 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Minibatch Stochastic Gradient Descent using Typicality Sampling
Paper and Code
Mar 11, 2019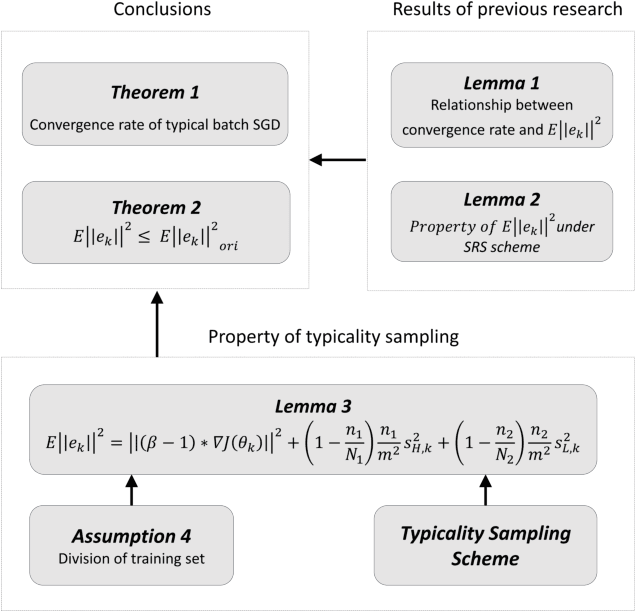
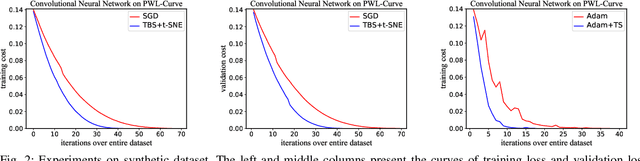
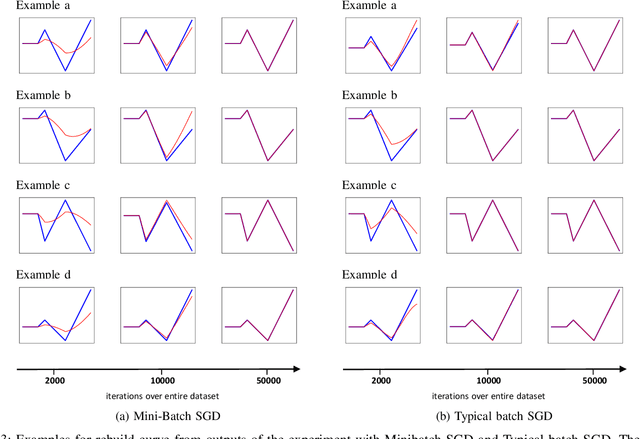
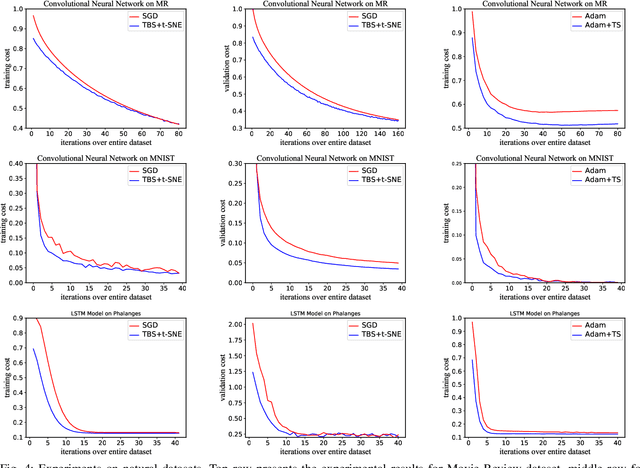
Machine learning, especially deep neural networks, has been rapidly developed in fields including computer vision, speech recognition and reinforcement learning. Although Mini-batch SGD is one of the most popular stochastic optimization methods in training deep networks, it shows a slow convergence rate due to the large noise in gradient approximation. In this paper, we attempt to remedy this problem by building more efficient batch selection method based on typicality sampling, which reduces the error of gradient estimation in conventional Minibatch SGD. We analyze the convergence rate of the resulting typical batch SGD algorithm and compare convergence properties between Minibatch SGD and the algorithm. Experimental results demonstrate that our batch selection scheme works well and more complex Minibatch SGD variants can benefit from the proposed batch selection strategy.