 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning by Rotating Your Faces
Paper and Code
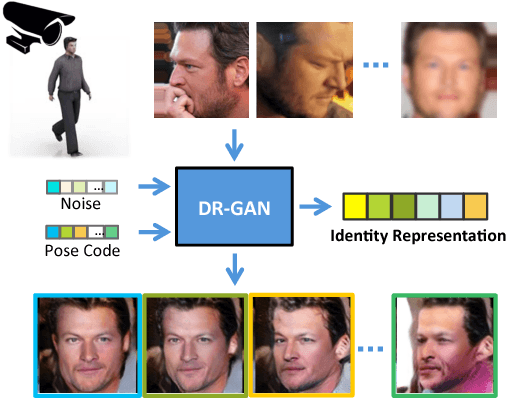


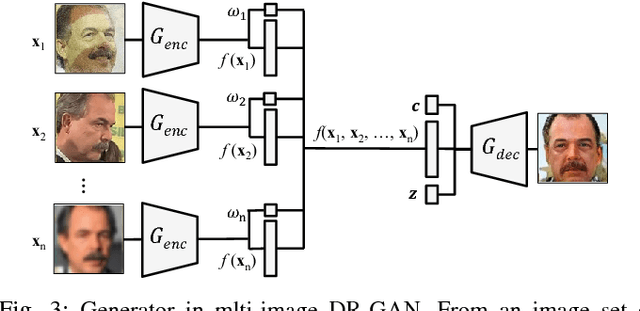
The large pose discrepancy between two face images is one of the fundamental challenges in automatic face recognition. Conventional approaches to pose-invariant face recognition either perform face frontalization on, or learn a pose-invariant representation from, a non-frontal face image. We argue that it is more desirable to perform both tasks jointly to allow them to leverage each other. To this end, this paper proposes a Disentangled Representation learning-Generative Adversarial Network (DR-GAN) with three distinct novelties. First, the encoder-decoder structure of the generator enables DR-GAN to learn a representation that is both generative and discriminative, which can be used for face image synthesis and pose-invariant face recognition. Second, this representation is explicitly disentangled from other face variations such as pose, through the pose code provided to the decoder and pose estimation in the discriminator. Third, DR-GAN can take one or multiple images as the input, and generate one unified identity representation along with an arbitrary number of synthetic face images. Extensive quantitative and qualitative evaluation on a number of controlled and in-the-wild databases demonstrate the superiority of DR-GAN over the state of the art in both learning representations and rotating large-pose face images.