 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
OneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
Sep 03, 2025
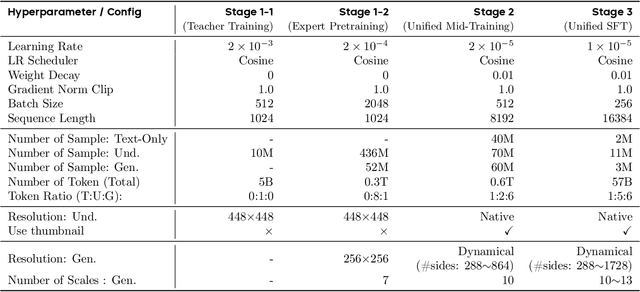


We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
Noise Conditional Variational Score Distillation
Jun 11, 2025
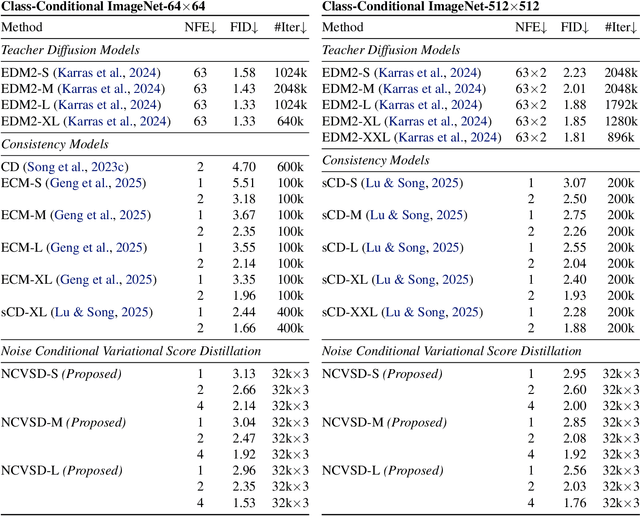
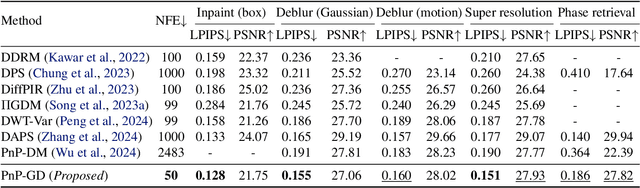

We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.
Improving Diffusion Models for Inverse Problems Using Optimal Posterior Covariance
Feb 03, 2024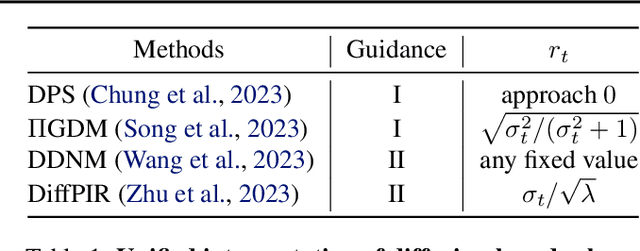
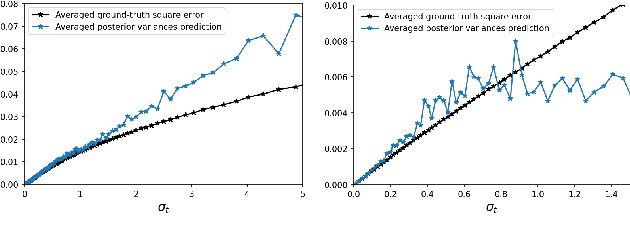
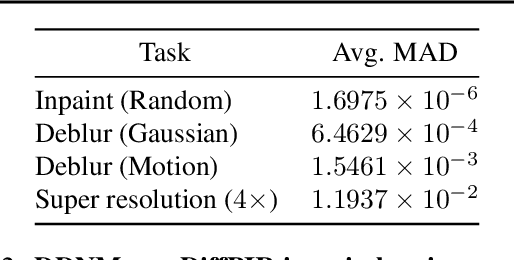

Recent diffusion models provide a promising zero-shot solution to noisy linear inverse problems without retraining for specific inverse problems. In this paper, we propose the first unified interpretation for existing zero-shot methods from the perspective of approximating the conditional posterior mean for the reverse diffusion process of conditional sampling. We reveal that recent methods are equivalent to making isotropic Gaussian approximations to intractable posterior distributions over clean images given diffused noisy images, with the only difference in the handcrafted design of isotropic posterior covariances. Inspired by this finding, we propose a general plug-and-play posterior covariance optimization based on maximum likelihood estimation to improve recent methods. To achieve optimal posterior covariance without retraining, we provide general solutions based on two approaches specifically designed to leverage pre-trained models with and without reverse covariances. Experimental results demonstrate that the proposed methods significantly enhance the overall performance or robustness to hyperparameters of recent methods. Code is available at https://github.com/xypeng9903/k-diffusion-inverse-problems
Drill the Cork of Information Bottleneck by Inputting the Most Important Data
May 15, 2021



Deep learning has become the most powerful machine learning tool in the last decade. However, how to efficiently train deep neural networks remains to be thoroughly solved. The widely used minibatch stochastic gradient descent (SGD) still needs to be accelerated. As a promising tool to better understand the learning dynamic of minibatch SGD, the information bottleneck (IB) theory claims that the optimization process consists of an initial fitting phase and the following compression phase. Based on this principle, we further study typicality sampling, an efficient data selection method, and propose a new explanation of how it helps accelerate the training process of the deep networks. We show that the fitting phase depicted in the IB theory will be boosted with a high signal-to-noise ratio of gradient approximation if the typicality sampling is appropriately adopted. Furthermore, this finding also implies that the prior information of the training set is critical to the optimization process and the better use of the most important data can help the information flow through the bottleneck faster. Both theoretical analysis and experimental results on synthetic and real-world datasets demonstrate our conclusions.
Accelerating Minibatch Stochastic Gradient Descent using Typicality Sampling
Mar 11, 2019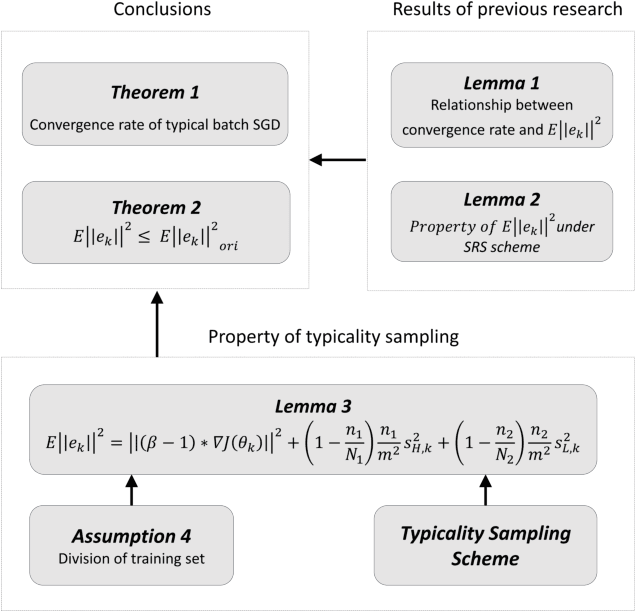
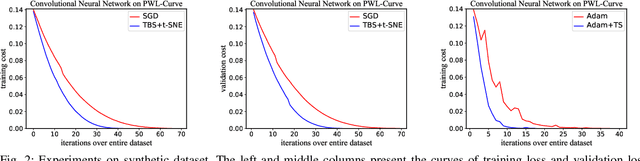
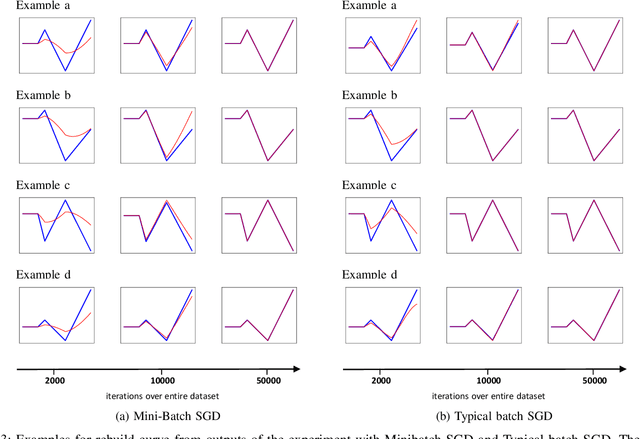
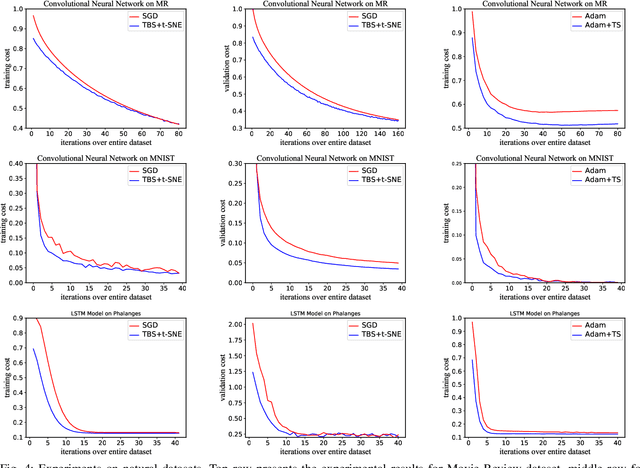
Machine learning, especially deep neural networks, has been rapidly developed in fields including computer vision, speech recognition and reinforcement learning. Although Mini-batch SGD is one of the most popular stochastic optimization methods in training deep networks, it shows a slow convergence rate due to the large noise in gradient approximation. In this paper, we attempt to remedy this problem by building more efficient batch selection method based on typicality sampling, which reduces the error of gradient estimation in conventional Minibatch SGD. We analyze the convergence rate of the resulting typical batch SGD algorithm and compare convergence properties between Minibatch SGD and the algorithm. Experimental results demonstrate that our batch selection scheme works well and more complex Minibatch SGD variants can benefit from the proposed batch selection strategy.