 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNOC: Understanding Occlusion for Embodied Presence in Virtual Reality
Nov 12, 2020
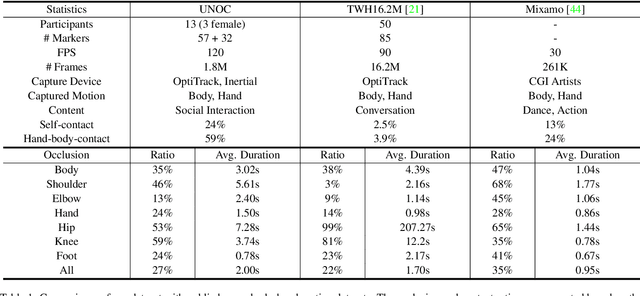


Tracking body and hand motions in the 3D space is essential for social and self-presence in augmented and virtual environments. Unlike the popular 3D pose estimation setting, the problem is often formulated as inside-out tracking based on embodied perception (e.g., egocentric cameras, handheld sensors). In this paper, we propose a new data-driven framework for inside-out body tracking, targeting challenges of omnipresent occlusions in optimization-based methods (e.g., inverse kinematics solvers). We first collect a large-scale motion capture dataset with both body and finger motions using optical markers and inertial sensors. This dataset focuses on social scenarios and captures ground truth poses under self-occlusions and body-hand interactions. We then simulate the occlusion patterns in head-mounted camera views on the captured ground truth using a ray casting algorithm and learn a deep neural network to infer the occluded body parts. In the experiments, we show that our method is able to generate high-fidelity embodied poses by applying the proposed method on the task of real-time inside-out body tracking, finger motion synthesis, and 3-point inverse kinematics.
Disentangling Pose from Appearance in Monochrome Hand Images
Apr 16, 2019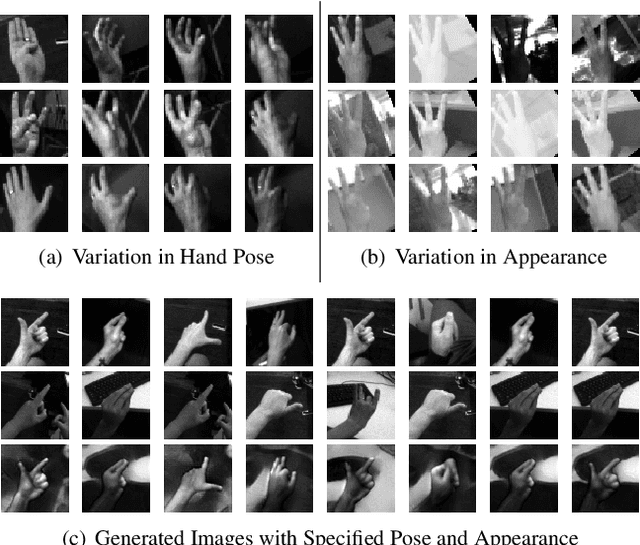



Hand pose estimation from the monocular 2D image is challenging due to the variation in lighting, appearance, and background. While some success has been achieved using deep neural networks, they typically require collecting a large dataset that adequately samples all the axes of variation of hand images. It would, therefore, be useful to find a representation of hand pose which is independent of the image appearance~(like hand texture, lighting, background), so that we can synthesize unseen images by mixing pose-appearance combinations. In this paper, we present a novel technique that disentangles the representation of pose from a complementary appearance factor in 2D monochrome images. We supervise this disentanglement process using a network that learns to generate images of hand using specified pose+appearance features. Unlike previous work, we do not require image pairs with a matching pose; instead, we use the pose annotations already available and introduce a novel use of cycle consistency to ensure orthogonality between the factors. Experimental results show that our self-disentanglement scheme successfully decomposes the hand image into the pose and its complementary appearance features of comparable quality as the method using paired data. Additionally, training the model with extra synthesized images with unseen hand-appearance combinations by re-mixing pose and appearance factors from different images can improve the 2D pose estimation performance.