 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation
Paper and Code

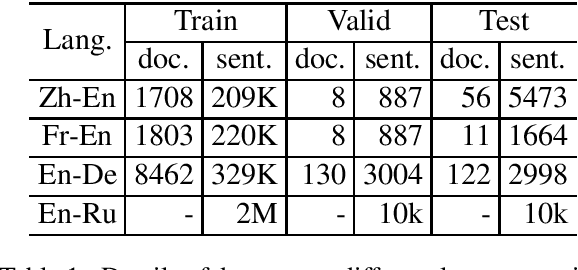

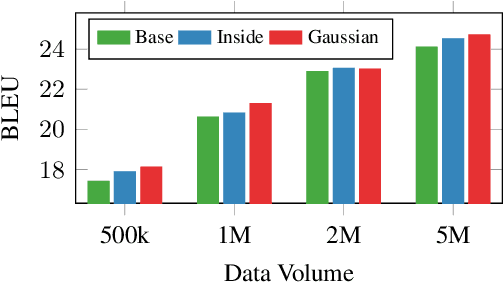
In encoder-decoder neural models, multiple encoders are in general used to represent the contextual information in addition to the individual sentence. In this paper, we investigate multi-encoder approaches in documentlevel neural machine translation (NMT). Surprisingly, we find that the context encoder does not only encode the surrounding sentences but also behaves as a noise generator. This makes us rethink the real benefits of multi-encoder in context-aware translation - some of the improvements come from robust training. We compare several methods that introduce noise and/or well-tuned dropout setup into the training of these encoders. Experimental results show that noisy training plays an important role in multi-encoder-based NMT, especially when the training data is small. Also, we establish a new state-of-the-art on IWSLT Fr-En task by careful use of noise generation and dropout methods.