 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
Apr 04, 2024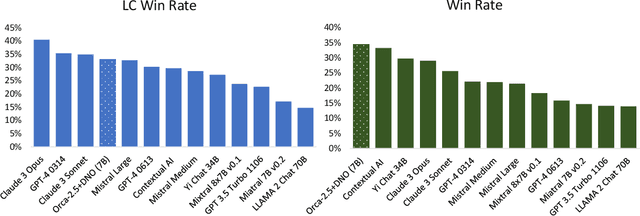
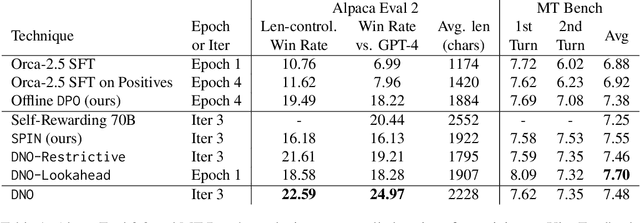
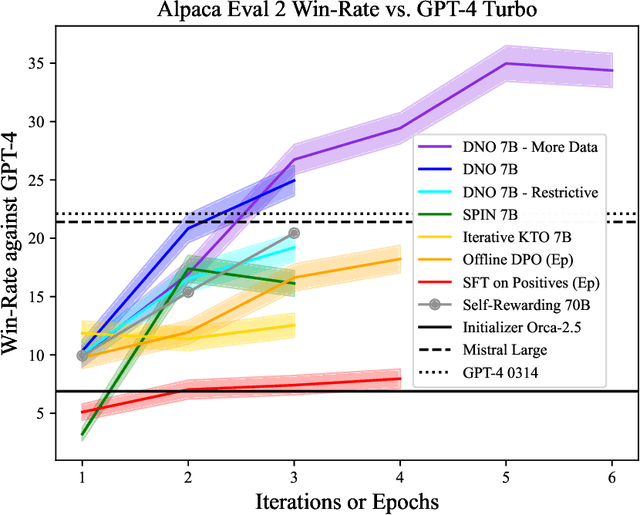
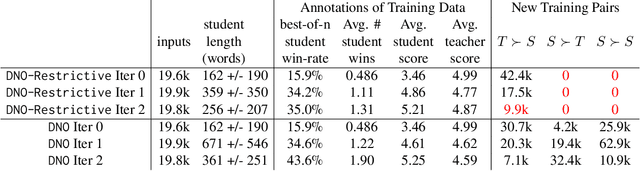
This paper studies post-training large language models (LLMs) using preference feedback from a powerful oracle to help a model iteratively improve over itself. The typical approach for post-training LLMs involves Reinforcement Learning from Human Feedback (RLHF), which traditionally separates reward learning and subsequent policy optimization. However, such a reward maximization approach is limited by the nature of "point-wise" rewards (such as Bradley-Terry model), which fails to express complex intransitive or cyclic preference relations. While advances on RLHF show reward learning and policy optimization can be merged into a single contrastive objective for stability, they yet still remain tethered to the reward maximization framework. Recently, a new wave of research sidesteps the reward maximization presumptions in favor of directly optimizing over "pair-wise" or general preferences. In this paper, we introduce Direct Nash Optimization (DNO), a provable and scalable algorithm that marries the simplicity and stability of contrastive learning with theoretical generality from optimizing general preferences. Because DNO is a batched on-policy algorithm using a regression-based objective, its implementation is straightforward and efficient. Moreover, DNO enjoys monotonic improvement across iterations that help it improve even over a strong teacher (such as GPT-4). In our experiments, a resulting 7B parameter Orca-2.5 model aligned by DNO achieves the state-of-the-art win-rate against GPT-4-Turbo of 33% on AlpacaEval 2.0 (even after controlling for response length), an absolute gain of 26% (7% to 33%) over the initializing model. It outperforms models with far more parameters, including Mistral Large, Self-Rewarding LM (70B parameters), and older versions of GPT-4.
Adapting LLM Agents Through Communication
Oct 10, 2023



Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Through iterative exploration and PPO training, LTC empowers the agent to assimilate short-term experiences into long-term memory. To optimize agent interactions for task-specific learning, we introduce three structured communication patterns: Monologue, Dialogue, and Analogue-tailored for common tasks such as decision-making, knowledge-intensive reasoning, and numerical reasoning. We evaluated LTC on three datasets: ALFWorld (decision-making), HotpotQA (knowledge-intensive reasoning), and GSM8k (numerical reasoning). On ALFWorld, it exceeds the instruction tuning baseline by 12% in success rate. On HotpotQA, LTC surpasses the instruction-tuned LLaMA-7B agent by 5.1% in EM score, and it outperforms the instruction-tuned 9x larger PaLM-62B agent by 0.6%. On GSM8k, LTC outperforms the CoT-Tuning baseline by 3.6% in accuracy. The results showcase the versatility and efficiency of the LTC approach across diverse domains. We will open-source our code to promote further development of the community.
Efficient RLHF: Reducing the Memory Usage of PPO
Sep 01, 2023Reinforcement Learning with Human Feedback (RLHF) has revolutionized language modeling by aligning models with human preferences. However, the RL stage, Proximal Policy Optimization (PPO), requires over 3x the memory of Supervised Fine-Tuning (SFT), making it infeasible to use for most practitioners. To address this issue, we present a comprehensive analysis the memory usage, performance, and training time of memory-savings techniques for PPO. We introduce Hydra-RLHF by first integrating the SFT and Reward models and then dynamically turning LoRA "off" during training. Our experiments show: 1. Using LoRA during PPO reduces its memory usage to be smaller than SFT while improving alignment across four public benchmarks, and 2. Hydra-PPO reduces the latency per sample of LoRA-PPO by up to 65% while maintaining its performance. Our results demonstrate that Hydra-PPO is a simple and promising solution for enabling more widespread usage of RLHF.
What Matters In The Structured Pruning of Generative Language Models?
Feb 07, 2023
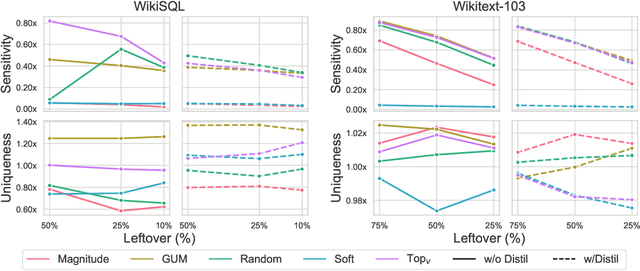

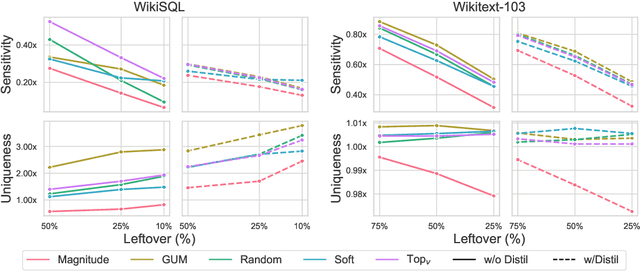
Auto-regressive large language models such as GPT-3 require enormous computational resources to use. Traditionally, structured pruning methods are employed to reduce resource usage. However, their application to and efficacy for generative language models is heavily under-explored. In this paper we conduct an comprehensive evaluation of common structured pruning methods, including magnitude, random, and movement pruning on the feed-forward layers in GPT-type models. Unexpectedly, random pruning results in performance that is comparable to the best established methods, across multiple natural language generation tasks. To understand these results, we provide a framework for measuring neuron-level redundancy of models pruned by different methods, and discover that established structured pruning methods do not take into account the distinctiveness of neurons, leaving behind excess redundancies. In view of this, we introduce Globally Unique Movement (GUM) to improve the uniqueness of neurons in pruned models. We then discuss the effects of our techniques on different redundancy metrics to explain the improved performance.