 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore the difficulty of words and its influential attributes based on the Wordle game
Paper and Code
May 03, 2023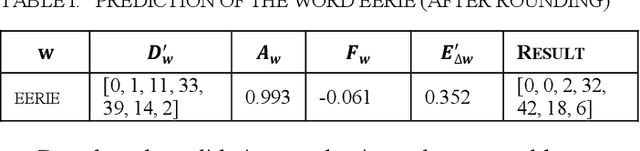

We adopt the distribution and expectation of guessing times in game Wordle as metrics to predict the difficulty of words and explore their influence factors. In order to predictthe difficulty distribution, we use Monte Carlo to simulate the guessing process of players and then narrow the gap between raw and actual distribution of guessing times for each word with Markov which generates the associativity of words. Afterwards, we take advantage of lasso regression to predict the deviation of guessing times expectation and quadratic programming to obtain the correction of the original distribution.To predict the difficulty levels, we first use hierarchical clustering to classify the difficulty levels based on the expectation of guessing times. Afterwards we downscale the variables of lexical attributes based on factor analysis. Significant factors include the number of neighboring words, letter similarity, sub-string similarity, and word frequency. Finally, we build the relationship between lexical attributes and difficulty levels through ordered logistic regression.