 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Generation for Underactuated Soft Robot Manipulators using Discrete Elastic Rod Dynamics
Mar 23, 2026Soft robots are well suited for contact-rich tasks due to their compliance, yet this property makes accurate and tractable modeling challenging. Planning motions with dynamically-feasible trajectories requires models that capture arbitrary deformations, remain computationally efficient, and are compatible with underactuation. However, existing approaches balance these properties unevenly: continuum rod models provide physical accuracy but are computationally demanding, while reduced-order approximations improve efficiency at the cost of modeling fidelity. To address this, our work introduces a control-oriented reformulation of Discrete Elastic Rod (DER) dynamics for soft robots, and a method to generate trajectories with these dynamics. The proposed formulation yields a control-affine representation while preserving certain first-principles force-deformation relationships. As a result, the generated trajectories are both dynamically feasible and consistent with the underlying actuation assumptions. We present our trajectory generation framework and validate it experimentally on a pneumatic soft robotic limb. Hardware results demonstrate consistently improved trajectory tracking performance over a constant-curvature-based baseline, particularly under complex actuation conditions.
Explore the difficulty of words and its influential attributes based on the Wordle game
May 03, 2023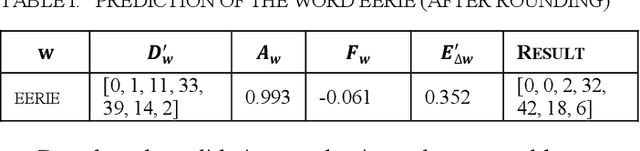

We adopt the distribution and expectation of guessing times in game Wordle as metrics to predict the difficulty of words and explore their influence factors. In order to predictthe difficulty distribution, we use Monte Carlo to simulate the guessing process of players and then narrow the gap between raw and actual distribution of guessing times for each word with Markov which generates the associativity of words. Afterwards, we take advantage of lasso regression to predict the deviation of guessing times expectation and quadratic programming to obtain the correction of the original distribution.To predict the difficulty levels, we first use hierarchical clustering to classify the difficulty levels based on the expectation of guessing times. Afterwards we downscale the variables of lexical attributes based on factor analysis. Significant factors include the number of neighboring words, letter similarity, sub-string similarity, and word frequency. Finally, we build the relationship between lexical attributes and difficulty levels through ordered logistic regression.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022
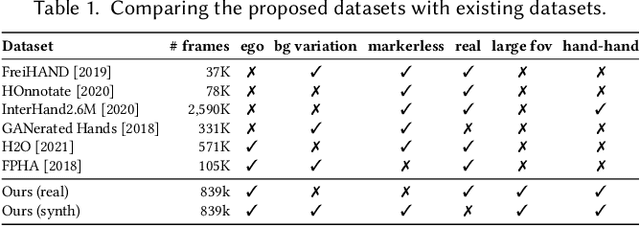
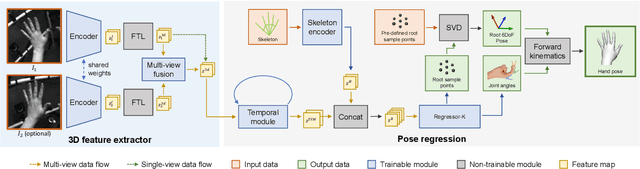
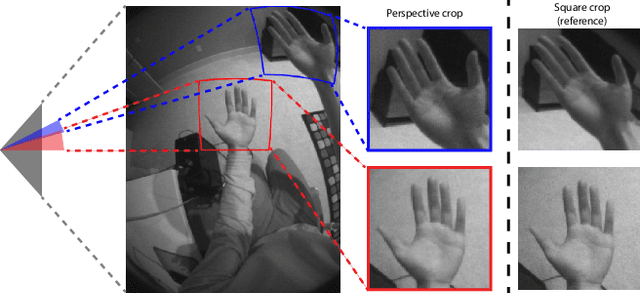
Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Two-Stream Compare and Contrast Network for Vertebral Compression Fracture Diagnosis
Oct 13, 2020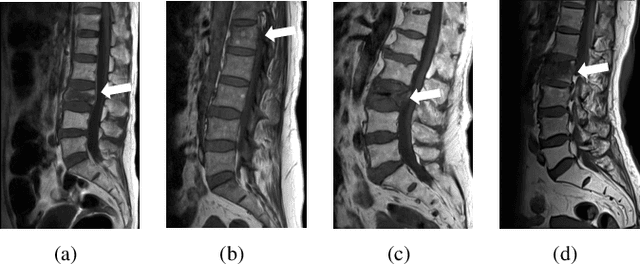
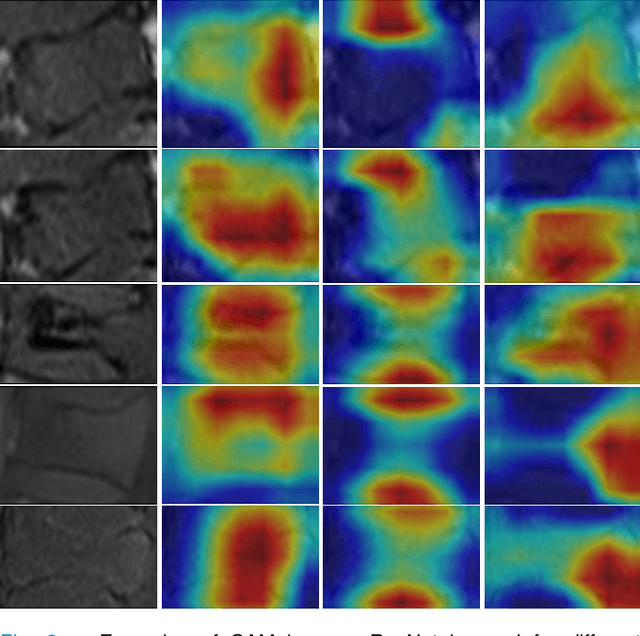
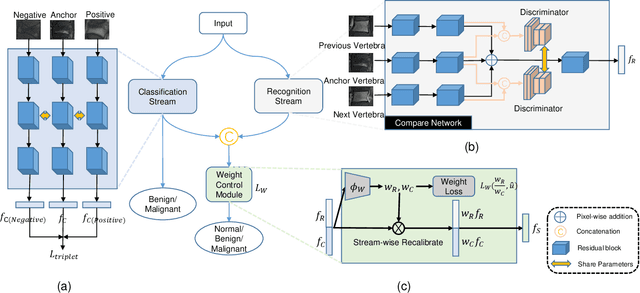
Differentiating Vertebral Compression Fractures (VCFs) associated with trauma and osteoporosis (benign VCFs) or those caused by metastatic cancer (malignant VCFs) are critically important for treatment decisions. So far, automatic VCFs diagnosis is solved in a two-step manner, i.e. first identify VCFs and then classify it into benign or malignant. In this paper, we explore to model VCFs diagnosis as a three-class classification problem, i.e. normal vertebrae, benign VCFs, and malignant VCFs. However, VCFs recognition and classification require very different features, and both tasks are characterized by high intra-class variation and high inter-class similarity. Moreover, the dataset is extremely class-imbalanced. To address the above challenges, we propose a novel Two-Stream Compare and Contrast Network (TSCCN) for VCFs diagnosis. This network consists of two streams, a recognition stream which learns to identify VCFs through comparing and contrasting between adjacent vertebra, and a classification stream which compares and contrasts between intra-class and inter-class to learn features for fine-grained classification. The two streams are integrated via a learnable weight control module which adaptively sets their contribution. The TSCCN is evaluated on a dataset consisting of 239 VCFs patients and achieves the average sensitivity and specificity of 92.56\% and 96.29\%, respectively.
Variational Representation Learning for Vehicle Re-Identification
May 07, 2019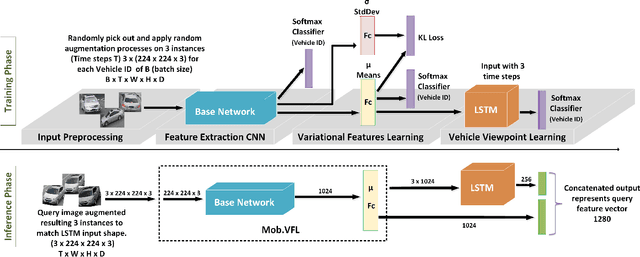
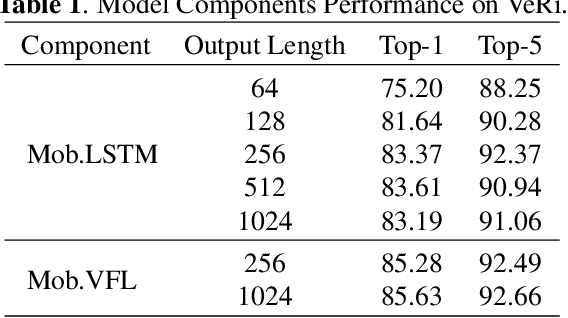
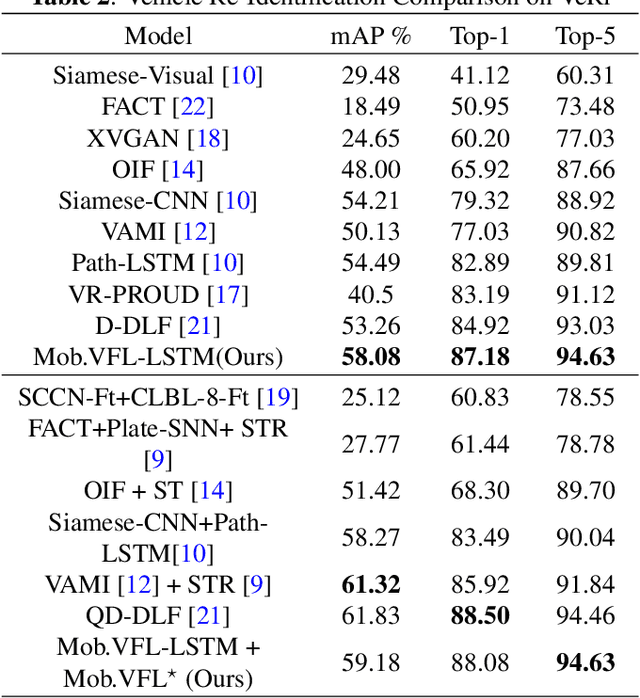
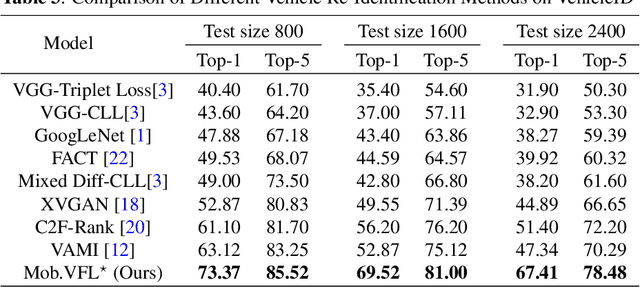
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as 256, experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays as an encoder to downsize the features.