 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Correspondence Field for Object Pose Estimation
Jul 30, 2022
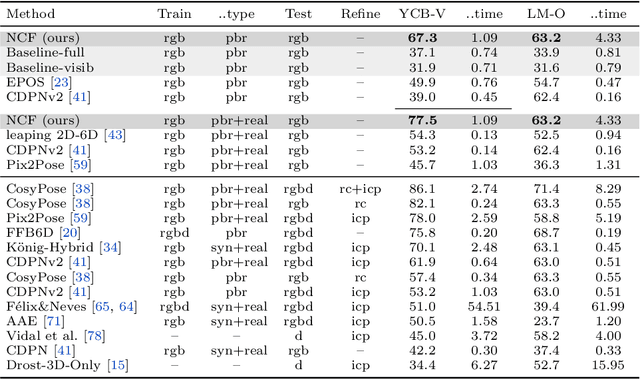
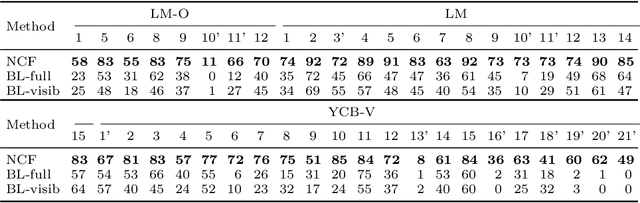
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
UNOC: Understanding Occlusion for Embodied Presence in Virtual Reality
Nov 12, 2020
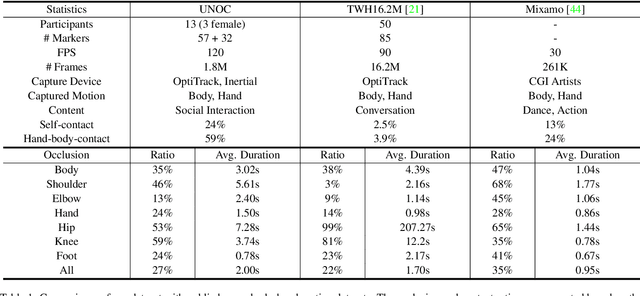


Tracking body and hand motions in the 3D space is essential for social and self-presence in augmented and virtual environments. Unlike the popular 3D pose estimation setting, the problem is often formulated as inside-out tracking based on embodied perception (e.g., egocentric cameras, handheld sensors). In this paper, we propose a new data-driven framework for inside-out body tracking, targeting challenges of omnipresent occlusions in optimization-based methods (e.g., inverse kinematics solvers). We first collect a large-scale motion capture dataset with both body and finger motions using optical markers and inertial sensors. This dataset focuses on social scenarios and captures ground truth poses under self-occlusions and body-hand interactions. We then simulate the occlusion patterns in head-mounted camera views on the captured ground truth using a ray casting algorithm and learn a deep neural network to infer the occluded body parts. In the experiments, we show that our method is able to generate high-fidelity embodied poses by applying the proposed method on the task of real-time inside-out body tracking, finger motion synthesis, and 3-point inverse kinematics.