 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssemblyHands: Towards Egocentric Activity Understanding via 3D Hand Pose Estimation
Apr 24, 2023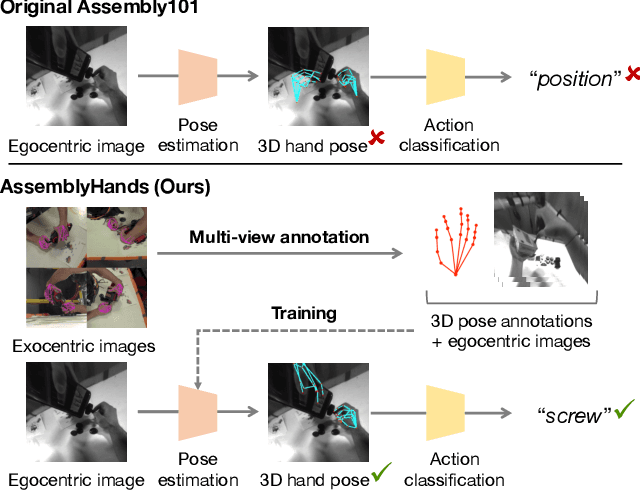
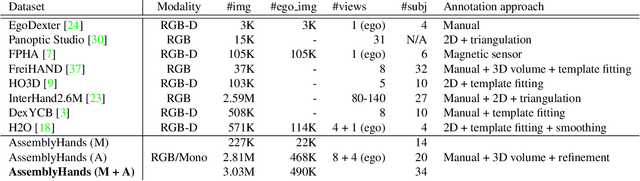
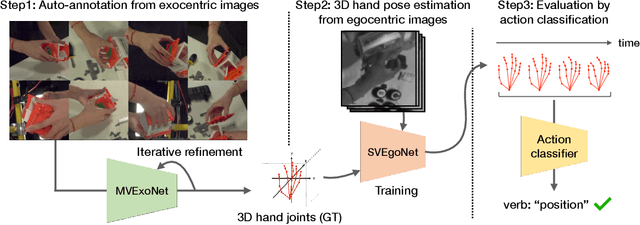
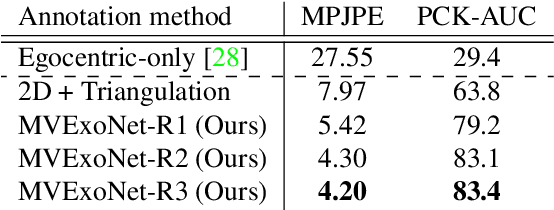
We present AssemblyHands, a large-scale benchmark dataset with accurate 3D hand pose annotations, to facilitate the study of egocentric activities with challenging hand-object interactions. The dataset includes synchronized egocentric and exocentric images sampled from the recent Assembly101 dataset, in which participants assemble and disassemble take-apart toys. To obtain high-quality 3D hand pose annotations for the egocentric images, we develop an efficient pipeline, where we use an initial set of manual annotations to train a model to automatically annotate a much larger dataset. Our annotation model uses multi-view feature fusion and an iterative refinement scheme, and achieves an average keypoint error of 4.20 mm, which is 85% lower than the error of the original annotations in Assembly101. AssemblyHands provides 3.0M annotated images, including 490K egocentric images, making it the largest existing benchmark dataset for egocentric 3D hand pose estimation. Using this data, we develop a strong single-view baseline of 3D hand pose estimation from egocentric images. Furthermore, we design a novel action classification task to evaluate predicted 3D hand poses. Our study shows that having higher-quality hand poses directly improves the ability to recognize actions.
In-Hand 3D Object Scanning from an RGB Sequence
Nov 28, 2022
We propose a method for in-hand 3D scanning of an unknown object from a sequence of color images. We cast the problem as reconstructing the object surface from un-posed multi-view images and rely on a neural implicit surface representation that captures both the geometry and the appearance of the object. By contrast with most NeRF-based methods, we do not assume that the camera-object relative poses are known and instead simultaneously optimize both the object shape and the pose trajectory. As global optimization over all the shape and pose parameters is prone to fail without coarse-level initialization of the poses, we propose an incremental approach which starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed. We incrementally reconstruct the object shape and track the object poses independently within each segment, and later merge all the segments by aligning poses estimated at the overlapping frames. Finally, we perform a global optimization over all the aligned segments to achieve full reconstruction. We experimentally show that the proposed method is able to reconstruct the shape and color of both textured and challenging texture-less objects, outperforms classical methods that rely only on appearance features, and its performance is close to recent methods that assume known camera poses.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022
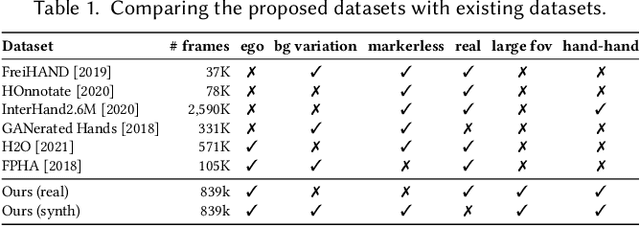
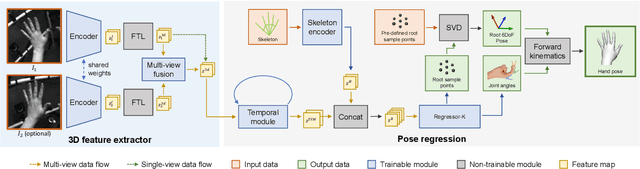
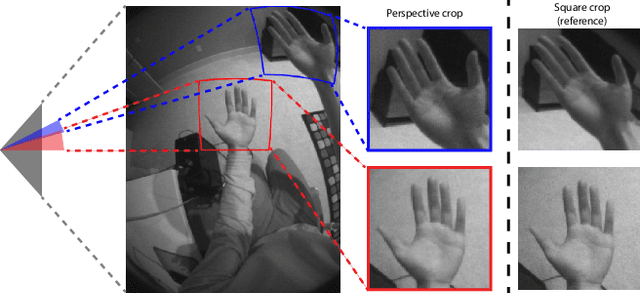
Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
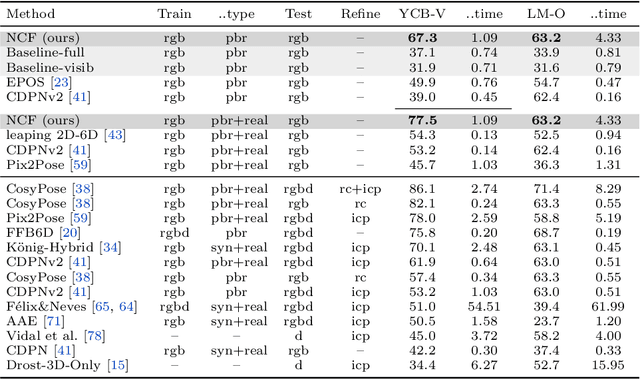
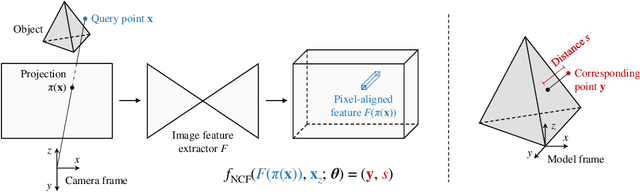
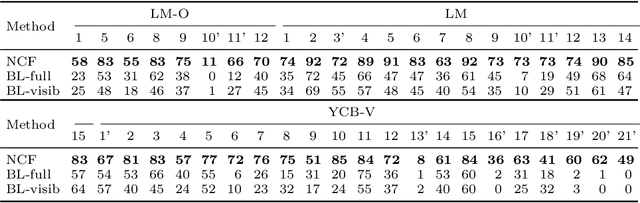
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
Fully Understanding Generic Objects: Modeling, Segmentation, and Reconstruction
Apr 02, 2021
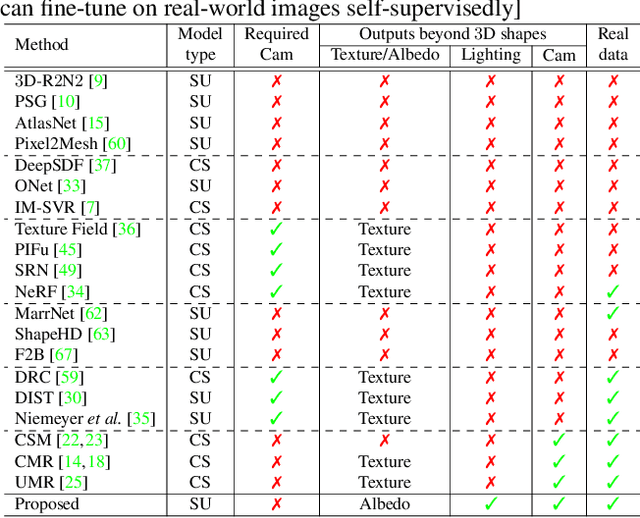

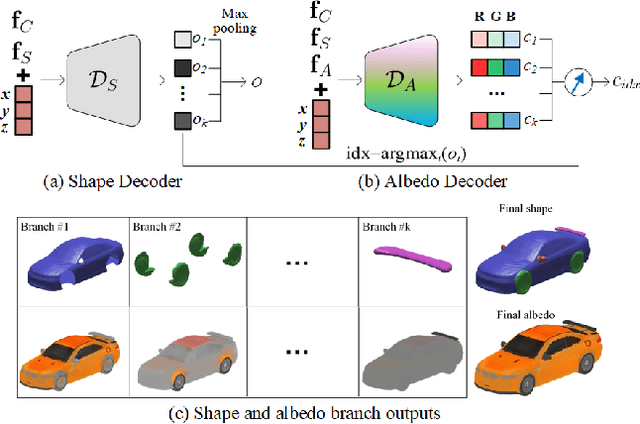
Inferring 3D structure of a generic object from a 2D image is a long-standing objective of computer vision. Conventional approaches either learn completely from CAD-generated synthetic data, which have difficulty in inference from real images, or generate 2.5D depth image via intrinsic decomposition, which is limited compared to the full 3D reconstruction. One fundamental challenge lies in how to leverage numerous real 2D images without any 3D ground truth. To address this issue, we take an alternative approach with semi-supervised learning. That is, for a 2D image of a generic object, we decompose it into latent representations of category, shape and albedo, lighting and camera projection matrix, decode the representations to segmented 3D shape and albedo respectively, and fuse these components to render an image well approximating the input image. Using a category-adaptive 3D joint occupancy field (JOF), we show that the complete shape and albedo modeling enables us to leverage real 2D images in both modeling and model fitting. The effectiveness of our approach is demonstrated through superior 3D reconstruction from a single image, being either synthetic or real, and shape segmentation.
On Learning Disentangled Representations for Gait Recognition
Sep 05, 2019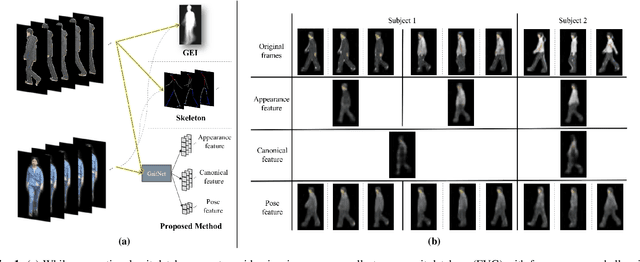



Gait, the walking pattern of individuals, is one of the important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and viewing angle. To remedy this issue, we propose a novel AutoEncoder framework, GaitNet, to explicitly disentangle appearance, canonical and pose features from RGB imagery. The LSTM integrates pose features over time as a dynamic gait feature while canonical features are averaged as a static gait feature. Both of them are utilized as classification features. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF, and FVG datasets, our method demonstrates superior performance to the SOTA quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency. We further compare our GaitNet with state-of-the-art face recognition to demonstrate the advantages of gait biometrics identification under certain scenarios, e.g., long distance/lower resolutions, cross viewing angles.
Towards High-fidelity Nonlinear 3D Face Morphable Model
Apr 09, 2019

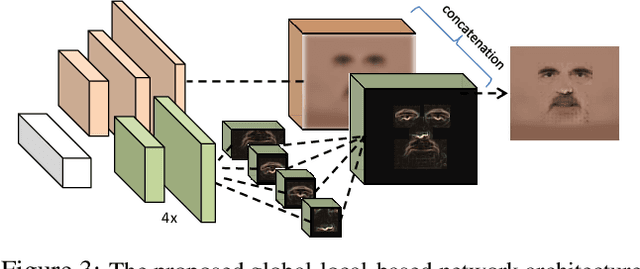

Embedding 3D morphable basis functions into deep neural networks opens great potential for models with better representation power. However, to faithfully learn those models from an image collection, it requires strong regularization to overcome ambiguities involved in the learning process. This critically prevents us from learning high fidelity face models which are needed to represent face images in high level of details. To address this problem, this paper presents a novel approach to learn additional proxies as means to side-step strong regularizations, as well as, leverages to promote detailed shape/albedo. To ease the learning, we also propose to use a dual-pathway network, a carefully-designed architecture that brings a balance between global and local-based models. By improving the nonlinear 3D morphable model in both learning objective and network architecture, we present a model which is superior in capturing higher level of details than the linear or its precedent nonlinear counterparts. As a result, our model achieves state-of-the-art performance on 3D face reconstruction by solely optimizing latent representations.
Gait Recognition via Disentangled Representation Learning
Apr 09, 2019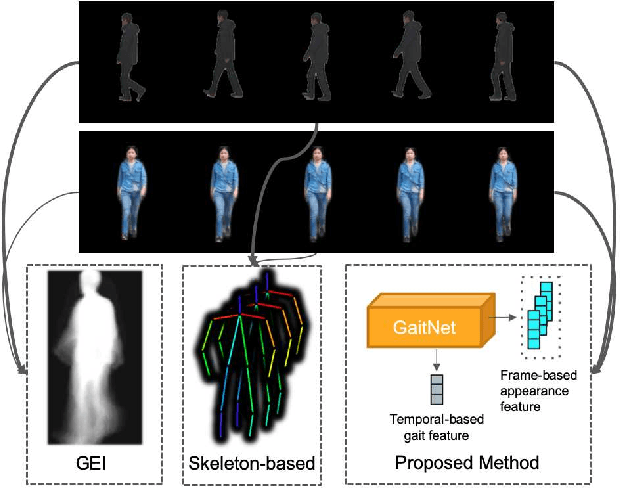


Gait, the walking pattern of individuals, is one of the most important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as the gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and view angle. To remedy this issue, we propose a novel AutoEncoder framework to explicitly disentangle pose and appearance features from RGB imagery and the LSTM-based integration of pose features over time produces the gait feature. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF and FVG datasets, our method demonstrates superior performance to the state of the arts quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency.
3D Face Modeling from Diverse Raw Scan Data
Feb 14, 2019


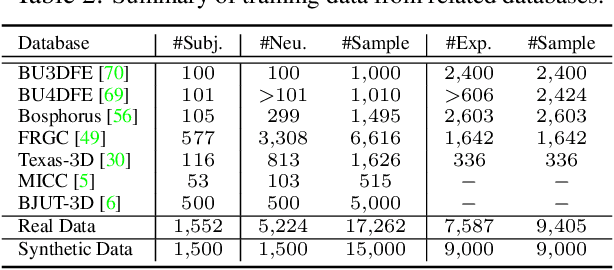
Traditional 3D models learn a latent representation of faces using linear subspaces from no more than 300 training scans of a single database. The main roadblock of building a large-scale face model from diverse 3D databases lies in the lack of dense correspondence among raw scans. To address these problems, this paper proposes an innovative framework to jointly learn a nonlinear face model from a diverse set of raw 3D scan databases and establish dense point-to-point correspondence among their scans. Specifically, by treating input raw scans as unorganized point clouds, we explore the use of PointNet architectures for converting point clouds to identity and expression feature representations, from which the decoder networks recover their 3D face shapes. Further, we propose a weakly supervised learning approach that does not require correspondence label for the scans. We demonstrate the superior dense correspondence and representation power of our proposed method in shape and expression, and its contribution to single-image 3D face reconstruction.
Representation Learning by Rotating Your Faces
Sep 11, 2018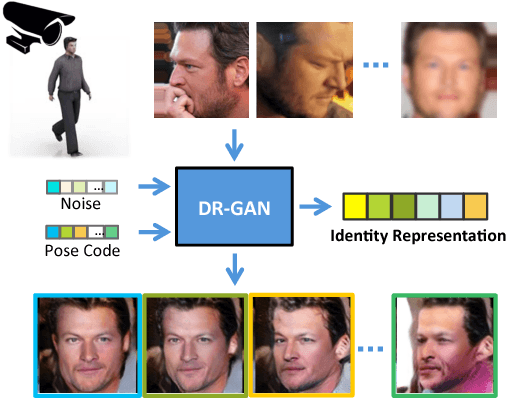


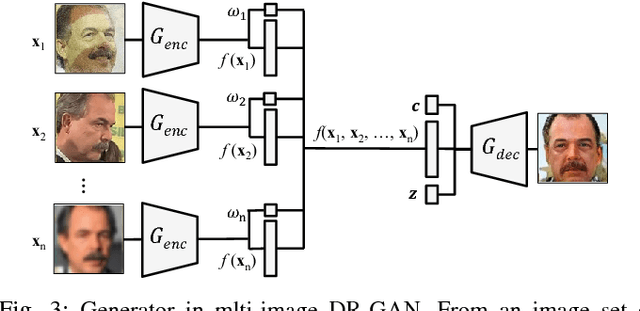
The large pose discrepancy between two face images is one of the fundamental challenges in automatic face recognition. Conventional approaches to pose-invariant face recognition either perform face frontalization on, or learn a pose-invariant representation from, a non-frontal face image. We argue that it is more desirable to perform both tasks jointly to allow them to leverage each other. To this end, this paper proposes a Disentangled Representation learning-Generative Adversarial Network (DR-GAN) with three distinct novelties. First, the encoder-decoder structure of the generator enables DR-GAN to learn a representation that is both generative and discriminative, which can be used for face image synthesis and pose-invariant face recognition. Second, this representation is explicitly disentangled from other face variations such as pose, through the pose code provided to the decoder and pose estimation in the discriminator. Third, DR-GAN can take one or multiple images as the input, and generate one unified identity representation along with an arbitrary number of synthetic face images. Extensive quantitative and qualitative evaluation on a number of controlled and in-the-wild databases demonstrate the superiority of DR-GAN over the state of the art in both learning representations and rotating large-pose face images.