 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025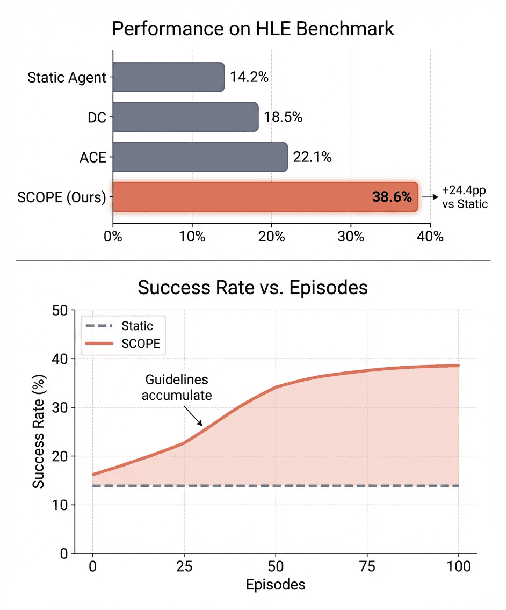
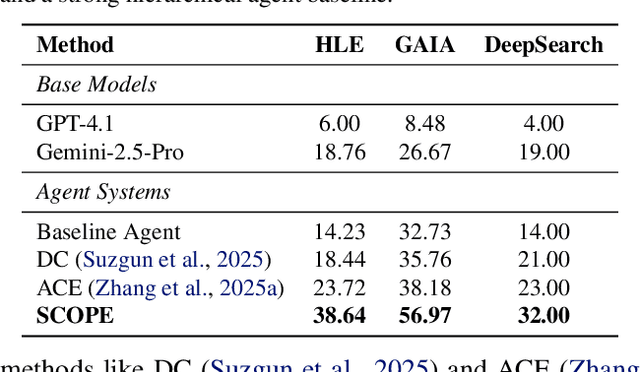
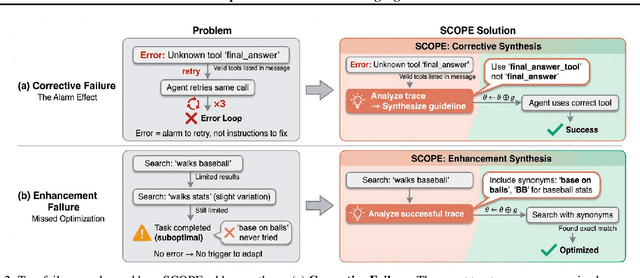
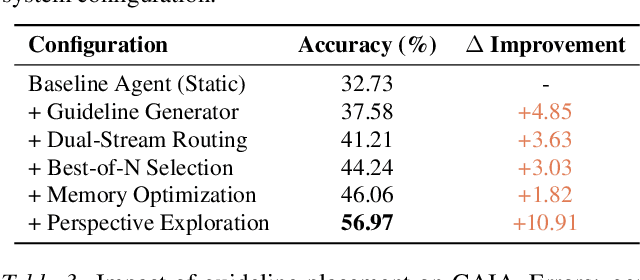
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.
E2ESlack: An End-to-End Graph-Based Framework for Pre-Routing Slack Prediction
Jan 14, 2025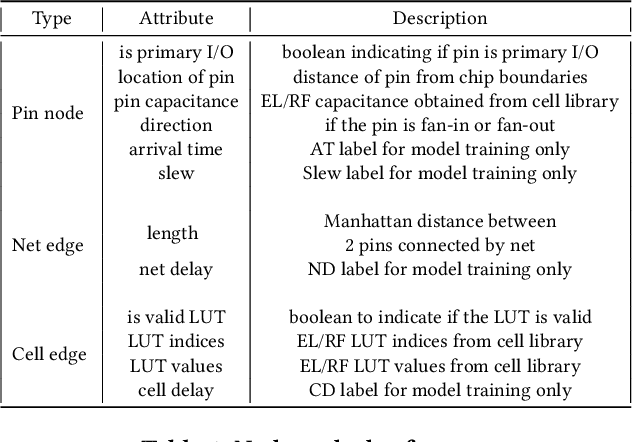
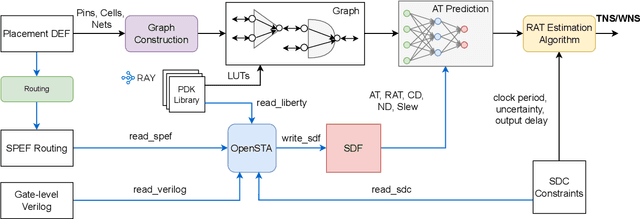
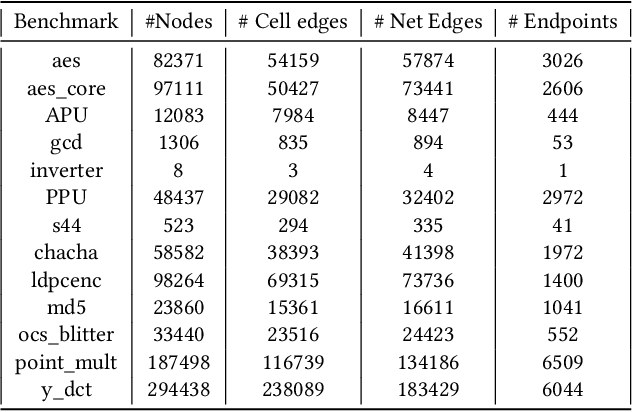
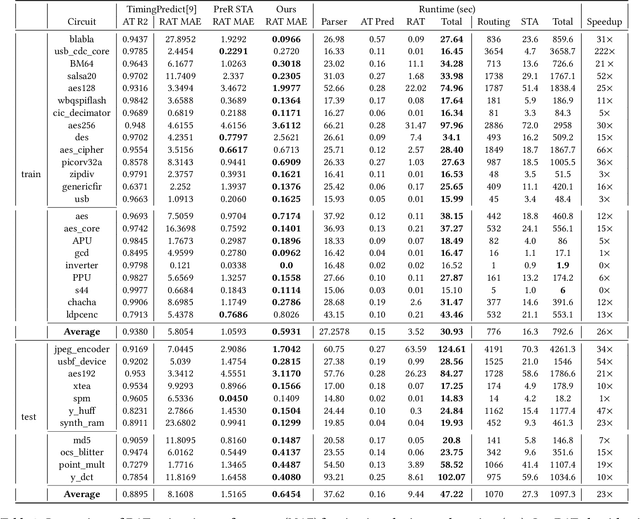
Pre-routing slack prediction remains a critical area of research in Electronic Design Automation (EDA). Despite numerous machine learning-based approaches targeting this task, there is still a lack of a truly end-to-end framework that engineers can use to obtain TNS/WNS metrics from raw circuit data at the placement stage. Existing works have demonstrated effectiveness in Arrival Time (AT) prediction but lack a mechanism for Required Arrival Time (RAT) prediction, which is essential for slack prediction and obtaining TNS/WNS metrics. In this work, we propose E2ESlack, an end-to-end graph-based framework for pre-routing slack prediction. The framework includes a TimingParser that supports DEF, SDF and LIB files for feature extraction and graph construction, an arrival time prediction model and a fast RAT estimation module. To the best of our knowledge, this is the first work capable of predicting path-level slacks at the pre-routing stage. We perform extensive experiments and demonstrate that our proposed RAT estimation method outperforms the SOTA ML-based prediction method and also pre-routing STA tool. Additionally, the proposed E2ESlack framework achieves TNS/WNS values comparable to post-routing STA results while saving up to 23x runtime.
Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer
Dec 10, 2024



In modern chip design, placement aims at placing millions of circuit modules, which is an essential step that significantly influences power, performance, and area (PPA) metrics. Recently, reinforcement learning (RL) has emerged as a promising technique for improving placement quality, especially macro placement. However, current RL-based placement methods suffer from long training times, low generalization ability, and inability to guarantee PPA results. A key issue lies in the problem formulation, i.e., using RL to place from scratch, which results in limits useful information and inaccurate rewards during the training process. In this work, we propose an approach that utilizes RL for the refinement stage, which allows the RL policy to learn how to adjust existing placement layouts, thereby receiving sufficient information for the policy to act and obtain relatively dense and precise rewards. Additionally, we introduce the concept of regularity during training, which is considered an important metric in the chip design industry but is often overlooked in current RL placement methods. We evaluate our approach on the ISPD 2005 and ICCAD 2015 benchmark, comparing the global half-perimeter wirelength and regularity of our proposed method against several competitive approaches. Besides, we test the PPA performance using commercial software, showing that RL as a regulator can achieve significant PPA improvements. Our RL regulator can fine-tune placements from any method and enhance their quality. Our work opens up new possibilities for the application of RL in placement, providing a more effective and efficient approach to optimizing chip design. Our code is available at \url{https://github.com/lamda-bbo/macro-regulator}.
Escaping Local Optima in Global Placement
Feb 28, 2024Placement is crucial in the physical design, as it greatly affects power, performance, and area metrics. Recent advancements in analytical methods, such as DREAMPlace, have demonstrated impressive performance in global placement. However, DREAMPlace has some limitations, e.g., may not guarantee legalizable placements under the same settings, leading to fragile and unpredictable results. This paper highlights the main issue as being stuck in local optima, and proposes a hybrid optimization framework to efficiently escape the local optima, by perturbing the placement result iteratively. The proposed framework achieves significant improvements compared to state-of-the-art methods on two popular benchmarks.
PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Feb 27, 2024



Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
RITA: Boost Autonomous Driving Simulators with Realistic Interactive Traffic Flow
Nov 11, 2022



High-quality traffic flow generation is the core module in building simulators for autonomous driving. However, the majority of available simulators are incapable of replicating traffic patterns that accurately reflect the various features of real-world data while also simulating human-like reactive responses to the tested autopilot driving strategies. Taking one step forward to addressing such a problem, we propose Realistic Interactive TrAffic flow (RITA) as an integrated component of existing driving simulators to provide high-quality traffic flow for the evaluation and optimization of the tested driving strategies. RITA is developed with fidelity, diversity, and controllability in consideration, and consists of two core modules called RITABackend and RITAKit. RITABackend is built to support vehicle-wise control and provide traffic generation models from real-world datasets, while RITAKit is developed with easy-to-use interfaces for controllable traffic generation via RITABackend. We demonstrate RITA's capacity to create diversified and high-fidelity traffic simulations in several highly interactive highway scenarios. The experimental findings demonstrate that our produced RITA traffic flows meet all three design goals, hence enhancing the completeness of driving strategy evaluation. Moreover, we showcase the possibility for further improvement of baseline strategies through online fine-tuning with RITA traffic flows.