 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Wise Multi-View Learning for Neural Machine Translation
Paper and Code
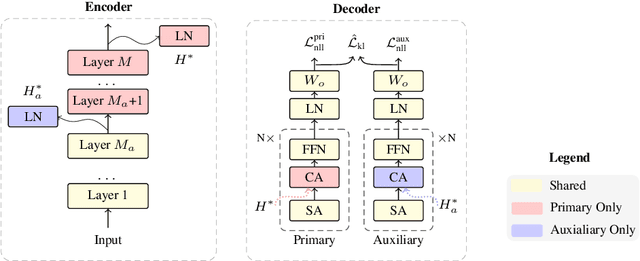
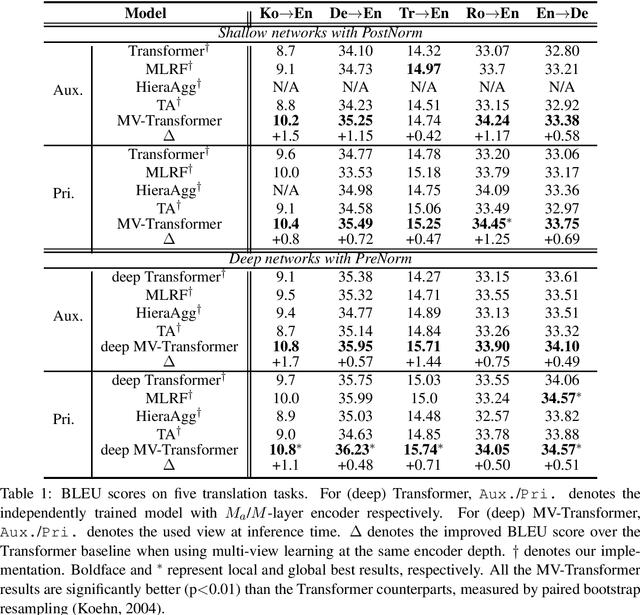
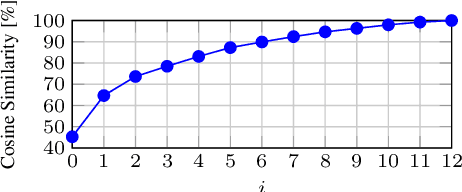

Traditional neural machine translation is limited to the topmost encoder layer's context representation and cannot directly perceive the lower encoder layers. Existing solutions usually rely on the adjustment of network architecture, making the calculation more complicated or introducing additional structural restrictions. In this work, we propose layer-wise multi-view learning to solve this problem, circumventing the necessity to change the model structure. We regard each encoder layer's off-the-shelf output, a by-product in layer-by-layer encoding, as the redundant view for the input sentence. In this way, in addition to the topmost encoder layer (referred to as the primary view), we also incorporate an intermediate encoder layer as the auxiliary view. We feed the two views to a partially shared decoder to maintain independent prediction. Consistency regularization based on KL divergence is used to encourage the two views to learn from each other. Extensive experimental results on five translation tasks show that our approach yields stable improvements over multiple strong baselines. As another bonus, our method is agnostic to network architectures and can maintain the same inference speed as the original model.