 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-aware and Augmentation-free Contrastive Learning from Label Proportion
Paper and Code
Aug 13, 2024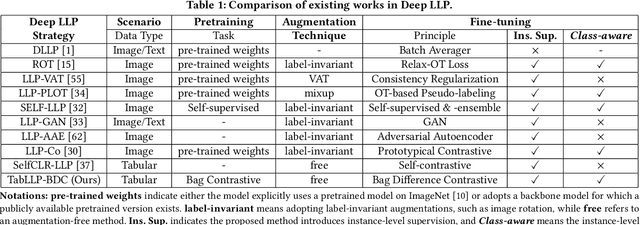
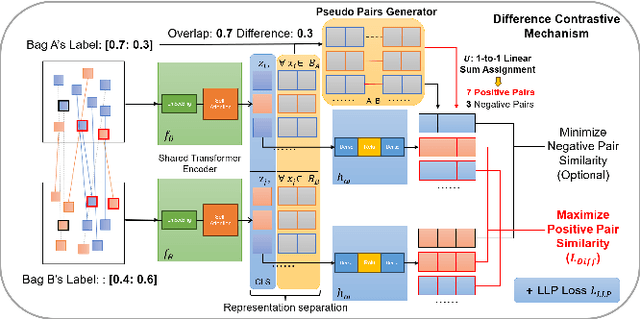
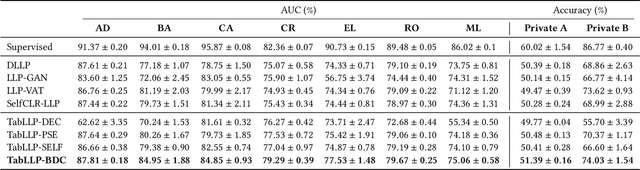
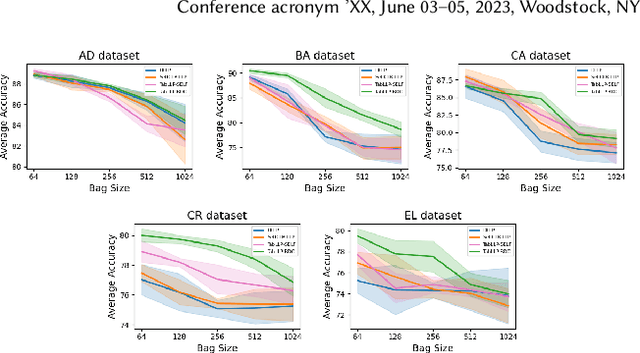
Learning from Label Proportion (LLP) is a weakly supervised learning scenario in which training data is organized into predefined bags of instances, disclosing only the class label proportions per bag. This paradigm is essential for user modeling and personalization, where user privacy is paramount, offering insights into user preferences without revealing individual data. LLP faces a unique difficulty: the misalignment between bag-level supervision and the objective of instance-level prediction, primarily due to the inherent ambiguity in label proportion matching. Previous studies have demonstrated deep representation learning can generate auxiliary signals to promote the supervision level in the image domain. However, applying these techniques to tabular data presents significant challenges: 1) they rely heavily on label-invariant augmentation to establish multi-view, which is not feasible with the heterogeneous nature of tabular datasets, and 2) tabular datasets often lack sufficient semantics for perfect class distinction, making them prone to suboptimality caused by the inherent ambiguity of label proportion matching. To address these challenges, we propose an augmentation-free contrastive framework TabLLP-BDC that introduces class-aware supervision (explicitly aware of class differences) at the instance level. Our solution features a two-stage Bag Difference Contrastive (BDC) learning mechanism that establishes robust class-aware instance-level supervision by disassembling the nuance between bag label proportions, without relying on augmentations. Concurrently, our model presents a pioneering multi-task pretraining pipeline tailored for tabular-based LLP, capturing intrinsic tabular feature correlations in alignment with label proportion distribution. Extensive experiments demonstrate that TabLLP-BDC achieves state-of-the-art performance for LLP in the tabular domain.