 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Pseudo Learning for Open-World DeepFake Attribution
Sep 20, 2023The challenge in sourcing attribution for forgery faces has gained widespread attention due to the rapid development of generative techniques. While many recent works have taken essential steps on GAN-generated faces, more threatening attacks related to identity swapping or expression transferring are still overlooked. And the forgery traces hidden in unknown attacks from the open-world unlabeled faces still remain under-explored. To push the related frontier research, we introduce a new benchmark called Open-World DeepFake Attribution (OW-DFA), which aims to evaluate attribution performance against various types of fake faces under open-world scenarios. Meanwhile, we propose a novel framework named Contrastive Pseudo Learning (CPL) for the OW-DFA task through 1) introducing a Global-Local Voting module to guide the feature alignment of forged faces with different manipulated regions, 2) designing a Confidence-based Soft Pseudo-label strategy to mitigate the pseudo-noise caused by similar methods in unlabeled set. In addition, we extend the CPL framework with a multi-stage paradigm that leverages pre-train technique and iterative learning to further enhance traceability performance. Extensive experiments verify the superiority of our proposed method on the OW-DFA and also demonstrate the interpretability of deepfake attribution task and its impact on improving the security of deepfake detection area.
Sibling-Attack: Rethinking Transferable Adversarial Attacks against Face Recognition
Mar 22, 2023A hard challenge in developing practical face recognition (FR) attacks is due to the black-box nature of the target FR model, i.e., inaccessible gradient and parameter information to attackers. While recent research took an important step towards attacking black-box FR models through leveraging transferability, their performance is still limited, especially against online commercial FR systems that can be pessimistic (e.g., a less than 50% ASR--attack success rate on average). Motivated by this, we present Sibling-Attack, a new FR attack technique for the first time explores a novel multi-task perspective (i.e., leveraging extra information from multi-correlated tasks to boost attacking transferability). Intuitively, Sibling-Attack selects a set of tasks correlated with FR and picks the Attribute Recognition (AR) task as the task used in Sibling-Attack based on theoretical and quantitative analysis. Sibling-Attack then develops an optimization framework that fuses adversarial gradient information through (1) constraining the cross-task features to be under the same space, (2) a joint-task meta optimization framework that enhances the gradient compatibility among tasks, and (3) a cross-task gradient stabilization method which mitigates the oscillation effect during attacking. Extensive experiments demonstrate that Sibling-Attack outperforms state-of-the-art FR attack techniques by a non-trivial margin, boosting ASR by 12.61% and 55.77% on average on state-of-the-art pre-trained FR models and two well-known, widely used commercial FR systems.
Adv-Attribute: Inconspicuous and Transferable Adversarial Attack on Face Recognition
Oct 13, 2022
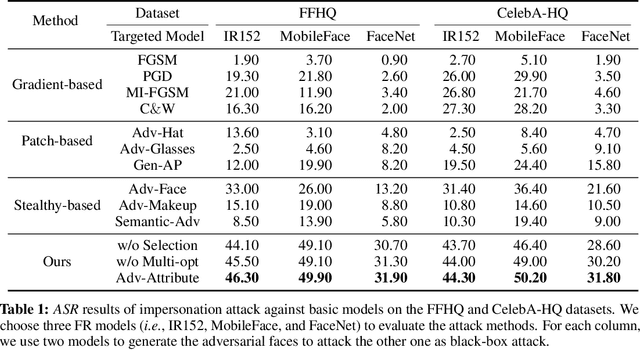
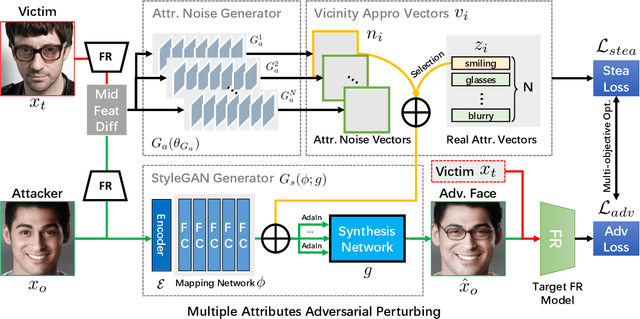
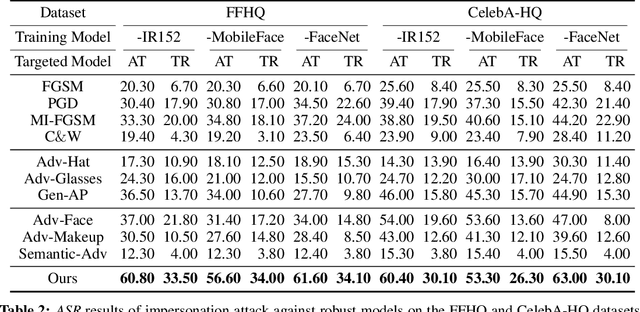
Deep learning models have shown their vulnerability when dealing with adversarial attacks. Existing attacks almost perform on low-level instances, such as pixels and super-pixels, and rarely exploit semantic clues. For face recognition attacks, existing methods typically generate the l_p-norm perturbations on pixels, however, resulting in low attack transferability and high vulnerability to denoising defense models. In this work, instead of performing perturbations on the low-level pixels, we propose to generate attacks through perturbing on the high-level semantics to improve attack transferability. Specifically, a unified flexible framework, Adversarial Attributes (Adv-Attribute), is designed to generate inconspicuous and transferable attacks on face recognition, which crafts the adversarial noise and adds it into different attributes based on the guidance of the difference in face recognition features from the target. Moreover, the importance-aware attribute selection and the multi-objective optimization strategy are introduced to further ensure the balance of stealthiness and attacking strength. Extensive experiments on the FFHQ and CelebA-HQ datasets show that the proposed Adv-Attribute method achieves the state-of-the-art attacking success rates while maintaining better visual effects against recent attack methods.
Exploring Frequency Adversarial Attacks for Face Forgery Detection
Mar 29, 2022

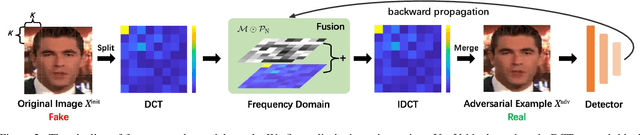
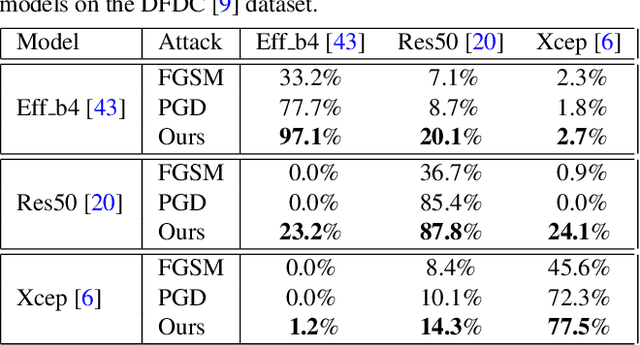
Various facial manipulation techniques have drawn serious public concerns in morality, security, and privacy. Although existing face forgery classifiers achieve promising performance on detecting fake images, these methods are vulnerable to adversarial examples with injected imperceptible perturbations on the pixels. Meanwhile, many face forgery detectors always utilize the frequency diversity between real and fake faces as a crucial clue. In this paper, instead of injecting adversarial perturbations into the spatial domain, we propose a frequency adversarial attack method against face forgery detectors. Concretely, we apply discrete cosine transform (DCT) on the input images and introduce a fusion module to capture the salient region of adversary in the frequency domain. Compared with existing adversarial attacks (e.g. FGSM, PGD) in the spatial domain, our method is more imperceptible to human observers and does not degrade the visual quality of the original images. Moreover, inspired by the idea of meta-learning, we also propose a hybrid adversarial attack that performs attacks in both the spatial and frequency domains. Extensive experiments indicate that the proposed method fools not only the spatial-based detectors but also the state-of-the-art frequency-based detectors effectively. In addition, the proposed frequency attack enhances the transferability across face forgery detectors as black-box attacks.
Structure Destruction and Content Combination for Face Anti-Spoofing
Jul 22, 2021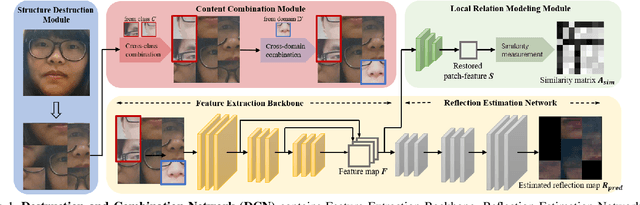
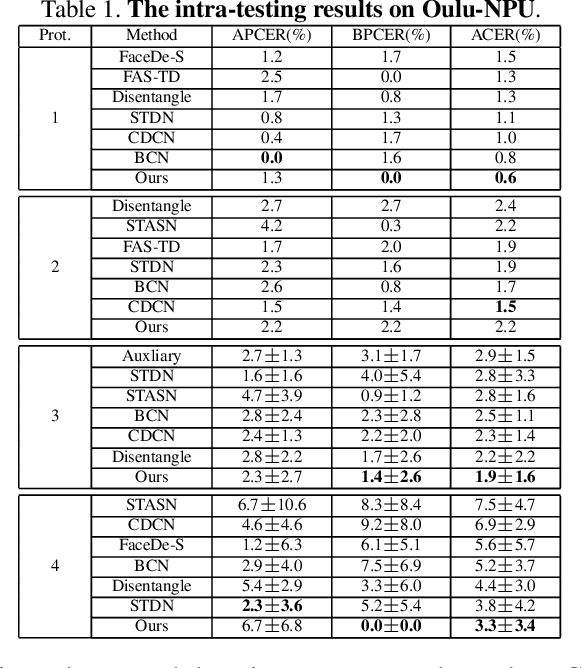
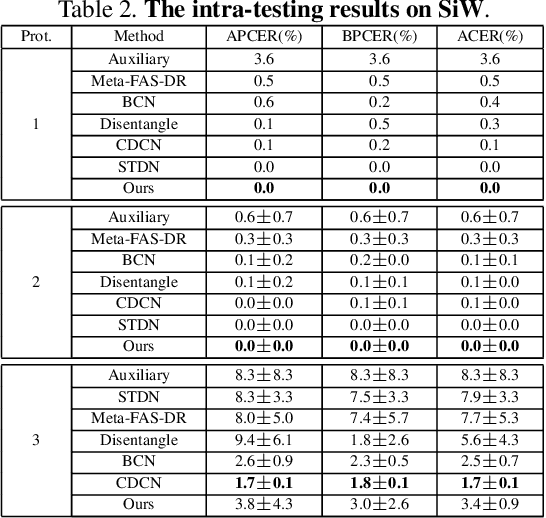

In pursuit of consolidating the face verification systems, prior face anti-spoofing studies excavate the hidden cues in original images to discriminate real persons and diverse attack types with the assistance of auxiliary supervision. However, limited by the following two inherent disturbances in their training process: 1) Complete facial structure in a single image. 2) Implicit subdomains in the whole dataset, these methods are prone to stick on memorization of the entire training dataset and show sensitivity to nonhomologous domain distribution. In this paper, we propose Structure Destruction Module and Content Combination Module to address these two imitations separately. The former mechanism destroys images into patches to construct a non-structural input, while the latter mechanism recombines patches from different subdomains or classes into a mixup construct. Based on this splitting-and-splicing operation, Local Relation Modeling Module is further proposed to model the second-order relationship between patches. We evaluate our method on extensive public datasets and promising experimental results to demonstrate the reliability of our method against state-of-the-art competitors.
Adv-Makeup: A New Imperceptible and Transferable Attack on Face Recognition
May 07, 2021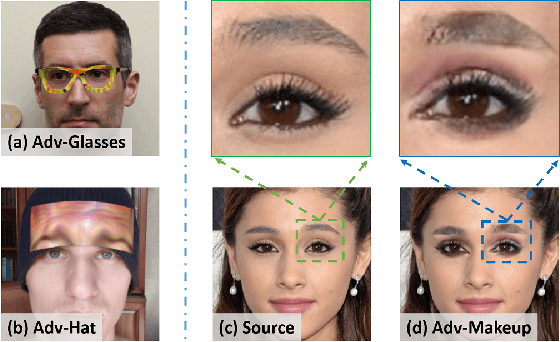
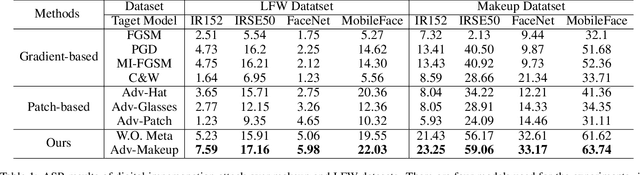
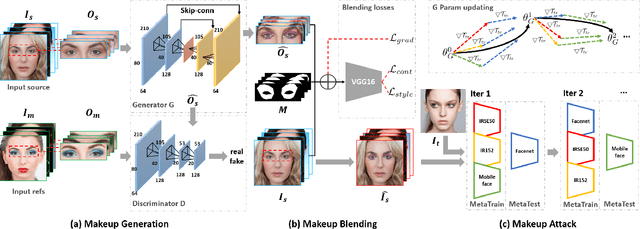
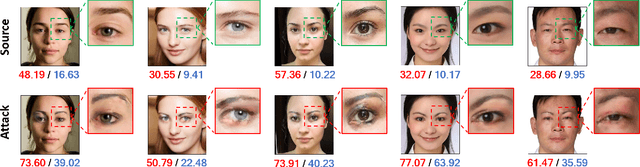
Deep neural networks, particularly face recognition models, have been shown to be vulnerable to both digital and physical adversarial examples. However, existing adversarial examples against face recognition systems either lack transferability to black-box models, or fail to be implemented in practice. In this paper, we propose a unified adversarial face generation method - Adv-Makeup, which can realize imperceptible and transferable attack under black-box setting. Adv-Makeup develops a task-driven makeup generation method with the blending module to synthesize imperceptible eye shadow over the orbital region on faces. And to achieve transferability, Adv-Makeup implements a fine-grained meta-learning adversarial attack strategy to learn more general attack features from various models. Compared to existing techniques, sufficient visualization results demonstrate that Adv-Makeup is capable to generate much more imperceptible attacks under both digital and physical scenarios. Meanwhile, extensive quantitative experiments show that Adv-Makeup can significantly improve the attack success rate under black-box setting, even attacking commercial systems.
Delving into Data: Effectively Substitute Training for Black-box Attack
Apr 26, 2021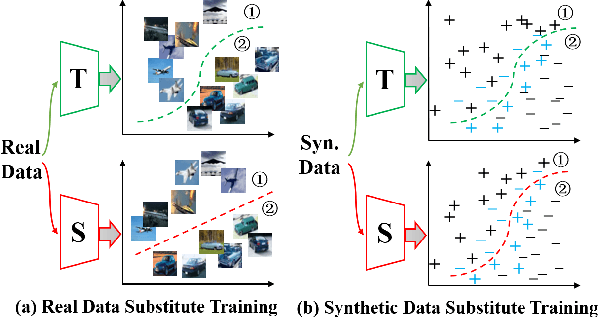


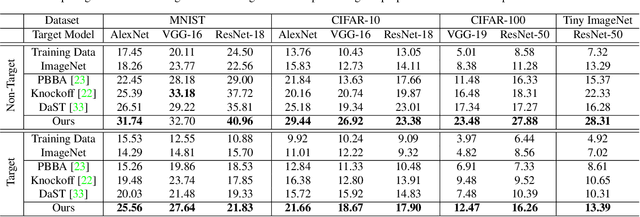
Deep models have shown their vulnerability when processing adversarial samples. As for the black-box attack, without access to the architecture and weights of the attacked model, training a substitute model for adversarial attacks has attracted wide attention. Previous substitute training approaches focus on stealing the knowledge of the target model based on real training data or synthetic data, without exploring what kind of data can further improve the transferability between the substitute and target models. In this paper, we propose a novel perspective substitute training that focuses on designing the distribution of data used in the knowledge stealing process. More specifically, a diverse data generation module is proposed to synthesize large-scale data with wide distribution. And adversarial substitute training strategy is introduced to focus on the data distributed near the decision boundary. The combination of these two modules can further boost the consistency of the substitute model and target model, which greatly improves the effectiveness of adversarial attack. Extensive experiments demonstrate the efficacy of our method against state-of-the-art competitors under non-target and target attack settings. Detailed visualization and analysis are also provided to help understand the advantage of our method.
Towards Interpretable Face Recognition
May 02, 2018
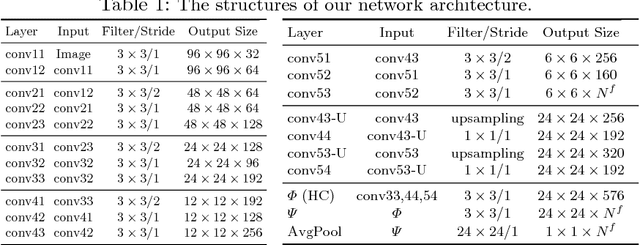
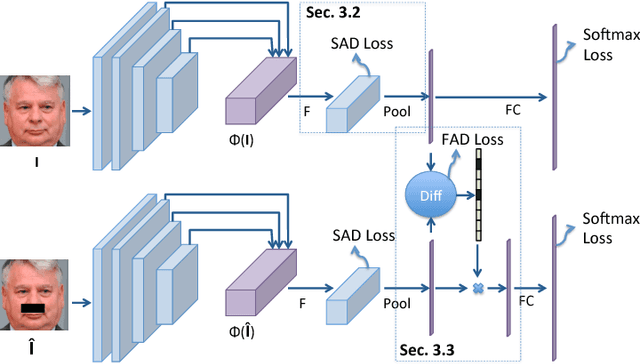
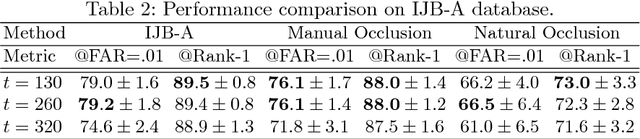
Deep CNNs have been pushing the frontier of visual recognition over past years. Besides recognition accuracy, strong demands in understanding deep CNNs in the research community motivate developments of tools to dissect pre-trained models to visualize how they make predictions. Recent works further push the interpretability in the network learning stage to learn more meaningful representations. In this work, focusing on a specific area of visual recognition, we report our efforts towards interpretable face recognition. We propose a spatial activation diversity loss to learn more structured face representations. By leveraging the structure, we further design a feature activation diversity loss to push the interpretable representations to be discriminative and robust to occlusions. We demonstrate on three face recognition benchmarks that our proposed method is able to improve face recognition accuracy with easily interpretable face representations.