 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Feb 27, 2024



Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
ChiPFormer: Transferable Chip Placement via Offline Decision Transformer
Jun 26, 2023Placement is a critical step in modern chip design, aiming to determine the positions of circuit modules on the chip canvas. Recent works have shown that reinforcement learning (RL) can improve human performance in chip placement. However, such an RL-based approach suffers from long training time and low transfer ability in unseen chip circuits. To resolve these challenges, we cast the chip placement as an offline RL formulation and present ChiPFormer that enables learning a transferable placement policy from fixed offline data. ChiPFormer has several advantages that prior arts do not have. First, ChiPFormer can exploit offline placement designs to learn transferable policies more efficiently in a multi-task setting. Second, ChiPFormer can promote effective finetuning for unseen chip circuits, reducing the placement runtime from hours to minutes. Third, extensive experiments on 32 chip circuits demonstrate that ChiPFormer achieves significantly better placement quality while reducing the runtime by 10x compared to recent state-of-the-art approaches in both public benchmarks and realistic industrial tasks. The deliverables are released at https://sites.google.com/view/chipformer/home.
Enhanced Rolling Horizon Evolution Algorithm with Opponent Model Learning: Results for the Fighting Game AI Competition
Mar 31, 2020
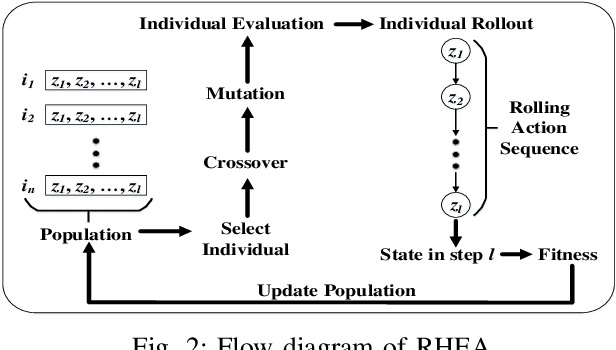
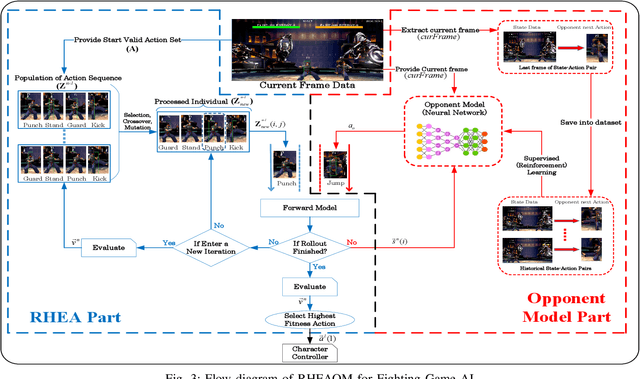
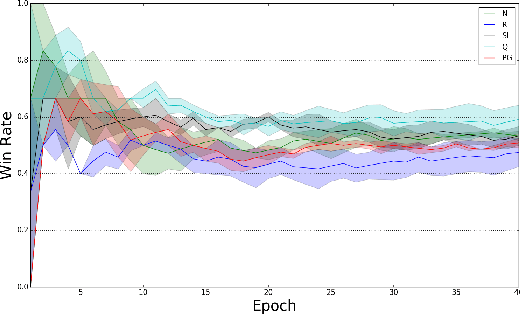
The Fighting Game AI Competition (FTGAIC) provides a challenging benchmark for 2-player video game AI. The challenge arises from the large action space, diverse styles of characters and abilities, and the real-time nature of the game. In this paper, we propose a novel algorithm that combines Rolling Horizon Evolution Algorithm (RHEA) with opponent model learning. The approach is readily applicable to any 2-player video game. In contrast to conventional RHEA, an opponent model is proposed and is optimized by supervised learning with cross-entropy and reinforcement learning with policy gradient and Q-learning respectively, based on history observations from opponent. The model is learned during the live gameplay. With the learned opponent model, the extended RHEA is able to make more realistic plans based on what the opponent is likely to do. This tends to lead to better results. We compared our approach directly with the bots from the FTGAIC 2018 competition, and found our method to significantly outperform all of them, for all three character. Furthermore, our proposed bot with the policy-gradient-based opponent model is the only one without using Monte-Carlo Tree Search (MCTS) among top five bots in the 2019 competition in which it achieved second place, while using much less domain knowledge than the winner.
A Survey of Deep Reinforcement Learning in Video Games
Dec 26, 2019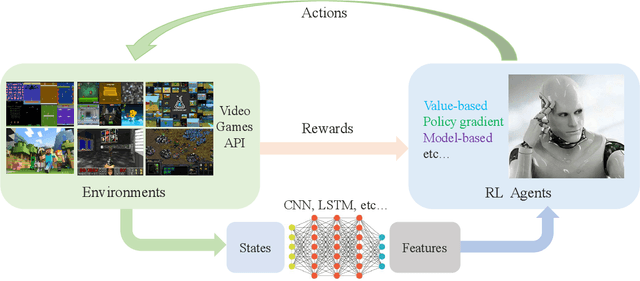
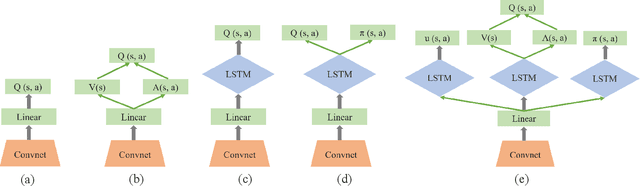
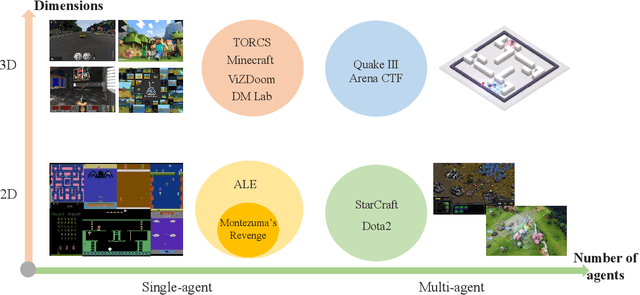
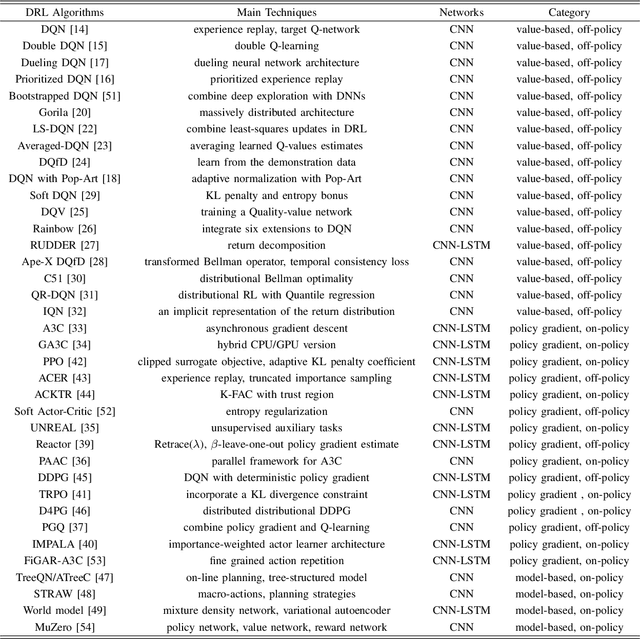
Deep reinforcement learning (DRL) has made great achievements since proposed. Generally, DRL agents receive high-dimensional inputs at each step, and make actions according to deep-neural-network-based policies. This learning mechanism updates the policy to maximize the return with an end-to-end method. In this paper, we survey the progress of DRL methods, including value-based, policy gradient, and model-based algorithms, and compare their main techniques and properties. Besides, DRL plays an important role in game artificial intelligence (AI). We also take a review of the achievements of DRL in various video games, including classical Arcade games, first-person perspective games and multi-agent real-time strategy games, from 2D to 3D, and from single-agent to multi-agent. A large number of video game AIs with DRL have achieved super-human performance, while there are still some challenges in this domain. Therefore, we also discuss some key points when applying DRL methods to this field, including exploration-exploitation, sample efficiency, generalization and transfer, multi-agent learning, imperfect information, and delayed spare rewards, as well as some research directions.