 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dual Support Vector Data Description for Anomaly Detection on Attributed Networks
Sep 01, 2021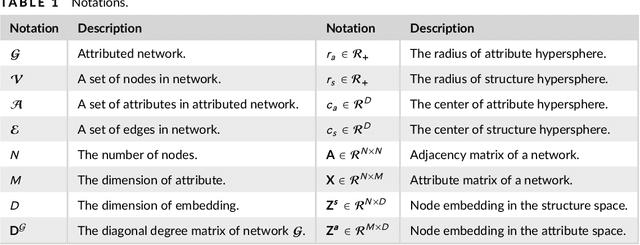
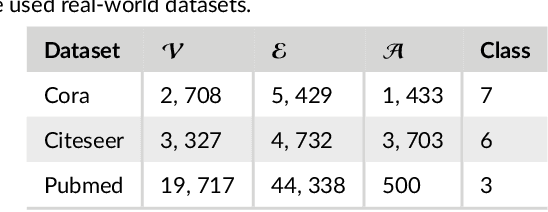
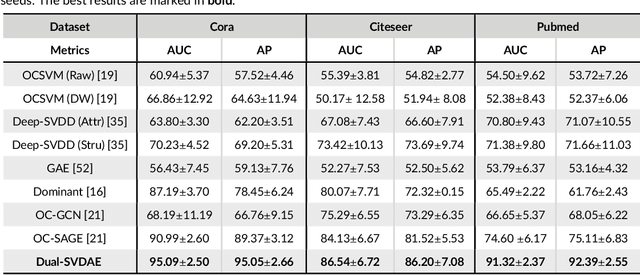
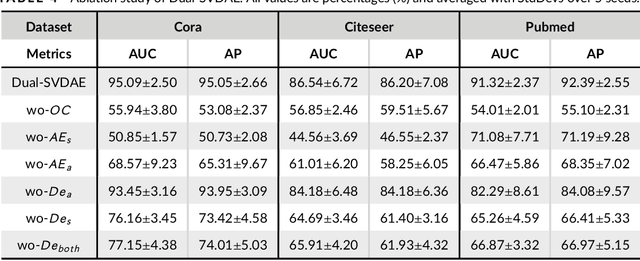
Networks are ubiquitous in the real world such as social networks and communication networks, and anomaly detection on networks aims at finding nodes whose structural or attributed patterns deviate significantly from the majority of reference nodes. However, most of the traditional anomaly detection methods neglect the relation structure information among data points and therefore cannot effectively generalize to the graph structure data. In this paper, we propose an end-to-end model of Deep Dual Support Vector Data description based Autoencoder (Dual-SVDAE) for anomaly detection on attributed networks, which considers both the structure and attribute for attributed networks. Specifically, Dual-SVDAE consists of a structure autoencoder and an attribute autoencoder to learn the latent representation of the node in the structure space and attribute space respectively. Then, a dual-hypersphere learning mechanism is imposed on them to learn two hyperspheres of normal nodes from the structure and attribute perspectives respectively. Moreover, to achieve joint learning between the structure and attribute of the network, we fuse the structure embedding and attribute embedding as the final input of the feature decoder to generate the node attribute. Finally, abnormal nodes can be detected by measuring the distance of nodes to the learned center of each hypersphere in the latent structure space and attribute space respectively. Extensive experiments on the real-world attributed networks show that Dual-SVDAE consistently outperforms the state-of-the-arts, which demonstrates the effectiveness of the proposed method.
Variational Representation Learning for Vehicle Re-Identification
May 07, 2019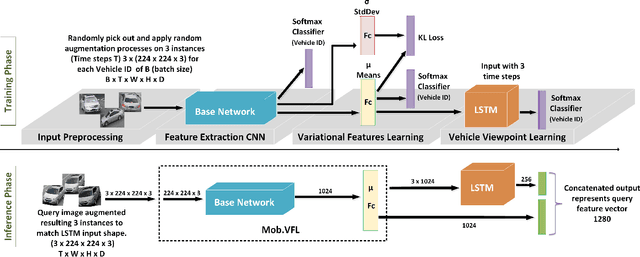
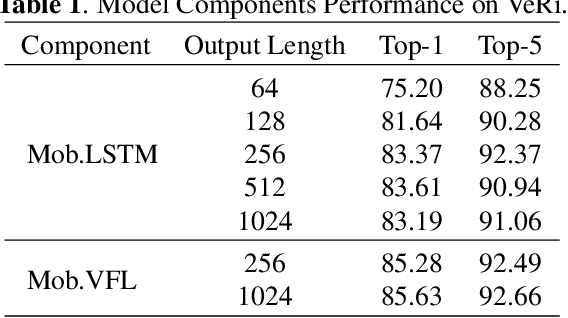
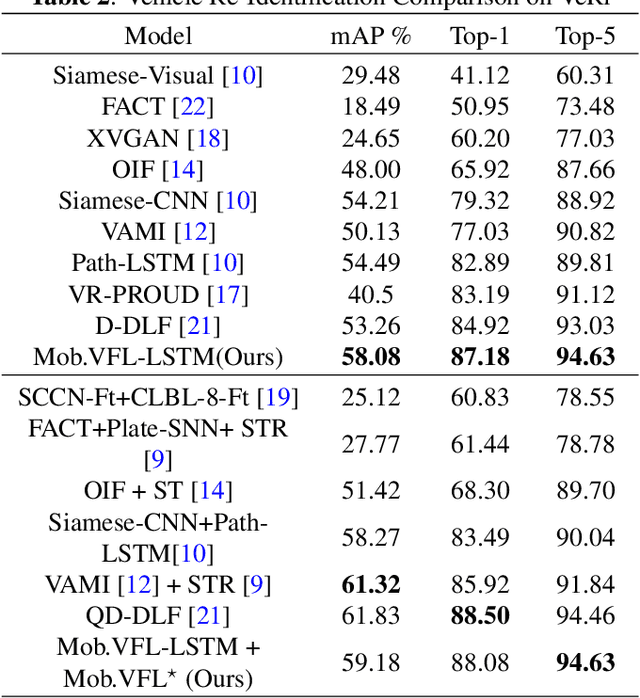
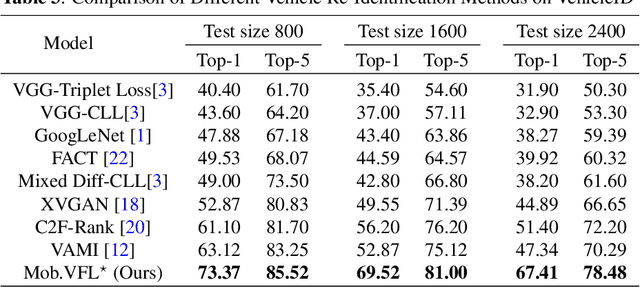
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as 256, experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays as an encoder to downsize the features.