 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait Recognition via Disentangled Representation Learning
Apr 09, 2019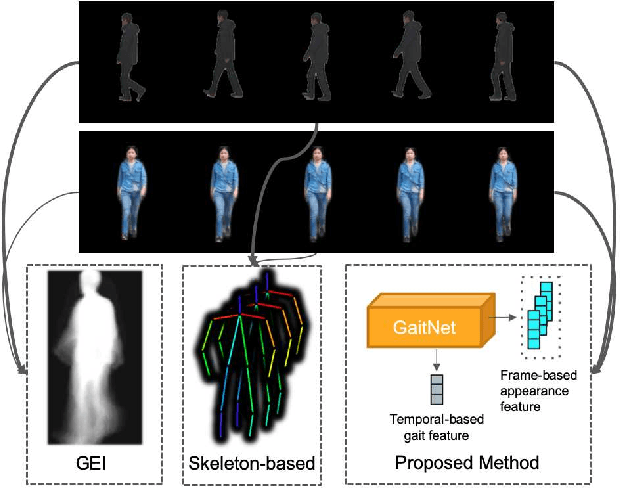

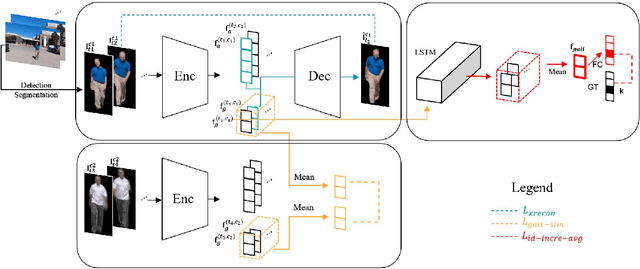

Gait, the walking pattern of individuals, is one of the most important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as the gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and view angle. To remedy this issue, we propose a novel AutoEncoder framework to explicitly disentangle pose and appearance features from RGB imagery and the LSTM-based integration of pose features over time produces the gait feature. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF and FVG datasets, our method demonstrates superior performance to the state of the arts quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency.
Temporally Robust Global Motion Compensation by Keypoint-based Congealing
Mar 12, 2016

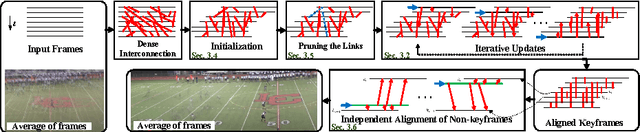
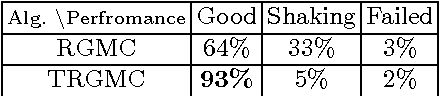
Global motion compensation (GMC) removes the impact of camera motion and creates a video in which the background appears static over the progression of time. Various vision problems, such as human activity recognition, background reconstruction, and multi-object tracking can benefit from GMC. Existing GMC algorithms rely on sequentially processing consecutive frames, by estimating the transformation mapping the two frames, and obtaining a composite transformation to a global motion compensated coordinate. Sequential GMC suffers from temporal drift of frames from the accurate global coordinate, due to either error accumulation or sporadic failures of motion estimation at a few frames. We propose a temporally robust global motion compensation (TRGMC) algorithm which performs accurate and stable GMC, despite complicated and long-term camera motion. TRGMC densely connects pairs of frames, by matching local keypoints of each frame. A joint alignment of these frames is formulated as a novel keypoint-based congealing problem, where the transformation of each frame is updated iteratively, such that the spatial coordinates for the start and end points of matched keypoints are identical. Experimental results demonstrate that TRGMC has superior performance in a wide range of scenarios.