 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA K-variate Time Series Is Worth K Words: Evolution of the Vanilla Transformer Architecture for Long-term Multivariate Time Series Forecasting
Paper and Code
Dec 06, 2022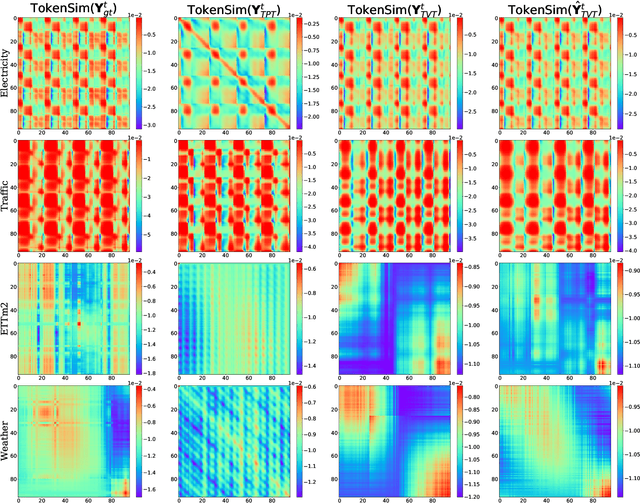
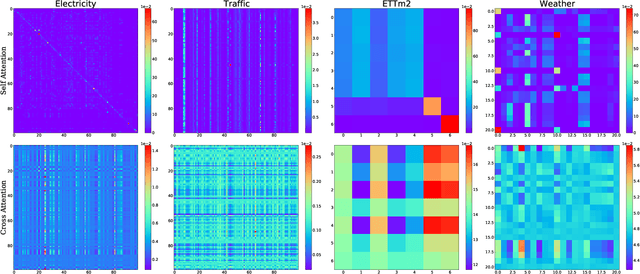
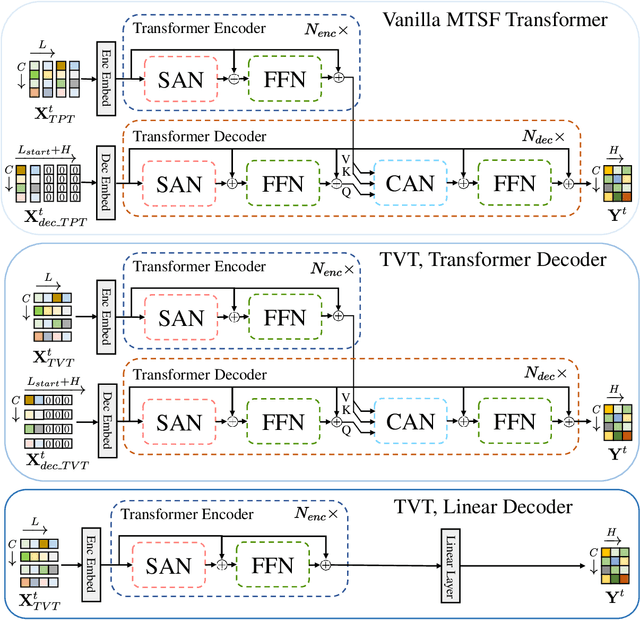
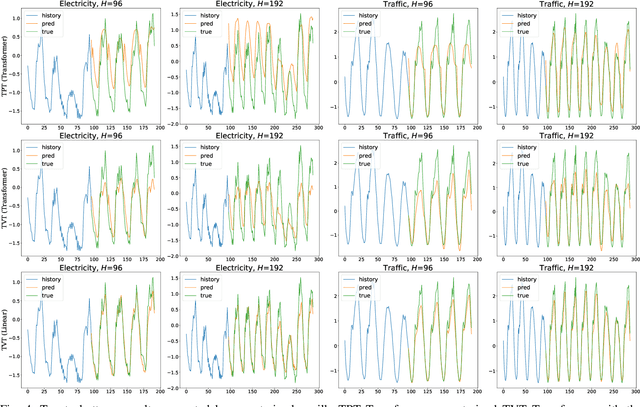
Multivariate time series forecasting (MTSF) is a fundamental problem in numerous real-world applications. Recently, Transformer has become the de facto solution for MTSF, especially for the long-term cases. However, except for the one forward operation, the basic configurations in existing MTSF Transformer architectures were barely carefully verified. In this study, we point out that the current tokenization strategy in MTSF Transformer architectures ignores the token uniformity inductive bias of Transformers. Therefore, the vanilla MTSF transformer struggles to capture details in time series and presents inferior performance. Based on this observation, we make a series of evolution on the basic architecture of the vanilla MTSF transformer. We vary the flawed tokenization strategy, along with the decoder structure and embeddings. Surprisingly, the evolved simple transformer architecture is highly effective, which successfully avoids the over-smoothing phenomena in the vanilla MTSF transformer, achieves a more detailed and accurate prediction, and even substantially outperforms the state-of-the-art Transformers that are well-designed for MTSF.