 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding
Paper and Code
Jan 18, 2024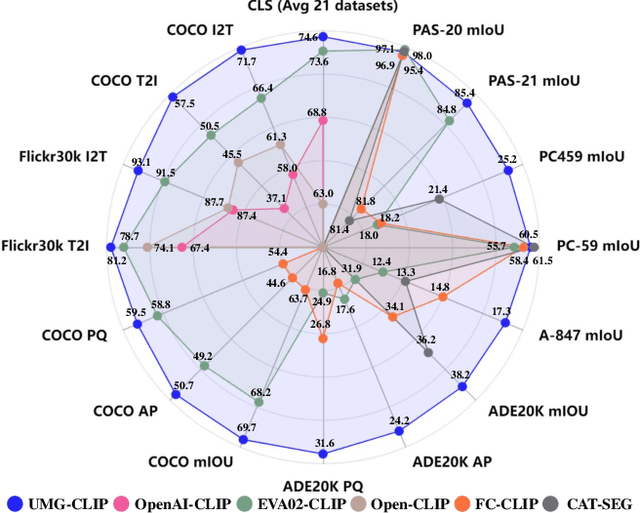
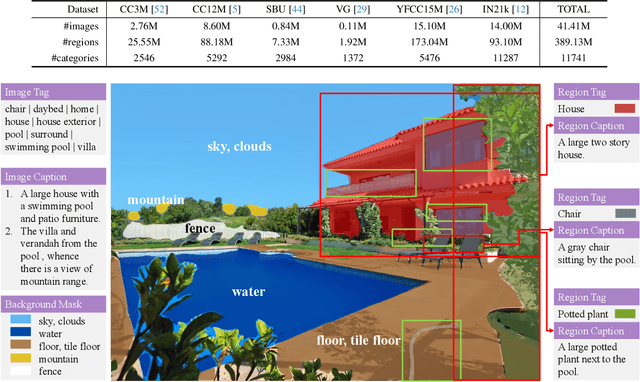
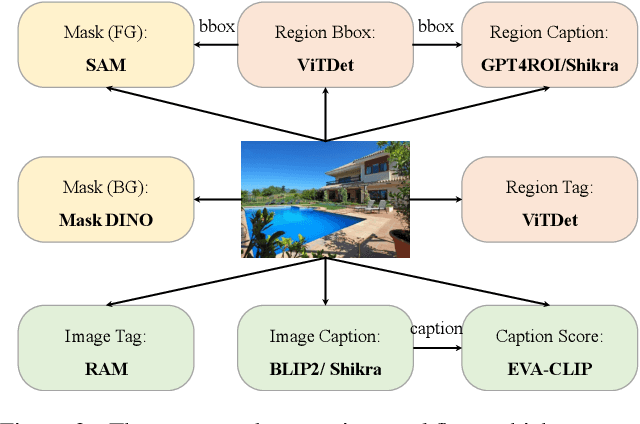
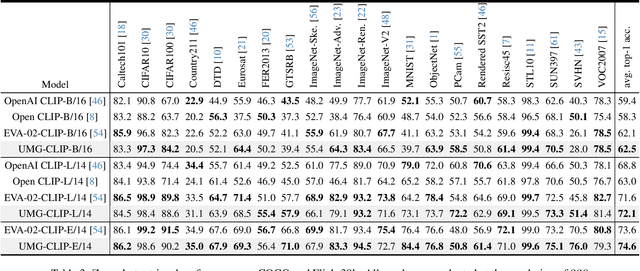
Vision-language foundation models, represented by Contrastive language-image pre-training (CLIP), have gained increasing attention for jointly understanding both vision and textual tasks. However, existing approaches primarily focus on training models to match global image representations with textual descriptions, thereby overlooking the critical alignment between local regions and corresponding text tokens. This paper extends CLIP with multi-granularity alignment. Notably, we deliberately construct a new dataset comprising pseudo annotations at various levels of granularities, encompassing image-level, region-level, and pixel-level captions/tags. Accordingly, we develop a unified multi-granularity learning framework, named UMG-CLIP, that simultaneously empowers the model with versatile perception abilities across different levels of detail. Equipped with parameter efficient tuning, UMG-CLIP surpasses current widely used CLIP models and achieves state-of-the-art performance on diverse image understanding benchmarks, including open-world recognition, retrieval, semantic segmentation, and panoptic segmentation tasks. We hope UMG-CLIP can serve as a valuable option for advancing vision-language foundation models.