods that adjust parameters, our method emphasizes selecting, reusing, and enhancing pre-trained features, offering a new perspective on model fine-tuning. Specifically, we introduce a channel selection algorithm based on the model's output difference to identify redundant and effective channels. By selectively replacing the redundant channels with more effective ones, we filter out less useful features and reuse the more relevant features to downstream tasks, thereby enhancing the task-specific feature representation. Experiments on both out-of-domain and in-domain datasets demonstrate the efficiency and effectiveness of our method. Notably, our approach can seamlessly integrate with existing fine-tuning strategies (e.g., LoRA, Adapter), further boosting the performance of already fine-tuned models. Moreover, since our channel selection involves only model inference, our method significantly reduces computational and GPU memory overhead.
Integrating Stock Features and Global Information via Large Language Models for Enhanced Stock Return Prediction
Oct 09, 2023



The remarkable achievements and rapid advancements of Large Language Models (LLMs) such as ChatGPT and GPT-4 have showcased their immense potential in quantitative investment. Traders can effectively leverage these LLMs to analyze financial news and predict stock returns accurately. However, integrating LLMs into existing quantitative models presents two primary challenges: the insufficient utilization of semantic information embedded within LLMs and the difficulties in aligning the latent information within LLMs with pre-existing quantitative stock features. We propose a novel framework consisting of two components to surmount these challenges. The first component, the Local-Global (LG) model, introduces three distinct strategies for modeling global information. These approaches are grounded respectively on stock features, the capabilities of LLMs, and a hybrid method combining the two paradigms. The second component, Self-Correlated Reinforcement Learning (SCRL), focuses on aligning the embeddings of financial news generated by LLMs with stock features within the same semantic space. By implementing our framework, we have demonstrated superior performance in Rank Information Coefficient and returns, particularly compared to models relying only on stock features in the China A-share market.
* 8 pages, International Joint Conferences on Artificial Intelligence
Adv-Attribute: Inconspicuous and Transferable Adversarial Attack on Face Recognition
Oct 13, 2022
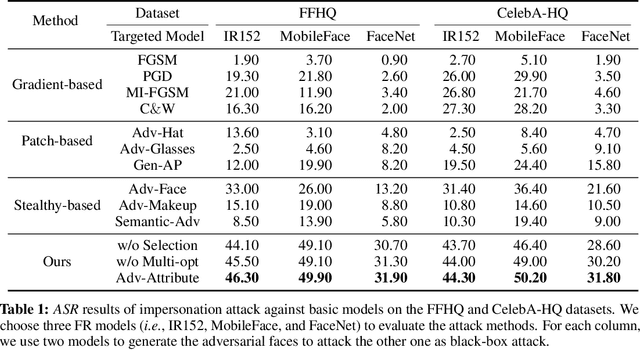
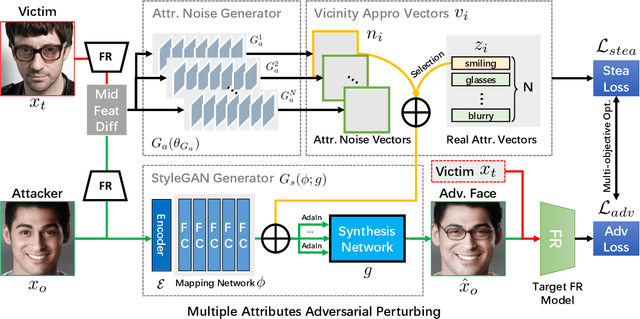
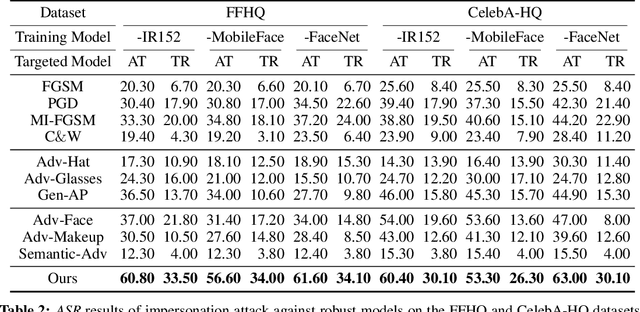
Deep learning models have shown their vulnerability when dealing with adversarial attacks. Existing attacks almost perform on low-level instances, such as pixels and super-pixels, and rarely exploit semantic clues. For face recognition attacks, existing methods typically generate the l_p-norm perturbations on pixels, however, resulting in low attack transferability and high vulnerability to denoising defense models. In this work, instead of performing perturbations on the low-level pixels, we propose to generate attacks through perturbing on the high-level semantics to improve attack transferability. Specifically, a unified flexible framework, Adversarial Attributes (Adv-Attribute), is designed to generate inconspicuous and transferable attacks on face recognition, which crafts the adversarial noise and adds it into different attributes based on the guidance of the difference in face recognition features from the target. Moreover, the importance-aware attribute selection and the multi-objective optimization strategy are introduced to further ensure the balance of stealthiness and attacking strength. Extensive experiments on the FFHQ and CelebA-HQ datasets show that the proposed Adv-Attribute method achieves the state-of-the-art attacking success rates while maintaining better visual effects against recent attack methods.
Exploring Frequency Adversarial Attacks for Face Forgery Detection
Mar 29, 2022

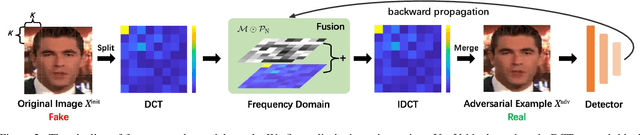
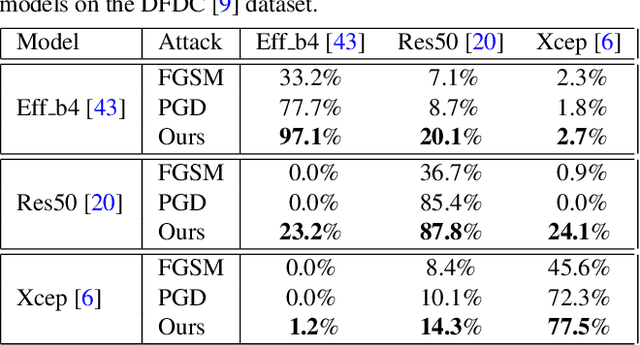
Various facial manipulation techniques have drawn serious public concerns in morality, security, and privacy. Although existing face forgery classifiers achieve promising performance on detecting fake images, these methods are vulnerable to adversarial examples with injected imperceptible perturbations on the pixels. Meanwhile, many face forgery detectors always utilize the frequency diversity between real and fake faces as a crucial clue. In this paper, instead of injecting adversarial perturbations into the spatial domain, we propose a frequency adversarial attack method against face forgery detectors. Concretely, we apply discrete cosine transform (DCT) on the input images and introduce a fusion module to capture the salient region of adversary in the frequency domain. Compared with existing adversarial attacks (e.g. FGSM, PGD) in the spatial domain, our method is more imperceptible to human observers and does not degrade the visual quality of the original images. Moreover, inspired by the idea of meta-learning, we also propose a hybrid adversarial attack that performs attacks in both the spatial and frequency domains. Extensive experiments indicate that the proposed method fools not only the spatial-based detectors but also the state-of-the-art frequency-based detectors effectively. In addition, the proposed frequency attack enhances the transferability across face forgery detectors as black-box attacks.
IoU Attack: Towards Temporally Coherent Black-Box Adversarial Attack for Visual Object Tracking
Mar 27, 2021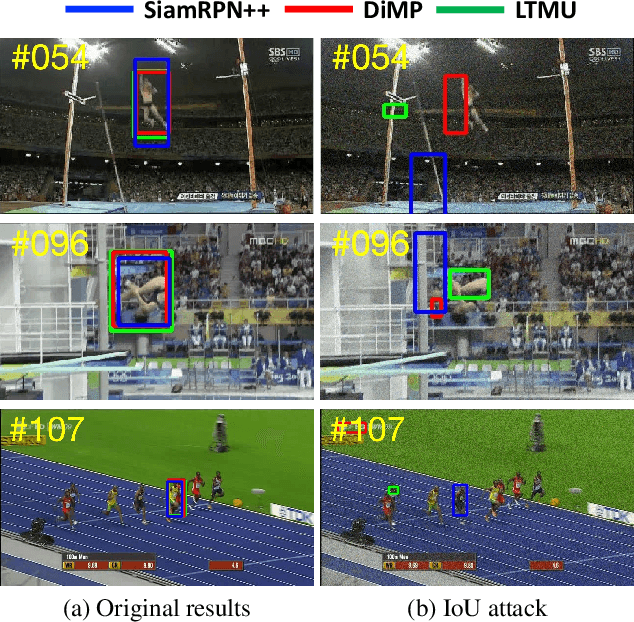

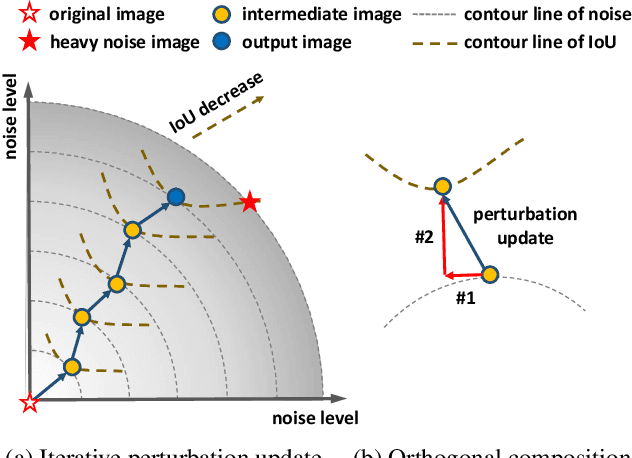

Adversarial attack arises due to the vulnerability of deep neural networks to perceive input samples injected with imperceptible perturbations. Recently, adversarial attack has been applied to visual object tracking to evaluate the robustness of deep trackers. Assuming that the model structures of deep trackers are known, a variety of white-box attack approaches to visual tracking have demonstrated promising results. However, the model knowledge about deep trackers is usually unavailable in real applications. In this paper, we propose a decision-based black-box attack method for visual object tracking. In contrast to existing black-box adversarial attack methods that deal with static images for image classification, we propose IoU attack that sequentially generates perturbations based on the predicted IoU scores from both current and historical frames. By decreasing the IoU scores, the proposed attack method degrades the accuracy of temporal coherent bounding boxes (i.e., object motions) accordingly. In addition, we transfer the learned perturbations to the next few frames to initialize temporal motion attack. We validate the proposed IoU attack on state-of-the-art deep trackers (i.e., detection based, correlation filter based, and long-term trackers). Extensive experiments on the benchmark datasets indicate the effectiveness of the proposed IoU attack method. The source code is available at https://github.com/VISION-SJTU/IoUattack.
Robust Tracking against Adversarial Attacks
Jul 29, 2020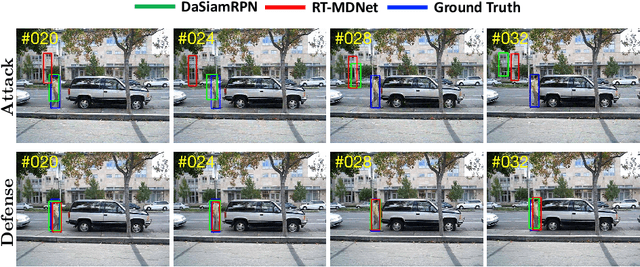
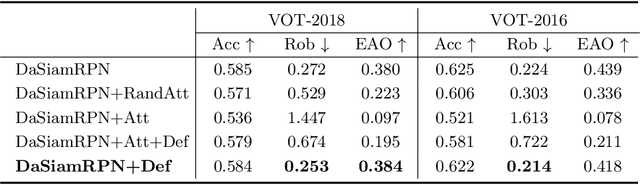
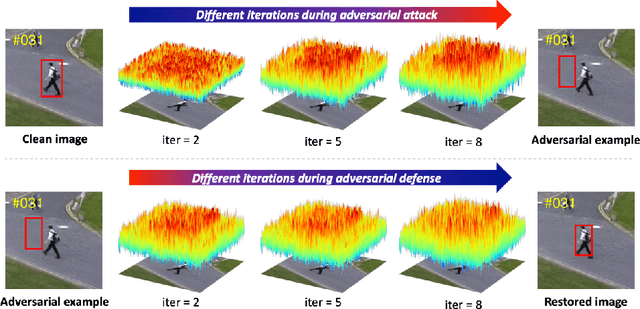
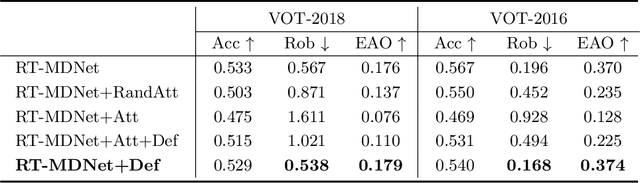
While deep convolutional neural networks (CNNs) are vulnerable to adversarial attacks, considerably few efforts have been paid to construct robust deep tracking algorithms against adversarial attacks. Current studies on adversarial attack and defense mainly reside in a single image. In this work, we first attempt to generate adversarial examples on top of video sequences to improve the tracking robustness against adversarial attacks. To this end, we take temporal motion into consideration when generating lightweight perturbations over the estimated tracking results frame-by-frame. On one hand, we add the temporal perturbations into the original video sequences as adversarial examples to greatly degrade the tracking performance. On the other hand, we sequentially estimate the perturbations from input sequences and learn to eliminate their effect for performance restoration. We apply the proposed adversarial attack and defense approaches to state-of-the-art deep tracking algorithms. Extensive evaluations on the benchmark datasets demonstrate that our defense method not only eliminates the large performance drops caused by adversarial attacks, but also achieves additional performance gains when deep trackers are not under adversarial attacks.