 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuphonium: Steering Video Flow Matching via Process Reward Gradient Guided Stochastic Dynamics
Feb 04, 2026While online Reinforcement Learning has emerged as a crucial technique for aligning flow matching models with human preferences, current approaches are hindered by inefficient exploration during training rollouts. Relying on undirected stochasticity and sparse outcome rewards, these methods struggle to discover high-reward samples, resulting in data-inefficient and slow optimization. To address these limitations, we propose Euphonium, a novel framework that steers generation via process reward gradient guided dynamics. Our key insight is to formulate the sampling process as a theoretically principled Stochastic Differential Equation that explicitly incorporates the gradient of a Process Reward Model into the flow drift. This design enables dense, step-by-step steering toward high-reward regions, advancing beyond the unguided exploration in prior works, and theoretically encompasses existing sampling methods (e.g., Flow-GRPO, DanceGRPO) as special cases. We further derive a distillation objective that internalizes the guidance signal into the flow network, eliminating inference-time dependency on the reward model. We instantiate this framework with a Dual-Reward Group Relative Policy Optimization algorithm, combining latent process rewards for efficient credit assignment with pixel-level outcome rewards for final visual fidelity. Experiments on text-to-video generation show that Euphonium achieves better alignment compared to existing methods while accelerating training convergence by 1.66x.
RulePlanner: All-in-One Reinforcement Learner for Unifying Design Rules in 3D Floorplanning
Jan 30, 2026Floorplanning determines the coordinate and shape of each module in Integrated Circuits. With the scaling of technology nodes, in floorplanning stage especially 3D scenarios with multiple stacked layers, it has become increasingly challenging to adhere to complex hardware design rules. Current methods are only capable of handling specific and limited design rules, while violations of other rules require manual and meticulous adjustment. This leads to labor-intensive and time-consuming post-processing for expert engineers. In this paper, we propose an all-in-one deep reinforcement learning-based approach to tackle these challenges, and design novel representations for real-world IC design rules that have not been addressed by previous approaches. Specifically, the processing of various hardware design rules is unified into a single framework with three key components: 1) novel matrix representations to model the design rules, 2) constraints on the action space to filter out invalid actions that cause rule violations, and 3) quantitative analysis of constraint satisfaction as reward signals. Experiments on public benchmarks demonstrate the effectiveness and validity of our approach. Furthermore, transferability is well demonstrated on unseen circuits. Our framework is extensible to accommodate new design rules, thus providing flexibility to address emerging challenges in future chip design. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI
SoliReward: Mitigating Susceptibility to Reward Hacking and Annotation Noise in Video Generation Reward Models
Dec 17, 2025Post-training alignment of video generation models with human preferences is a critical goal. Developing effective Reward Models (RMs) for this process faces significant methodological hurdles. Current data collection paradigms, reliant on in-prompt pairwise annotations, suffer from labeling noise. Concurrently, the architectural design of VLM-based RMs, particularly their output mechanisms, remains underexplored. Furthermore, RM is susceptible to reward hacking in post-training. To mitigate these limitations, we propose SoliReward, a systematic framework for video RM training. Our framework first sources high-quality, cost-efficient data via single-item binary annotations, then constructs preference pairs using a cross-prompt pairing strategy. Architecturally, we employ a Hierarchical Progressive Query Attention mechanism to enhance feature aggregation. Finally, we introduce a modified BT loss that explicitly accommodates win-tie scenarios. This approach regularizes the RM's score distribution for positive samples, providing more nuanced preference signals to alleviate over-focus on a small number of top-scoring samples. Our approach is validated on benchmarks evaluating physical plausibility, subject deformity, and semantic alignment, demonstrating improvements in direct RM evaluation metrics and in the efficacy of post-training on video generation models. Code and benchmark will be publicly available.
PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Feb 27, 2024



Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
A K-variate Time Series Is Worth K Words: Evolution of the Vanilla Transformer Architecture for Long-term Multivariate Time Series Forecasting
Dec 06, 2022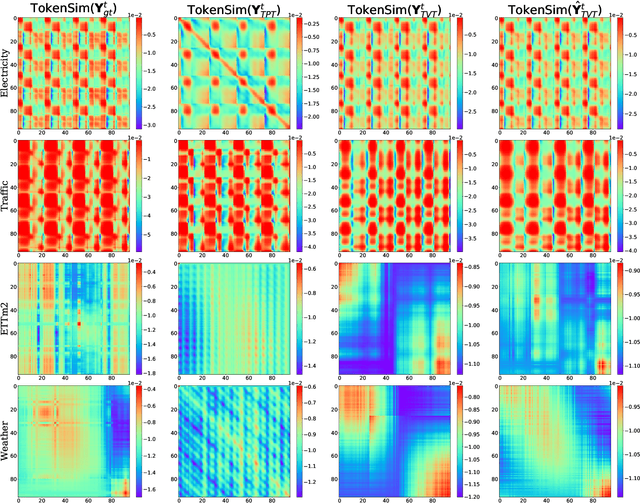
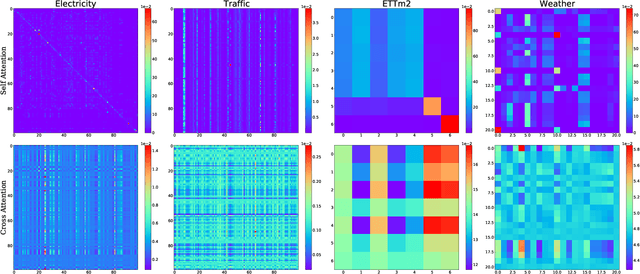
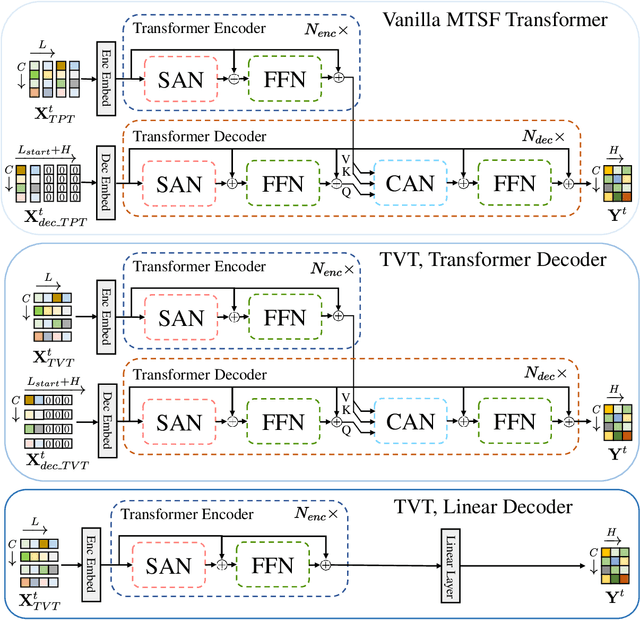
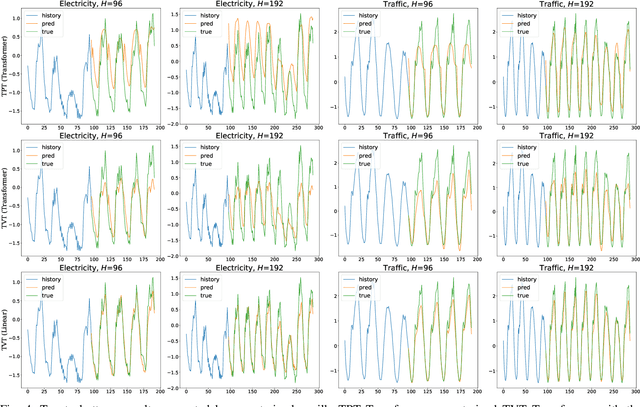
Multivariate time series forecasting (MTSF) is a fundamental problem in numerous real-world applications. Recently, Transformer has become the de facto solution for MTSF, especially for the long-term cases. However, except for the one forward operation, the basic configurations in existing MTSF Transformer architectures were barely carefully verified. In this study, we point out that the current tokenization strategy in MTSF Transformer architectures ignores the token uniformity inductive bias of Transformers. Therefore, the vanilla MTSF transformer struggles to capture details in time series and presents inferior performance. Based on this observation, we make a series of evolution on the basic architecture of the vanilla MTSF transformer. We vary the flawed tokenization strategy, along with the decoder structure and embeddings. Surprisingly, the evolved simple transformer architecture is highly effective, which successfully avoids the over-smoothing phenomena in the vanilla MTSF transformer, achieves a more detailed and accurate prediction, and even substantially outperforms the state-of-the-art Transformers that are well-designed for MTSF.