 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF5R-TTS: Improving Flow Matching based Text-to-Speech with Group Relative Policy Optimization
Apr 03, 2025We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (relatively 29.5\% WER reduction) and speaker similarity (relatively 4.6\% SIM score increase) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
DGC-vector: A new speaker embedding for zero-shot voice conversion
Mar 18, 2022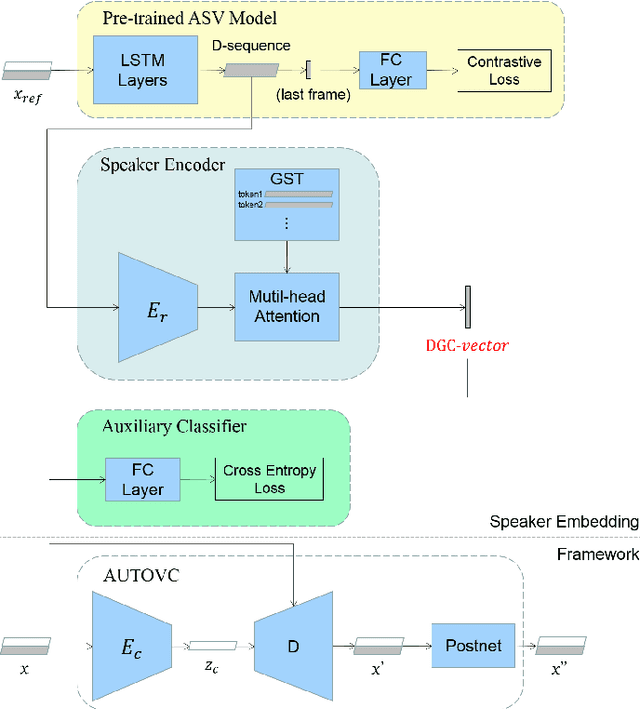
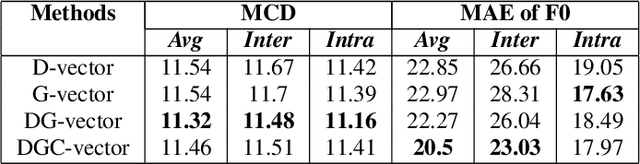
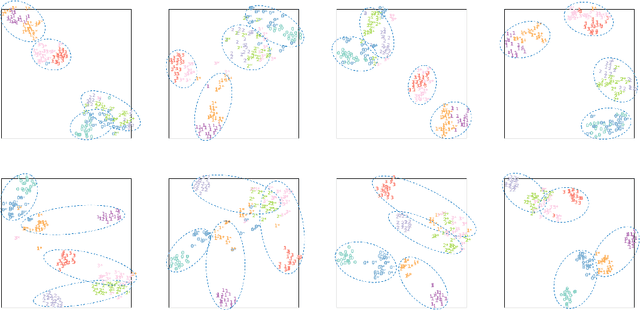
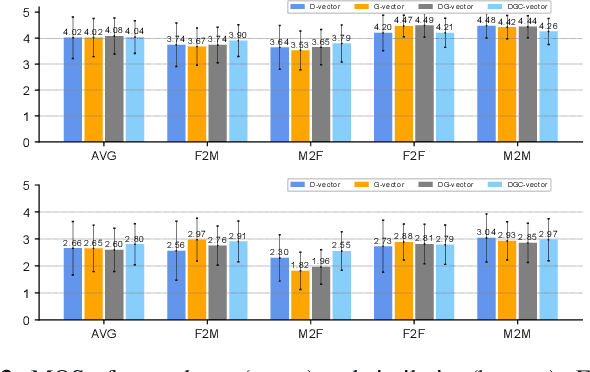
Recently, more and more zero-shot voice conversion algorithms have been proposed. As a fundamental part of zero-shot voice conversion, speaker embeddings are the key to improving the converted speech's speaker similarity. In this paper, we study the impact of speaker embeddings on zero-shot voice conversion performance. To better represent the characteristics of the target speaker and improve the speaker similarity in zero-shot voice conversion, we propose a novel speaker representation method in this paper. Our method combines the advantages of D-vector, global style token (GST) based speaker representation and auxiliary supervision. Objective and subjective evaluations show that the proposed method achieves a decent performance on zero-shot voice conversion and significantly improves speaker similarity over D-vector and GST-based speaker embedding.