 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters In The Structured Pruning of Generative Language Models?
Paper and Code

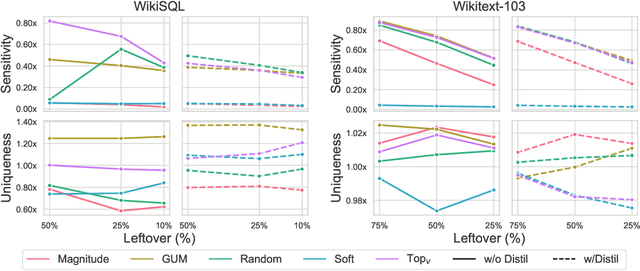

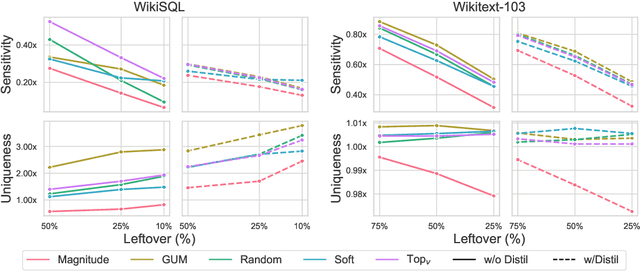
Auto-regressive large language models such as GPT-3 require enormous computational resources to use. Traditionally, structured pruning methods are employed to reduce resource usage. However, their application to and efficacy for generative language models is heavily under-explored. In this paper we conduct an comprehensive evaluation of common structured pruning methods, including magnitude, random, and movement pruning on the feed-forward layers in GPT-type models. Unexpectedly, random pruning results in performance that is comparable to the best established methods, across multiple natural language generation tasks. To understand these results, we provide a framework for measuring neuron-level redundancy of models pruned by different methods, and discover that established structured pruning methods do not take into account the distinctiveness of neurons, leaving behind excess redundancies. In view of this, we introduce Globally Unique Movement (GUM) to improve the uniqueness of neurons in pruned models. We then discuss the effects of our techniques on different redundancy metrics to explain the improved performance.