 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning via Chain of Unconscious Thought
May 26, 2025Large Reasoning Models (LRMs) achieve promising performance but compromise token efficiency due to verbose reasoning processes. Unconscious Thought Theory (UTT) posits that complex problems can be solved more efficiently through internalized cognitive processes. Inspired by UTT, we propose a new reasoning paradigm, termed Chain of Unconscious Thought (CoUT), to improve the token efficiency of LRMs by guiding them to mimic human unconscious thought and internalize reasoning processes. Concretely, we first prompt the model to internalize the reasoning by thinking in the hidden layer. Then, we design a bag of token-efficient strategies to further help models reduce unnecessary tokens yet preserve the performance. Our work reveals that models may possess beneficial unconscious thought, enabling improved efficiency without sacrificing performance. Extensive experiments demonstrate the effectiveness of CoUT. Remarkably, it surpasses CoT by reducing token usage by 47.62% while maintaining comparable accuracy, as shown in Figure 1. The code of CoUT is available at this link: https://github.com/Rohan-GRH/CoUT
Class-aware and Augmentation-free Contrastive Learning from Label Proportion
Aug 13, 2024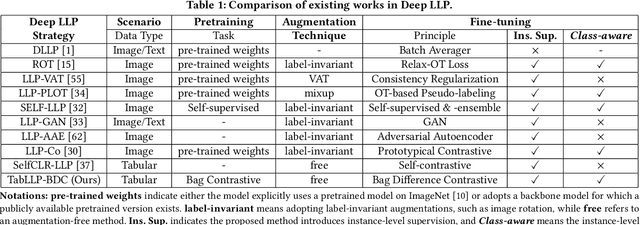
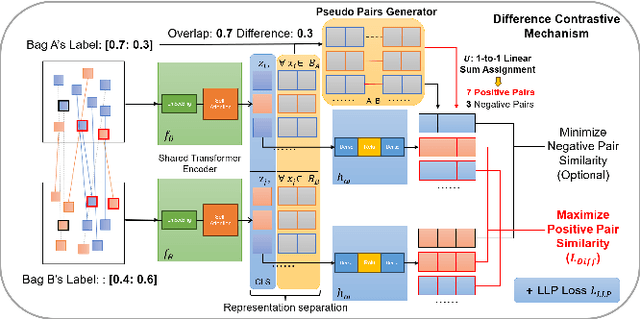
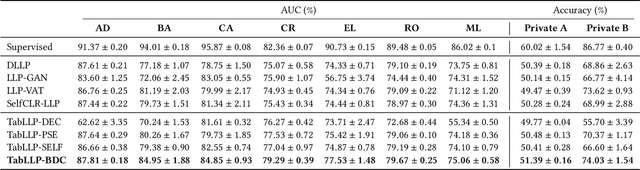
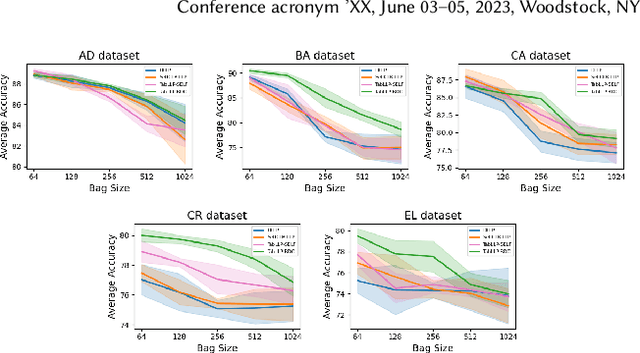
Learning from Label Proportion (LLP) is a weakly supervised learning scenario in which training data is organized into predefined bags of instances, disclosing only the class label proportions per bag. This paradigm is essential for user modeling and personalization, where user privacy is paramount, offering insights into user preferences without revealing individual data. LLP faces a unique difficulty: the misalignment between bag-level supervision and the objective of instance-level prediction, primarily due to the inherent ambiguity in label proportion matching. Previous studies have demonstrated deep representation learning can generate auxiliary signals to promote the supervision level in the image domain. However, applying these techniques to tabular data presents significant challenges: 1) they rely heavily on label-invariant augmentation to establish multi-view, which is not feasible with the heterogeneous nature of tabular datasets, and 2) tabular datasets often lack sufficient semantics for perfect class distinction, making them prone to suboptimality caused by the inherent ambiguity of label proportion matching. To address these challenges, we propose an augmentation-free contrastive framework TabLLP-BDC that introduces class-aware supervision (explicitly aware of class differences) at the instance level. Our solution features a two-stage Bag Difference Contrastive (BDC) learning mechanism that establishes robust class-aware instance-level supervision by disassembling the nuance between bag label proportions, without relying on augmentations. Concurrently, our model presents a pioneering multi-task pretraining pipeline tailored for tabular-based LLP, capturing intrinsic tabular feature correlations in alignment with label proportion distribution. Extensive experiments demonstrate that TabLLP-BDC achieves state-of-the-art performance for LLP in the tabular domain.
HouYi: An open-source large language model specially designed for renewable energy and carbon neutrality field
Jul 31, 2023Renewable energy is important for achieving carbon neutrality goal. With the great success of Large Language Models (LLMs) like ChatGPT in automatic content generation, LLMs are playing an increasingly important role. However, there has not been a specially designed LLM for renewable energy. Meanwhile, there has not been any dataset of renewable energy for training LLMs. Therefore, this paper published the first open-source Renewable Energy Academic Paper (REAP) dataset for non-commercial LLM research of renewable energy. REAP dataset is collected through searching the title and abstract of 1,168,970 academic literatures from Web of Science. Based on REAP dataset, HouYi model, the first LLM for renewable energy, is developed through finetuning general LLMs. HouYi demonstrated powerful academic paper paragraph generation ability in renewable energy field. Experiments show that its ability to generate academic papers on renewable energy is comparable to ChatGPT, slightly outperforms Claude, ERNIE Bot and SparkDesk, and significantly outperforms open-source LLaMA-13B model.
Deep Dual Support Vector Data Description for Anomaly Detection on Attributed Networks
Sep 01, 2021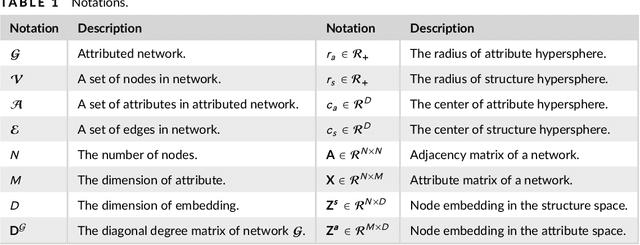
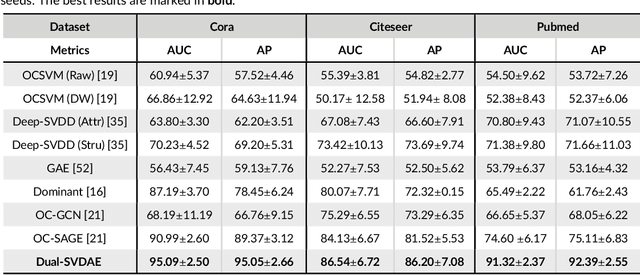
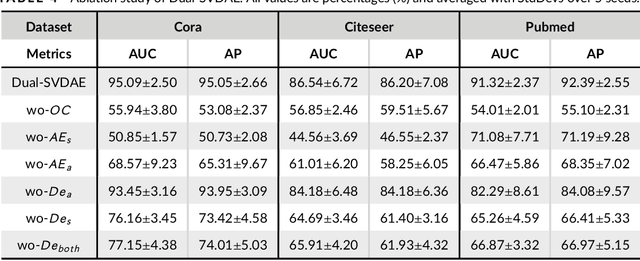
Networks are ubiquitous in the real world such as social networks and communication networks, and anomaly detection on networks aims at finding nodes whose structural or attributed patterns deviate significantly from the majority of reference nodes. However, most of the traditional anomaly detection methods neglect the relation structure information among data points and therefore cannot effectively generalize to the graph structure data. In this paper, we propose an end-to-end model of Deep Dual Support Vector Data description based Autoencoder (Dual-SVDAE) for anomaly detection on attributed networks, which considers both the structure and attribute for attributed networks. Specifically, Dual-SVDAE consists of a structure autoencoder and an attribute autoencoder to learn the latent representation of the node in the structure space and attribute space respectively. Then, a dual-hypersphere learning mechanism is imposed on them to learn two hyperspheres of normal nodes from the structure and attribute perspectives respectively. Moreover, to achieve joint learning between the structure and attribute of the network, we fuse the structure embedding and attribute embedding as the final input of the feature decoder to generate the node attribute. Finally, abnormal nodes can be detected by measuring the distance of nodes to the learned center of each hypersphere in the latent structure space and attribute space respectively. Extensive experiments on the real-world attributed networks show that Dual-SVDAE consistently outperforms the state-of-the-arts, which demonstrates the effectiveness of the proposed method.
Correlation-aware Deep Generative Model for Unsupervised Anomaly Detection
Feb 18, 2020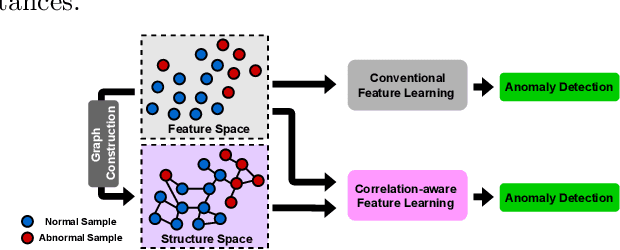
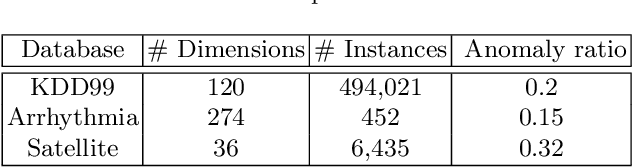
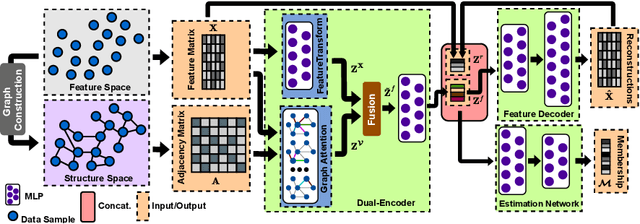
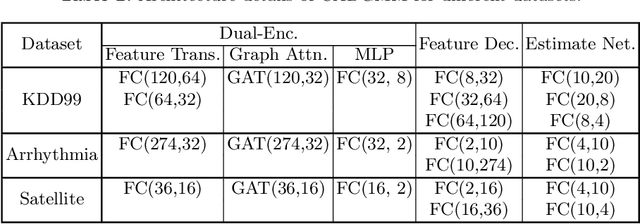
Unsupervised anomaly detection aims to identify anomalous samples from highly complex and unstructured data, which is pervasive in both fundamental research and industrial applications. However, most existing methods neglect the complex correlation among data samples, which is important for capturing normal patterns from which the abnormal ones deviate. In this paper, we propose a method of Correlation aware unsupervised Anomaly detection via Deep Gaussian Mixture Model (CADGMM), which captures the complex correlation among data points for high-quality low-dimensional representation learning. Specifically, the relations among data samples are correlated firstly in forms of a graph structure, in which, the node denotes the sample and the edge denotes the correlation between two samples from the feature space. Then, a dual-encoder that consists of a graph encoder and a feature encoder, is employed to encode both the feature and correlation information of samples into the low-dimensional latent space jointly, followed by a decoder for data reconstruction. Finally, a separate estimation network as a Gaussian Mixture Model is utilized to estimate the density of the learned latent vector, and the anomalies can be detected by measuring the energy of the samples. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed method.