 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogueNeRF: Towards Realistic Avatar Face-to-face Conversation Video Generation
Paper and Code
Mar 15, 2022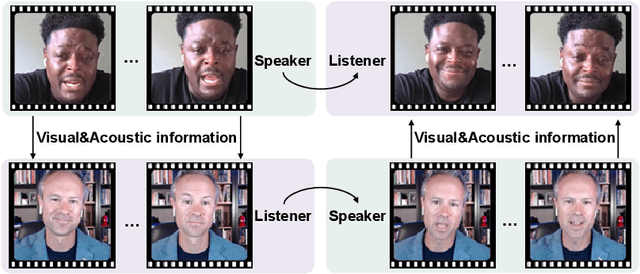
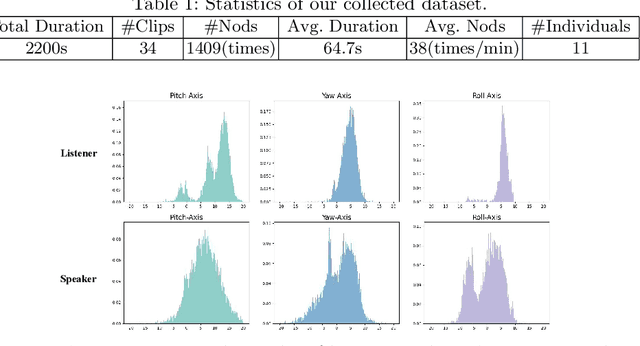

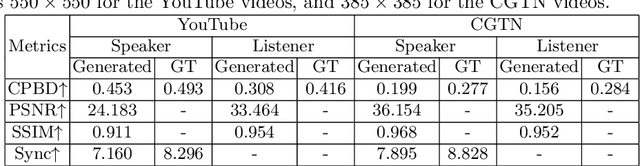
Conversation is an essential component of virtual avatar activities in the metaverse. With the development of natural language processing, textual and vocal conversation generation has achieved a significant breakthrough. Face-to-face conversations account for the vast majority of daily conversations. However, this task has not acquired enough attention. In this paper, we propose a novel task that aims to generate a realistic human avatar face-to-face conversation process and present a new dataset to explore this target. To tackle this novel task, we propose a new framework that utilizes a series of conversation signals, e.g. audio, head pose, and expression, to synthesize face-to-face conversation videos between human avatars, with all the interlocutors modeled within the same network. Our method is evaluated by quantitative and qualitative experiments in different aspects, e.g. image quality, pose sequence trend, and naturalness of the rendering videos. All the code, data, and models will be made publicly available.