 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^2$FG: Control Classifier-Free Guidance via Score Discrepancy Analysis
Mar 09, 2026Classifier-Free Guidance (CFG) is a cornerstone of modern conditional diffusion models, yet its reliance on the fixed or heuristic dynamic guidance weight is predominantly empirical and overlooks the inherent dynamics of the diffusion process. In this paper, we provide a rigorous theoretical analysis of the Classifier-Free Guidance. Specifically, we establish strict upper bounds on the score discrepancy between conditional and unconditional distributions at different timesteps based on the diffusion process. This finding explains the limitations of fixed-weight strategies and establishes a principled foundation for time-dependent guidance. Motivated by this insight, we introduce \textbf{Control Classifier-Free Guidance (C$^2$FG)}, a novel, training-free, and plug-in method that aligns the guidance strength with the diffusion dynamics via an exponential decay control function. Extensive experiments demonstrate that C$^2$FG is effective and broadly applicable across diverse generative tasks, while also exhibiting orthogonality to existing strategies.
AnimeAgent: Is the Multi-Agent via Image-to-Video models a Good Disney Storytelling Artist?
Feb 24, 2026Custom Storyboard Generation (CSG) aims to produce high-quality, multi-character consistent storytelling. Current approaches based on static diffusion models, whether used in a one-shot manner or within multi-agent frameworks, face three key limitations: (1) Static models lack dynamic expressiveness and often resort to "copy-paste" pattern. (2) One-shot inference cannot iteratively correct missing attributes or poor prompt adherence. (3) Multi-agents rely on non-robust evaluators, ill-suited for assessing stylized, non-realistic animation. To address these, we propose AnimeAgent, the first Image-to-Video (I2V)-based multi-agent framework for CSG. Inspired by Disney's "Combination of Straight Ahead and Pose to Pose" workflow, AnimeAgent leverages I2V's implicit motion prior to enhance consistency and expressiveness, while a mixed subjective-objective reviewer enables reliable iterative refinement. We also collect a human-annotated CSG benchmark with ground-truth. Experiments show AnimeAgent achieves SOTA performance in consistency, prompt fidelity, and stylization.
Revisiting Lightweight Low-Light Image Enhancement: From a YUV Color Space Perspective
Jan 24, 2026In the current era of mobile internet, Lightweight Low-Light Image Enhancement (L3IE) is critical for mobile devices, which faces a persistent trade-off between visual quality and model compactness. While recent methods employ disentangling strategies to simplify lightweight architectural design, such as Retinex theory and YUV color space transformations, their performance is fundamentally limited by overlooking channel-specific degradation patterns and cross-channel interactions. To address this gap, we perform a frequency-domain analysis that confirms the superiority of the YUV color space for L3IE. We identify a key insight: the Y channel primarily loses low-frequency content, while the UV channels are corrupted by high-frequency noise. Leveraging this finding, we propose a novel YUV-based paradigm that strategically restores channels using a Dual-Stream Global-Local Attention module for the Y channel, a Y-guided Local-Aware Frequency Attention module for the UV channels, and a Guided Interaction module for final feature fusion. Extensive experiments validate that our model establishes a new state-of-the-art on multiple benchmarks, delivering superior visual quality with a significantly lower parameter count.
Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
Dec 16, 2024



Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image's aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.
Feature Generation and Hypothesis Verification for Reliable Face Anti-Spoofing
Dec 30, 2021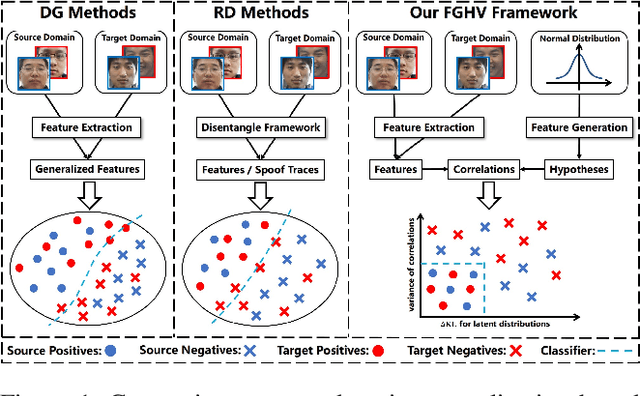
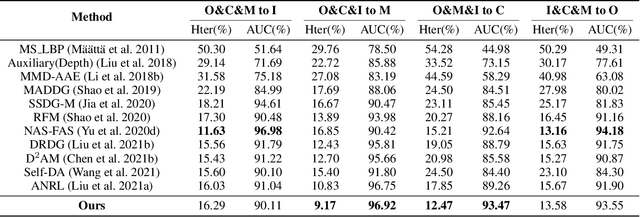
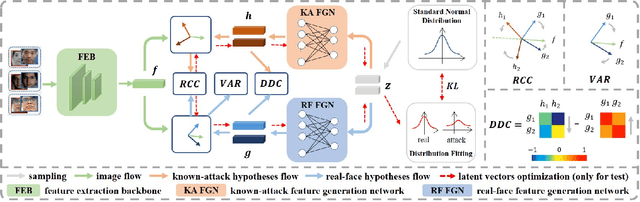
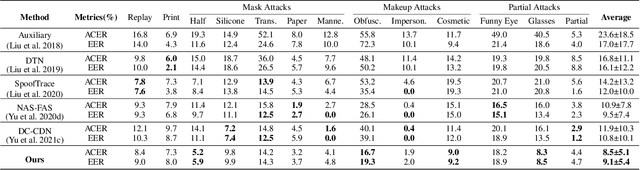
Although existing face anti-spoofing (FAS) methods achieve high accuracy in intra-domain experiments, their effects drop severely in cross-domain scenarios because of poor generalization. Recently, multifarious techniques have been explored, such as domain generalization and representation disentanglement. However, the improvement is still limited by two issues: 1) It is difficult to perfectly map all faces to a shared feature space. If faces from unknown domains are not mapped to the known region in the shared feature space, accidentally inaccurate predictions will be obtained. 2) It is hard to completely consider various spoof traces for disentanglement. In this paper, we propose a Feature Generation and Hypothesis Verification framework to alleviate the two issues. Above all, feature generation networks which generate hypotheses of real faces and known attacks are introduced for the first time in the FAS task. Subsequently, two hypothesis verification modules are applied to judge whether the input face comes from the real-face space and the real-face distribution respectively. Furthermore, some analyses of the relationship between our framework and Bayesian uncertainty estimation are given, which provides theoretical support for reliable defense in unknown domains. Experimental results show our framework achieves promising results and outperforms the state-of-the-art approaches on extensive public datasets.
Structure Destruction and Content Combination for Face Anti-Spoofing
Jul 22, 2021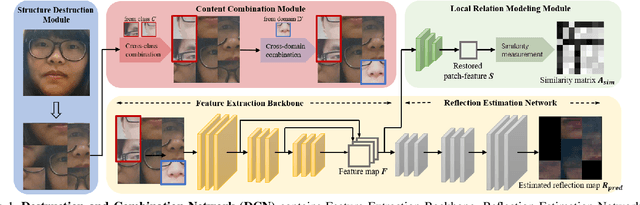
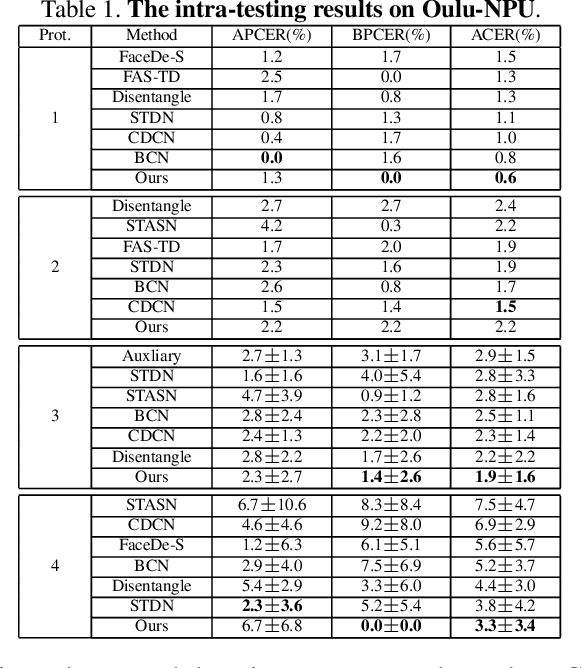
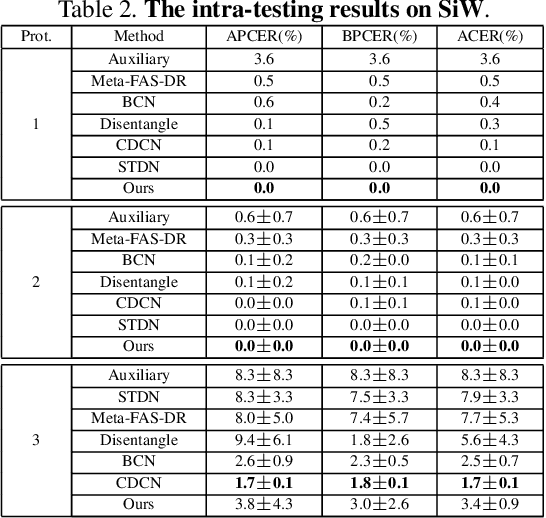

In pursuit of consolidating the face verification systems, prior face anti-spoofing studies excavate the hidden cues in original images to discriminate real persons and diverse attack types with the assistance of auxiliary supervision. However, limited by the following two inherent disturbances in their training process: 1) Complete facial structure in a single image. 2) Implicit subdomains in the whole dataset, these methods are prone to stick on memorization of the entire training dataset and show sensitivity to nonhomologous domain distribution. In this paper, we propose Structure Destruction Module and Content Combination Module to address these two imitations separately. The former mechanism destroys images into patches to construct a non-structural input, while the latter mechanism recombines patches from different subdomains or classes into a mixup construct. Based on this splitting-and-splicing operation, Local Relation Modeling Module is further proposed to model the second-order relationship between patches. We evaluate our method on extensive public datasets and promising experimental results to demonstrate the reliability of our method against state-of-the-art competitors.
PosNeg-Balanced Anchors with Aligned Features for Single-Shot Object Detection
Aug 09, 2019

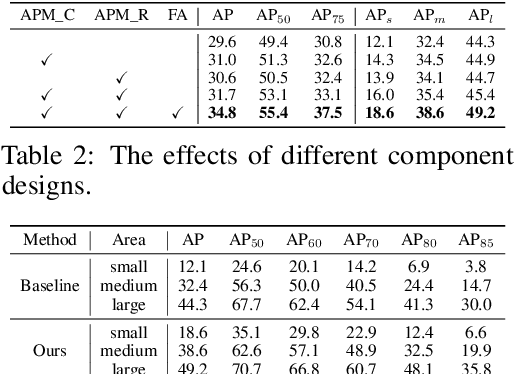
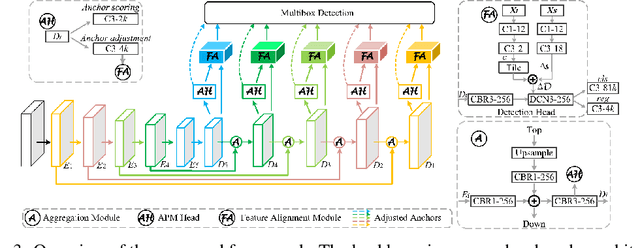
We introduce a novel single-shot object detector to ease the imbalance of foreground-background class by suppressing the easy negatives while increasing the positives. To achieve this, we propose an Anchor Promotion Module (APM) which predicts the probability of each anchor as positive and adjusts their initial locations and shapes to promote both the quality and quantity of positive anchors. In addition, we design an efficient Feature Alignment Module (FAM) to extract aligned features for fitting the promoted anchors with the help of both the location and shape transformation information from the APM. We assemble the two proposed modules to the backbone of VGG-16 and ResNet-101 network with an encoder-decoder architecture. Extensive experiments on MS COCO well demonstrate our model performs competitively with alternative methods (40.0\% mAP on \textit{test-dev} set) and runs faster (28.6 \textit{fps}).