 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unsupervised Gaze Representation via Eye Mask Driven Information Bottleneck
Jun 29, 2024



Appearance-based supervised methods with full-face image input have made tremendous advances in recent gaze estimation tasks. However, intensive human annotation requirement inhibits current methods from achieving industrial level accuracy and robustness. Although current unsupervised pre-training frameworks have achieved success in many image recognition tasks, due to the deep coupling between facial and eye features, such frameworks are still deficient in extracting useful gaze features from full-face. To alleviate above limitations, this work proposes a novel unsupervised/self-supervised gaze pre-training framework, which forces the full-face branch to learn a low dimensional gaze embedding without gaze annotations, through collaborative feature contrast and squeeze modules. In the heart of this framework is an alternating eye-attended/unattended masking training scheme, which squeezes gaze-related information from full-face branch into an eye-masked auto-encoder through an injection bottleneck design that successfully encourages the model to pays more attention to gaze direction rather than facial textures only, while still adopting the eye self-reconstruction objective. In the same time, a novel eye/gaze-related information contrastive loss has been designed to further boost the learned representation by forcing the model to focus on eye-centered regions. Extensive experimental results on several gaze benchmarks demonstrate that the proposed scheme achieves superior performances over unsupervised state-of-the-art.
Energy Attack: On Transferring Adversarial Examples
Sep 09, 2021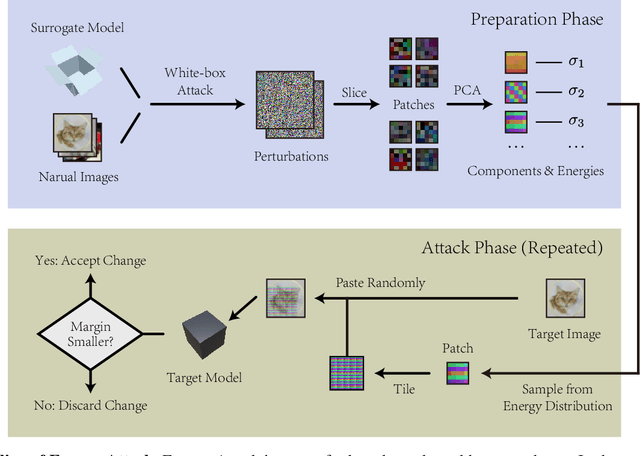

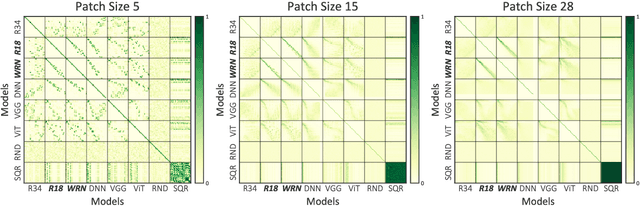
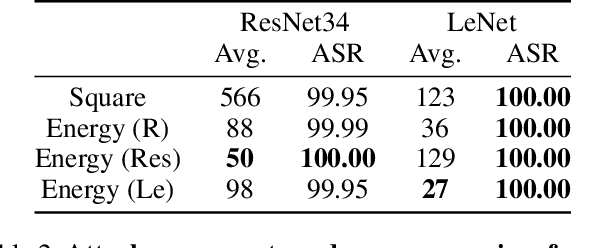
In this work we propose Energy Attack, a transfer-based black-box $L_\infty$-adversarial attack. The attack is parameter-free and does not require gradient approximation. In particular, we first obtain white-box adversarial perturbations of a surrogate model and divide these perturbations into small patches. Then we extract the unit component vectors and eigenvalues of these patches with principal component analysis (PCA). Base on the eigenvalues, we can model the energy distribution of adversarial perturbations. We then perform black-box attacks by sampling from the perturbation patches according to their energy distribution, and tiling the sampled patches to form a full-size adversarial perturbation. This can be done without the available access to victim models. Extensive experiments well demonstrate that the proposed Energy Attack achieves state-of-the-art performance in black-box attacks on various models and several datasets. Moreover, the extracted distribution is able to transfer among different model architectures and different datasets, and is therefore intrinsic to vision architectures.
MUSE: Multi-Scale Temporal Features Evolution for Knowledge Tracing
Jan 30, 2021


Transformer based knowledge tracing model is an extensively studied problem in the field of computer-aided education. By integrating temporal features into the encoder-decoder structure, transformers can processes the exercise information and student response information in a natural way. However, current state-of-the-art transformer-based variants still share two limitations. First, extremely long temporal features cannot well handled as the complexity of self-attention mechanism is O(n2). Second, existing approaches track the knowledge drifts under fixed a window size, without considering different temporal-ranges. To conquer these problems, we propose MUSE, which is equipped with multi-scale temporal sensor unit, that takes either local or global temporal features into consideration. The proposed model is capable to capture the dynamic changes in users knowledge states at different temporal-ranges, and provides an efficient and powerful way to combine local and global features to make predictions. Our method won the 5-th place over 3,395 teams in the Riiid AIEd Challenge 2020.
Learning Black-Box Attackers with Transferable Priors and Query Feedback
Oct 21, 2020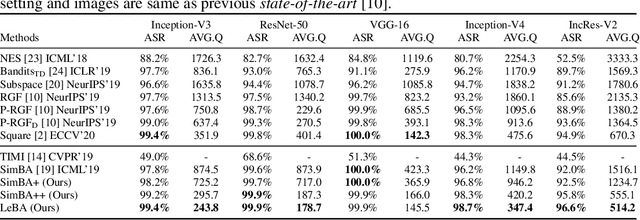

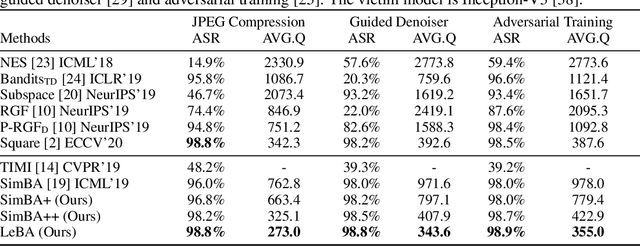

This paper addresses the challenging black-box adversarial attack problem, where only classification confidence of a victim model is available. Inspired by consistency of visual saliency between different vision models, a surrogate model is expected to improve the attack performance via transferability. By combining transferability-based and query-based black-box attack, we propose a surprisingly simple baseline approach (named SimBA++) using the surrogate model, which significantly outperforms several state-of-the-art methods. Moreover, to efficiently utilize the query feedback, we update the surrogate model in a novel learning scheme, named High-Order Gradient Approximation (HOGA). By constructing a high-order gradient computation graph, we update the surrogate model to approximate the victim model in both forward and backward pass. The SimBA++ and HOGA result in Learnable Black-Box Attack (LeBA), which surpasses previous state of the art by considerable margins: the proposed LeBA significantly reduces queries, while keeping higher attack success rates close to 100% in extensive ImageNet experiments, including attacking vision benchmarks and defensive models. Code is open source at https://github.com/TrustworthyDL/LeBA.