 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentInstruct: Toward Generative Teaching with Agentic Flows
Jul 03, 2024



Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns around model collapse and drawbacks of imitating other models. This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data. We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching. We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds. We demonstrate the utility of AgentInstruct by creating a post training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc. The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks. For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.
Orca 2: Teaching Small Language Models How to Reason
Nov 21, 2023



Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
Contrastive Post-training Large Language Models on Data Curriculum
Oct 03, 2023



Alignment serves as an important step to steer large language models (LLMs) towards human preferences. In this paper, we explore contrastive post-training techniques for alignment by automatically constructing preference pairs from multiple models of varying strengths (e.g., InstructGPT, ChatGPT and GPT-4). We carefully compare the contrastive techniques of SLiC and DPO to SFT baselines and find that DPO provides a step-function improvement even after continueing SFT saturates. We also explore a data curriculum learning scheme for contrastive post-training, which starts by learning from "easier" pairs and transitioning to "harder" ones, which further improves alignment. Finally, we scale up our experiments to train with more data and larger models like Orca. Remarkably, contrastive post-training further improves the performance of Orca, already a state-of-the-art instruction learning model tuned with GPT-4 outputs, to exceed that of ChatGPT.
Lexi: Self-Supervised Learning of the UI Language
Jan 23, 2023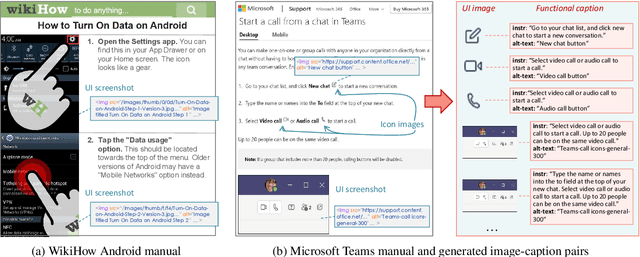

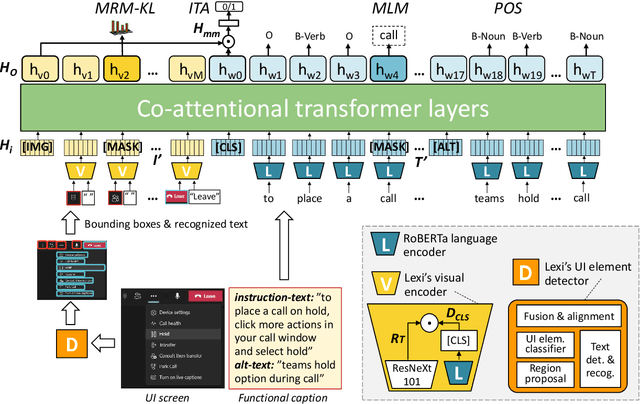

Humans can learn to operate the user interface (UI) of an application by reading an instruction manual or how-to guide. Along with text, these resources include visual content such as UI screenshots and images of application icons referenced in the text. We explore how to leverage this data to learn generic visio-linguistic representations of UI screens and their components. These representations are useful in many real applications, such as accessibility, voice navigation, and task automation. Prior UI representation models rely on UI metadata (UI trees and accessibility labels), which is often missing, incompletely defined, or not accessible. We avoid such a dependency, and propose Lexi, a pre-trained vision and language model designed to handle the unique features of UI screens, including their text richness and context sensitivity. To train Lexi we curate the UICaption dataset consisting of 114k UI images paired with descriptions of their functionality. We evaluate Lexi on four tasks: UI action entailment, instruction-based UI image retrieval, grounding referring expressions, and UI entity recognition.
Leveraging semantically similar queries for ranking via combining representations
Jun 23, 2021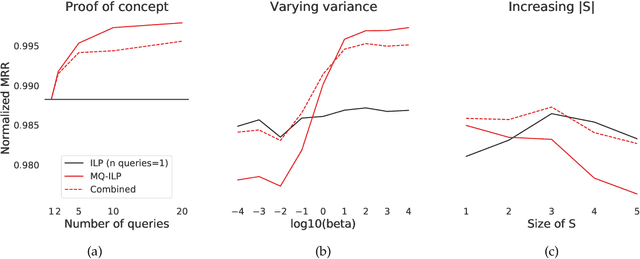
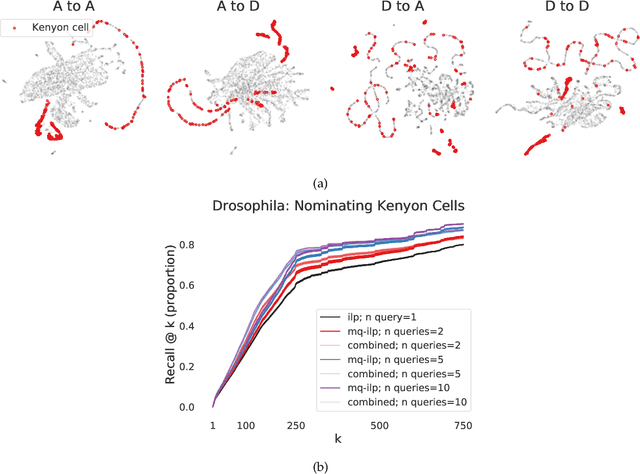
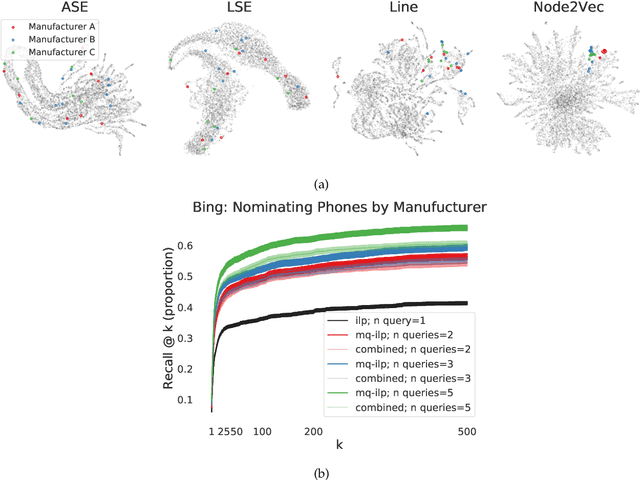
In modern ranking problems, different and disparate representations of the items to be ranked are often available. It is sensible, then, to try to combine these representations to improve ranking. Indeed, learning to rank via combining representations is both principled and practical for learning a ranking function for a particular query. In extremely data-scarce settings, however, the amount of labeled data available for a particular query can lead to a highly variable and ineffective ranking function. One way to mitigate the effect of the small amount of data is to leverage information from semantically similar queries. Indeed, as we demonstrate in simulation settings and real data examples, when semantically similar queries are available it is possible to gainfully use them when ranking with respect to a particular query. We describe and explore this phenomenon in the context of the bias-variance trade off and apply it to the data-scarce settings of a Bing navigational graph and the Drosophila larva connectome.
Learning without gradient descent encoded by the dynamics of a neurobiological model
Mar 23, 2021
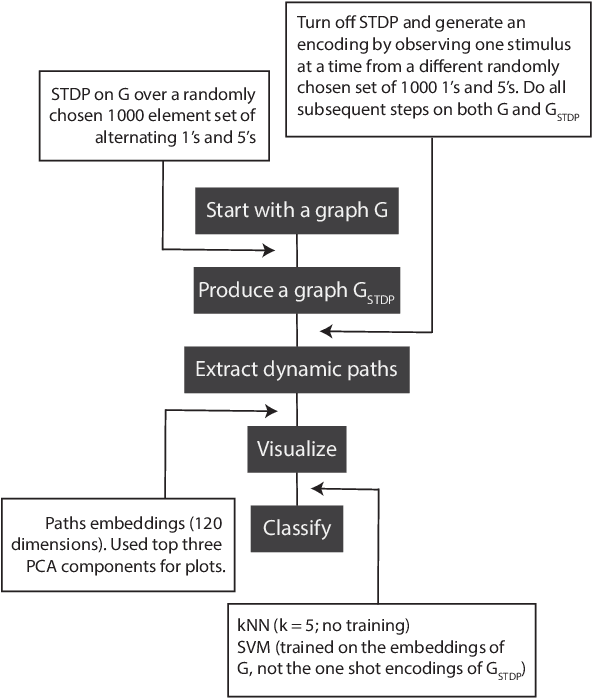
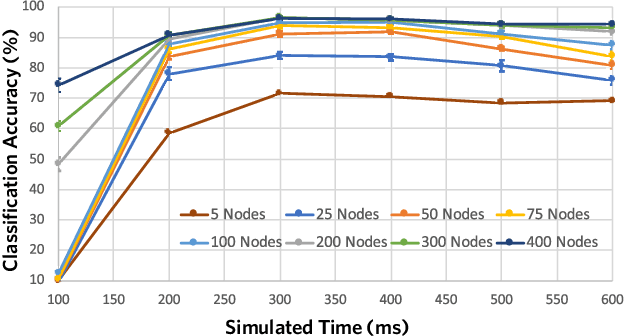
The success of state-of-the-art machine learning is essentially all based on different variations of gradient descent algorithms that minimize some version of a cost or loss function. A fundamental limitation, however, is the need to train these systems in either supervised or unsupervised ways by exposing them to typically large numbers of training examples. Here, we introduce a fundamentally novel conceptual approach to machine learning that takes advantage of a neurobiologically derived model of dynamic signaling, constrained by the geometric structure of a network. We show that MNIST images can be uniquely encoded and classified by the dynamics of geometric networks with nearly state-of-the-art accuracy in an unsupervised way, and without the need for any training.