 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Image Conditioned 3D Generation
Mar 22, 2026High-quality 3D assets are essential for VR/AR, industrial design, and entertainment, motivating growing interest in generative models that create 3D content from user prompts. Most existing 3D generators, however, rely on a single conditioning modality: image-conditioned models achieve high visual fidelity by exploiting pixel-aligned cues but suffer from viewpoint bias when the input view is limited or ambiguous, while text-conditioned models provide broad semantic guidance yet lack low-level visual detail. This limits how users can express intent and raises a natural question: can these two modalities be combined for more flexible and faithful 3D generation? Our diagnostic study shows that even simple late fusion of text- and image-conditioned predictions outperforms single-modality models, revealing strong cross-modal complementarity. We therefore formalize Text-Image Conditioned 3D Generation, which requires joint reasoning over a visual exemplar and a textual specification. To address this task, we introduce TIGON, a minimalist dual-branch baseline with separate image- and text-conditioned backbones and lightweight cross-modal fusion. Extensive experiments show that text-image conditioning consistently improves over single-modality methods, highlighting complementary vision-language guidance as a promising direction for future 3D generation research. Project page: https://jumpat.github.io/tigon-page
Few-step Flow for 3D Generation via Marginal-Data Transport Distillation
Sep 04, 2025Flow-based 3D generation models typically require dozens of sampling steps during inference. Though few-step distillation methods, particularly Consistency Models (CMs), have achieved substantial advancements in accelerating 2D diffusion models, they remain under-explored for more complex 3D generation tasks. In this study, we propose a novel framework, MDT-dist, for few-step 3D flow distillation. Our approach is built upon a primary objective: distilling the pretrained model to learn the Marginal-Data Transport. Directly learning this objective needs to integrate the velocity fields, while this integral is intractable to be implemented. Therefore, we propose two optimizable objectives, Velocity Matching (VM) and Velocity Distillation (VD), to equivalently convert the optimization target from the transport level to the velocity and the distribution level respectively. Velocity Matching (VM) learns to stably match the velocity fields between the student and the teacher, but inevitably provides biased gradient estimates. Velocity Distillation (VD) further enhances the optimization process by leveraging the learned velocity fields to perform probability density distillation. When evaluated on the pioneer 3D generation framework TRELLIS, our method reduces sampling steps of each flow transformer from 25 to 1 or 2, achieving 0.68s (1 step x 2) and 0.94s (2 steps x 2) latency with 9.0x and 6.5x speedup on A800, while preserving high visual and geometric fidelity. Extensive experiments demonstrate that our method significantly outperforms existing CM distillation methods, and enables TRELLIS to achieve superior performance in few-step 3D generation.
Dereflection Any Image with Diffusion Priors and Diversified Data
Mar 21, 2025Reflection removal of a single image remains a highly challenging task due to the complex entanglement between target scenes and unwanted reflections. Despite significant progress, existing methods are hindered by the scarcity of high-quality, diverse data and insufficient restoration priors, resulting in limited generalization across various real-world scenarios. In this paper, we propose Dereflection Any Image, a comprehensive solution with an efficient data preparation pipeline and a generalizable model for robust reflection removal. First, we introduce a dataset named Diverse Reflection Removal (DRR) created by randomly rotating reflective mediums in target scenes, enabling variation of reflection angles and intensities, and setting a new benchmark in scale, quality, and diversity. Second, we propose a diffusion-based framework with one-step diffusion for deterministic outputs and fast inference. To ensure stable learning, we design a three-stage progressive training strategy, including reflection-invariant finetuning to encourage consistent outputs across varying reflection patterns that characterize our dataset. Extensive experiments show that our method achieves SOTA performance on both common benchmarks and challenging in-the-wild images, showing superior generalization across diverse real-world scenes.
GaussianDreamerPro: Text to Manipulable 3D Gaussians with Highly Enhanced Quality
Jun 26, 2024Recently, 3D Gaussian splatting (3D-GS) has achieved great success in reconstructing and rendering real-world scenes. To transfer the high rendering quality to generation tasks, a series of research works attempt to generate 3D-Gaussian assets from text. However, the generated assets have not achieved the same quality as those in reconstruction tasks. We observe that Gaussians tend to grow without control as the generation process may cause indeterminacy. Aiming at highly enhancing the generation quality, we propose a novel framework named GaussianDreamerPro. The main idea is to bind Gaussians to reasonable geometry, which evolves over the whole generation process. Along different stages of our framework, both the geometry and appearance can be enriched progressively. The final output asset is constructed with 3D Gaussians bound to mesh, which shows significantly enhanced details and quality compared with previous methods. Notably, the generated asset can also be seamlessly integrated into downstream manipulation pipelines, e.g. animation, composition, and simulation etc., greatly promoting its potential in wide applications. Demos are available at https://taoranyi.com/gaussiandreamerpro/.
Segment Anything in 3D with NeRFs
Apr 26, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
NeRFVS: Neural Radiance Fields for Free View Synthesis via Geometry Scaffolds
Apr 13, 2023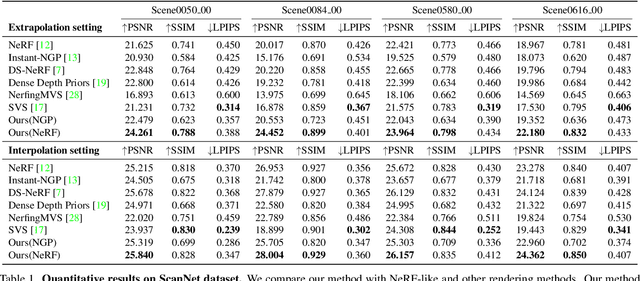
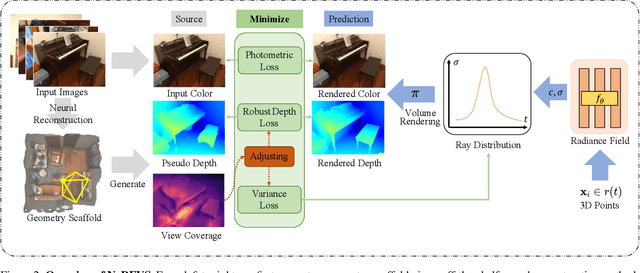
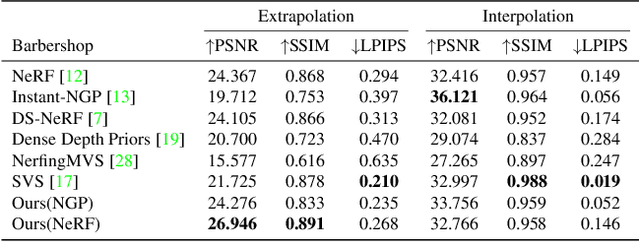

We present NeRFVS, a novel neural radiance fields (NeRF) based method to enable free navigation in a room. NeRF achieves impressive performance in rendering images for novel views similar to the input views while suffering for novel views that are significantly different from the training views. To address this issue, we utilize the holistic priors, including pseudo depth maps and view coverage information, from neural reconstruction to guide the learning of implicit neural representations of 3D indoor scenes. Concretely, an off-the-shelf neural reconstruction method is leveraged to generate a geometry scaffold. Then, two loss functions based on the holistic priors are proposed to improve the learning of NeRF: 1) A robust depth loss that can tolerate the error of the pseudo depth map to guide the geometry learning of NeRF; 2) A variance loss to regularize the variance of implicit neural representations to reduce the geometry and color ambiguity in the learning procedure. These two loss functions are modulated during NeRF optimization according to the view coverage information to reduce the negative influence brought by the view coverage imbalance. Extensive results demonstrate that our NeRFVS outperforms state-of-the-art view synthesis methods quantitatively and qualitatively on indoor scenes, achieving high-fidelity free navigation results.
A K-variate Time Series Is Worth K Words: Evolution of the Vanilla Transformer Architecture for Long-term Multivariate Time Series Forecasting
Dec 06, 2022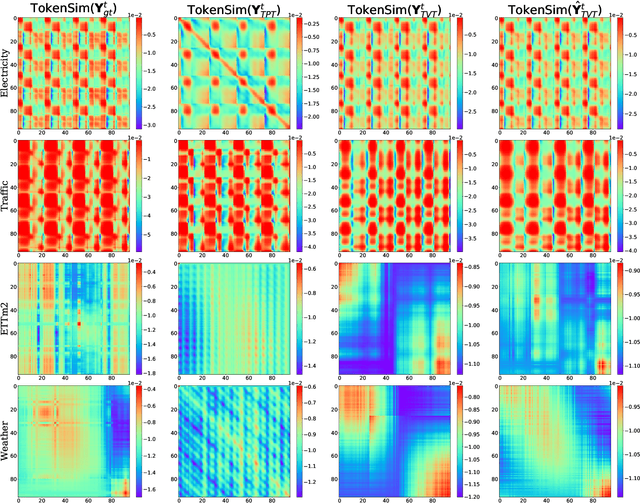
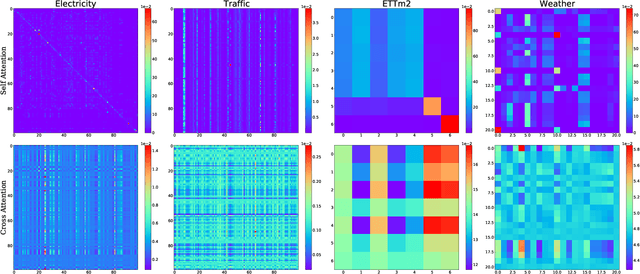
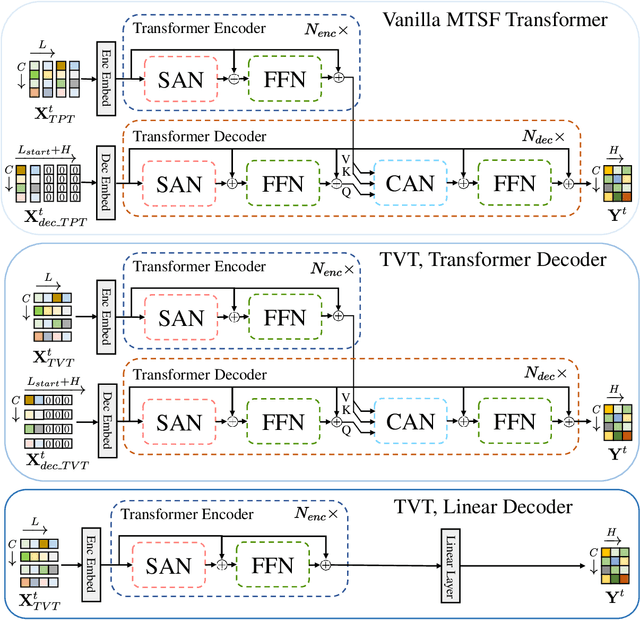
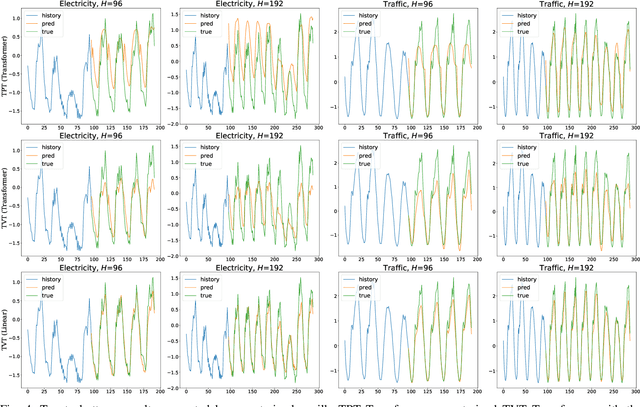
Multivariate time series forecasting (MTSF) is a fundamental problem in numerous real-world applications. Recently, Transformer has become the de facto solution for MTSF, especially for the long-term cases. However, except for the one forward operation, the basic configurations in existing MTSF Transformer architectures were barely carefully verified. In this study, we point out that the current tokenization strategy in MTSF Transformer architectures ignores the token uniformity inductive bias of Transformers. Therefore, the vanilla MTSF transformer struggles to capture details in time series and presents inferior performance. Based on this observation, we make a series of evolution on the basic architecture of the vanilla MTSF transformer. We vary the flawed tokenization strategy, along with the decoder structure and embeddings. Surprisingly, the evolved simple transformer architecture is highly effective, which successfully avoids the over-smoothing phenomena in the vanilla MTSF transformer, achieves a more detailed and accurate prediction, and even substantially outperforms the state-of-the-art Transformers that are well-designed for MTSF.
DialogueNeRF: Towards Realistic Avatar Face-to-face Conversation Video Generation
Mar 15, 2022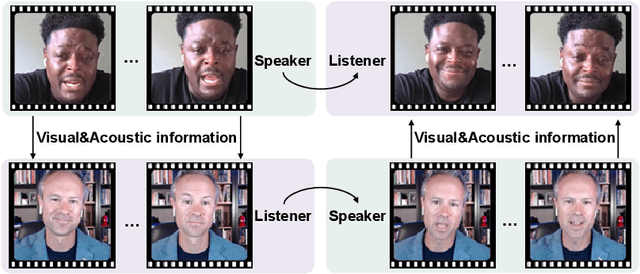
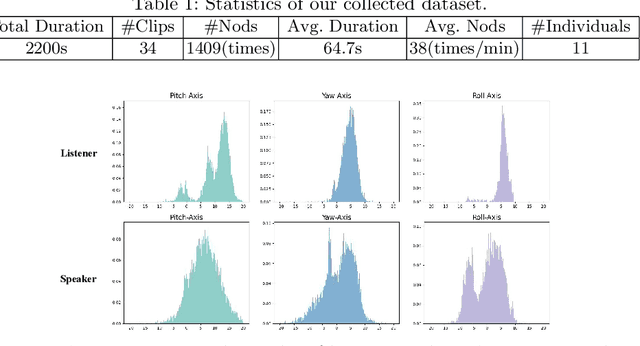

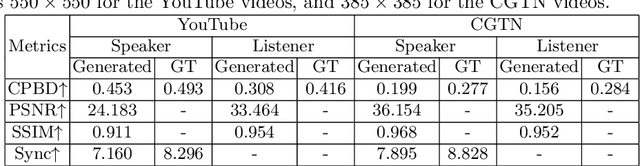
Conversation is an essential component of virtual avatar activities in the metaverse. With the development of natural language processing, textual and vocal conversation generation has achieved a significant breakthrough. Face-to-face conversations account for the vast majority of daily conversations. However, this task has not acquired enough attention. In this paper, we propose a novel task that aims to generate a realistic human avatar face-to-face conversation process and present a new dataset to explore this target. To tackle this novel task, we propose a new framework that utilizes a series of conversation signals, e.g. audio, head pose, and expression, to synthesize face-to-face conversation videos between human avatars, with all the interlocutors modeled within the same network. Our method is evaluated by quantitative and qualitative experiments in different aspects, e.g. image quality, pose sequence trend, and naturalness of the rendering videos. All the code, data, and models will be made publicly available.