 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Matching via Optimal Transport
Nov 09, 2021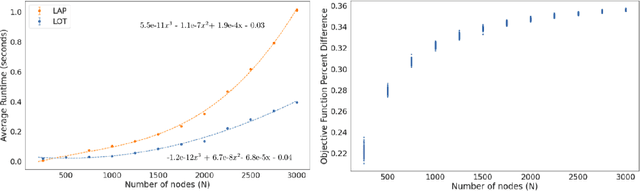
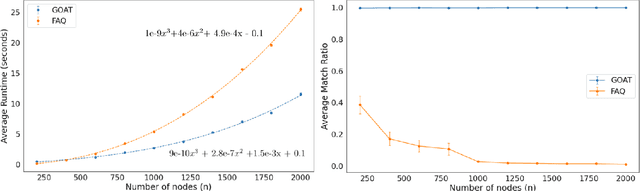
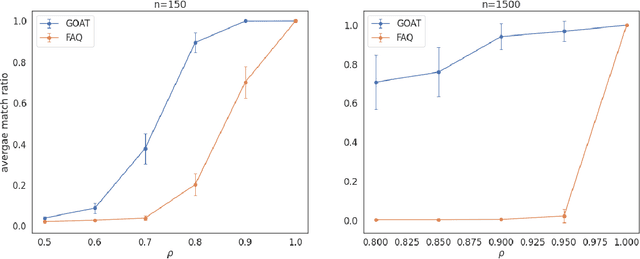
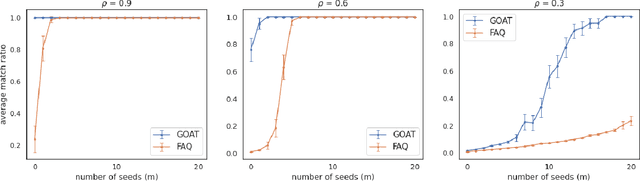
The graph matching problem seeks to find an alignment between the nodes of two graphs that minimizes the number of adjacency disagreements. Solving the graph matching is increasingly important due to it's applications in operations research, computer vision, neuroscience, and more. However, current state-of-the-art algorithms are inefficient in matching very large graphs, though they produce good accuracy. The main computational bottleneck of these algorithms is the linear assignment problem, which must be solved at each iteration. In this paper, we leverage the recent advances in the field of optimal transport to replace the accepted use of linear assignment algorithms. We present GOAT, a modification to the state-of-the-art graph matching approximation algorithm "FAQ" (Vogelstein, 2015), replacing its linear sum assignment step with the "Lightspeed Optimal Transport" method of Cuturi (2013). The modification provides improvements to both speed and empirical matching accuracy. The effectiveness of the approach is demonstrated in matching graphs in simulated and real data examples.
Leveraging semantically similar queries for ranking via combining representations
Jun 23, 2021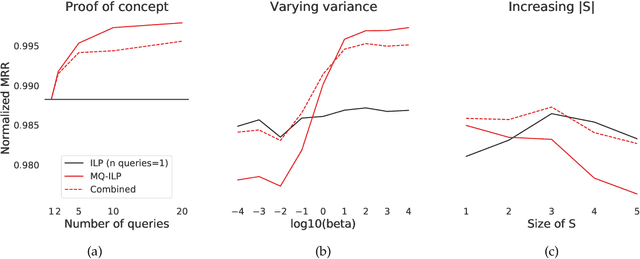
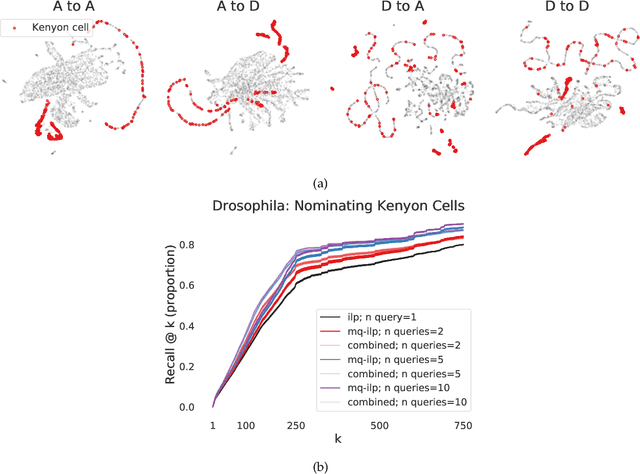
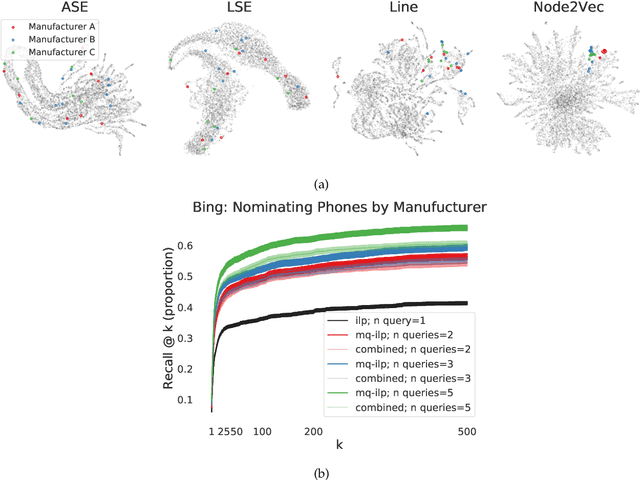
In modern ranking problems, different and disparate representations of the items to be ranked are often available. It is sensible, then, to try to combine these representations to improve ranking. Indeed, learning to rank via combining representations is both principled and practical for learning a ranking function for a particular query. In extremely data-scarce settings, however, the amount of labeled data available for a particular query can lead to a highly variable and ineffective ranking function. One way to mitigate the effect of the small amount of data is to leverage information from semantically similar queries. Indeed, as we demonstrate in simulation settings and real data examples, when semantically similar queries are available it is possible to gainfully use them when ranking with respect to a particular query. We describe and explore this phenomenon in the context of the bias-variance trade off and apply it to the data-scarce settings of a Bing navigational graph and the Drosophila larva connectome.
GraSPy: Graph Statistics in Python
Mar 29, 2019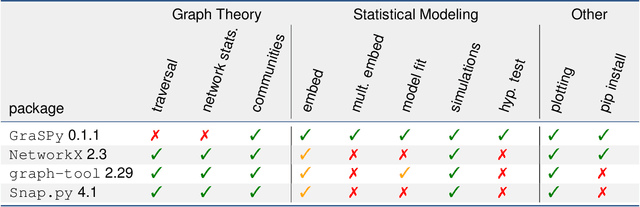
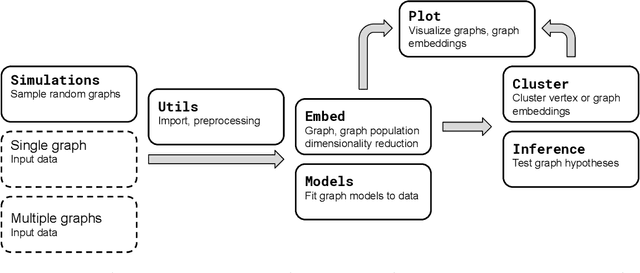
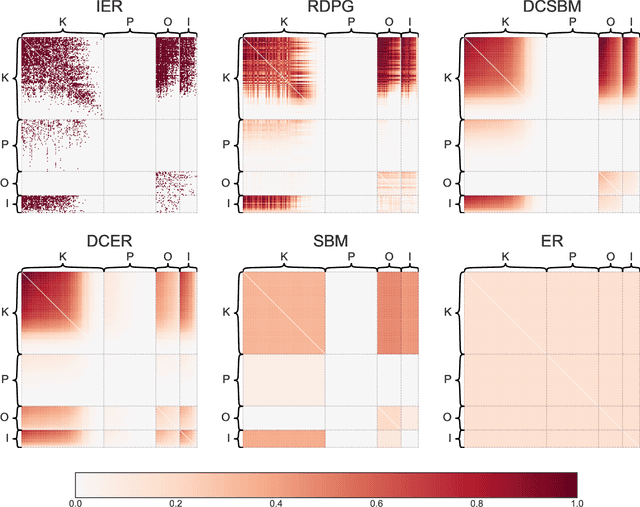
We introduce GraSPy, a Python library devoted to statistical inference, machine learning, and visualization of random graphs and graph populations. This package provides flexible and easy-to-use algorithms for analyzing and understanding graphs with a scikit-learn compliant API. GraSPy can be downloaded from Python Package Index (PyPi), and is released under the Apache 2.0 open-source license. The documentation and all releases are available at https://neurodata.io/graspy.