 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
Paper and Code

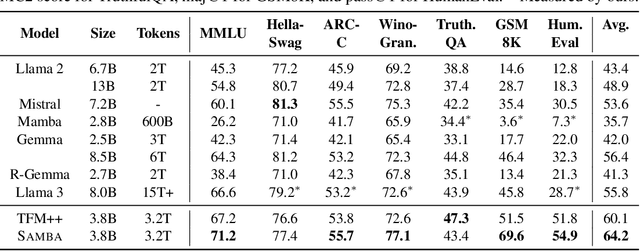

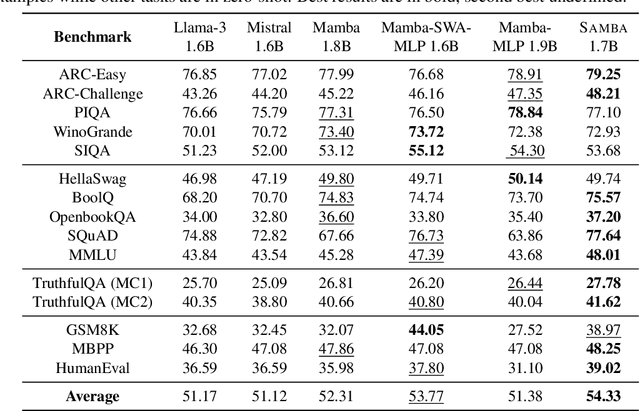
Efficiently modeling sequences with infinite context length has been a long-standing problem. Past works suffer from either the quadratic computation complexity or the limited extrapolation ability on length generalization. In this work, we present Samba, a simple hybrid architecture that layer-wise combines Mamba, a selective State Space Model (SSM), with Sliding Window Attention (SWA). Samba selectively compresses a given sequence into recurrent hidden states while still maintaining the ability to precisely recall memories with the attention mechanism. We scale Samba up to 3.8B parameters with 3.2T training tokens and show that Samba substantially outperforms the state-of-the-art models based on pure attention or SSMs on a wide range of benchmarks. When trained on 4K length sequences, Samba can be efficiently extrapolated to 256K context length with perfect memory recall and show improved token predictions up to 1M context length. As a linear-time sequence model, Samba enjoys a 3.73x higher throughput compared to Transformers with grouped-query attention when processing user prompts of 128K length, and 3.64x speedup when generating 64K tokens with unlimited streaming. A sample implementation of Samba is publicly available in https://github.com/microsoft/Samba.