 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Modeling from Diverse Raw Scan Data
Paper and Code



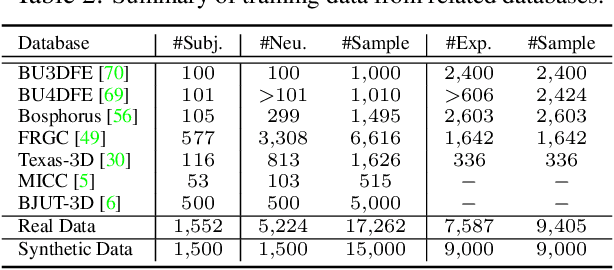
Traditional 3D models learn a latent representation of faces using linear subspaces from no more than 300 training scans of a single database. The main roadblock of building a large-scale face model from diverse 3D databases lies in the lack of dense correspondence among raw scans. To address these problems, this paper proposes an innovative framework to jointly learn a nonlinear face model from a diverse set of raw 3D scan databases and establish dense point-to-point correspondence among their scans. Specifically, by treating input raw scans as unorganized point clouds, we explore the use of PointNet architectures for converting point clouds to identity and expression feature representations, from which the decoder networks recover their 3D face shapes. Further, we propose a weakly supervised learning approach that does not require correspondence label for the scans. We demonstrate the superior dense correspondence and representation power of our proposed method in shape and expression, and its contribution to single-image 3D face reconstruction.