 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Consistency from Only Two Samples: CoT-PoT Ensembling for Efficient LLM Reasoning
Apr 19, 2026Self-consistency (SC) is a popular technique for improving the reasoning accuracy of large language models by aggregating multiple sampled outputs, but it comes at a high computational cost due to extensive sampling. We introduce a hybrid ensembling approach that leverages the complementary strengths of two distinct modes of reasoning: Chain-of-Thought (CoT) and Program-of-Thought (PoT). We describe a general framework for combining these two forms of reasoning in self-consistency, as well as particular strategies for both full sampling and early-stopping. We show that CoT-PoT ensembling not only improves overall accuracy, but also drastically reduces the number of samples required for SC by a factor of 9.3x. In particular, the majority of tasks (78.6%) can be addressed with only two samples, which has not been possible with any prior SC methods.
SpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild?
Feb 03, 2026Spatial reasoning is a fundamental aspect of human cognition, yet it remains a major challenge for contemporary vision-language models (VLMs). Prior work largely relied on synthetic or LLM-generated environments with limited task designs and puzzle-like setups, failing to capture the real-world complexity, visual noise, and diverse spatial relationships that VLMs encounter. To address this, we introduce SpatiaLab, a comprehensive benchmark for evaluating VLMs' spatial reasoning in realistic, unconstrained contexts. SpatiaLab comprises 1,400 visual question-answer pairs across six major categories: Relative Positioning, Depth & Occlusion, Orientation, Size & Scale, Spatial Navigation, and 3D Geometry, each with five subcategories, yielding 30 distinct task types. Each subcategory contains at least 25 questions, and each main category includes at least 200 questions, supporting both multiple-choice and open-ended evaluation. Experiments across diverse state-of-the-art VLMs, including open- and closed-source models, reasoning-focused, and specialized spatial reasoning models, reveal a substantial gap in spatial reasoning capabilities compared with humans. In the multiple-choice setup, InternVL3.5-72B achieves 54.93% accuracy versus 87.57% for humans. In the open-ended setting, all models show a performance drop of around 10-25%, with GPT-5-mini scoring highest at 40.93% versus 64.93% for humans. These results highlight key limitations in handling complex spatial relationships, depth perception, navigation, and 3D geometry. By providing a diverse, real-world evaluation framework, SpatiaLab exposes critical challenges and opportunities for advancing VLMs' spatial reasoning, offering a benchmark to guide future research toward robust, human-aligned spatial understanding. SpatiaLab is available at: https://spatialab-reasoning.github.io/.
Do I Really Know? Learning Factual Self-Verification for Hallucination Reduction
Feb 02, 2026Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.
Instantiation-based Formalization of Logical Reasoning Tasks using Language Models and Logical Solvers
Jan 28, 2025

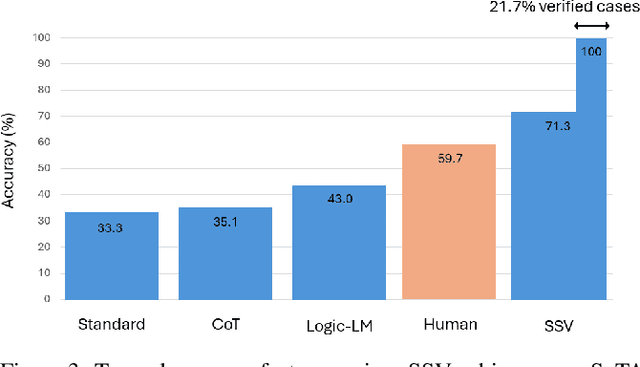
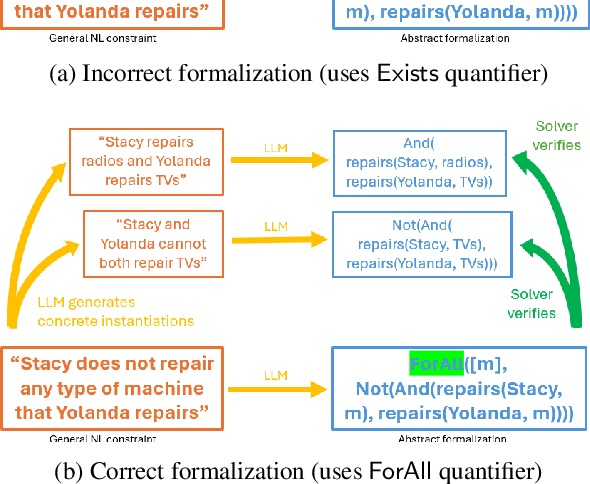
Robustness of reasoning remains a significant challenge for large language models, and addressing it is essential for the practical applicability of AI-driven reasoning systems. We introduce Semantic Self-Verification (SSV), a novel approach that addresses the key challenge in combining language models with the rigor of logical solvers: to accurately formulate the reasoning problem from natural language to the formal language of the solver. SSV uses a consistency-based approach to produce strong abstract formalizations of problems using concrete instantiations that are generated by the model and verified by the solver. In addition to significantly advancing the overall reasoning accuracy over the state-of-the-art, a key novelty that this approach presents is a feature of verification that has near-perfect precision over a significant coverage of cases, as we demonstrate on open reasoning benchmarks. We propose such *near-certain reasoning* as a new approach to reduce the need for manual verification in many cases, taking us closer to more dependable and autonomous AI reasoning systems.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023
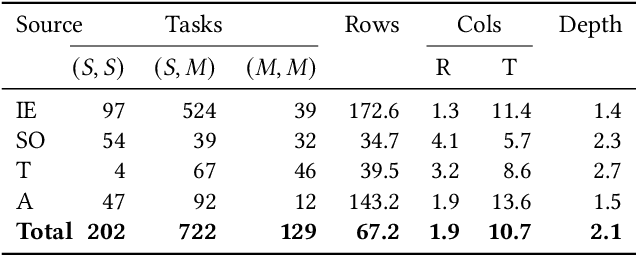

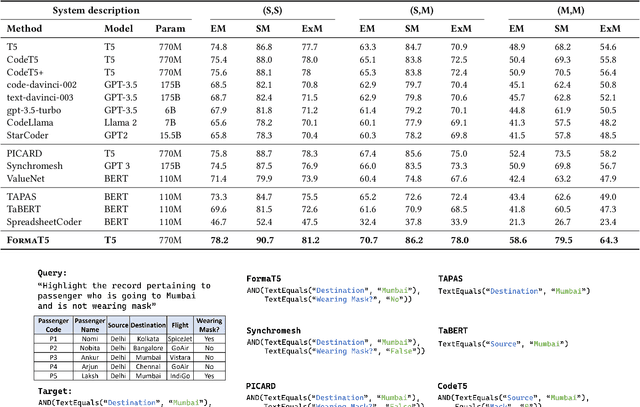
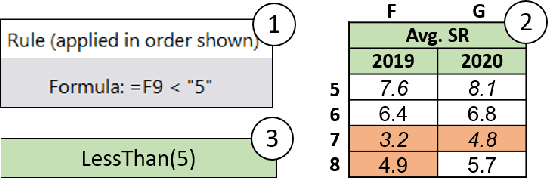
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.
From Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023



Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
CORNET: A neurosymbolic approach to learning conditional table formatting rules by example
Aug 22, 2022
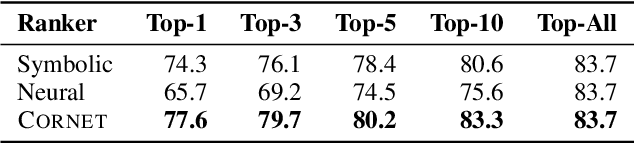

Spreadsheets are widely used for table manipulation and presentation. Stylistic formatting of these tables is an important property for both presentation and analysis. As a result, popular spreadsheet software, such as Excel, supports automatically formatting tables based on data-dependent rules. Unfortunately, writing these formatting rules can be challenging for users as that requires knowledge of the underlying rule language and data logic. In this paper, we present CORNET, a neuro-symbolic system that tackles the novel problem of automatically learning such formatting rules from user examples of formatted cells. CORNET takes inspiration from inductive program synthesis and combines symbolic rule enumeration, based on semi-supervised clustering and iterative decision tree learning, with a neural ranker to produce conditional formatting rules. To motivate and evaluate our approach, we extracted tables with formatting rules from a corpus of over 40K real spreadsheets. Using this data, we compared CORNET to a wide range of symbolic and neural baselines. Our results show that CORNET can learn rules more accurately, across varying conditions, compared to these baselines.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022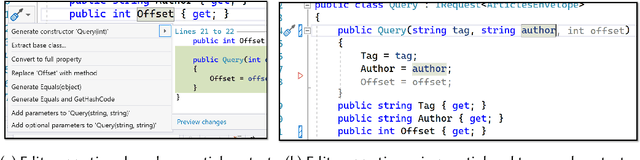


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
Landmarks and Regions: A Robust Approach to Data Extraction
Apr 11, 2022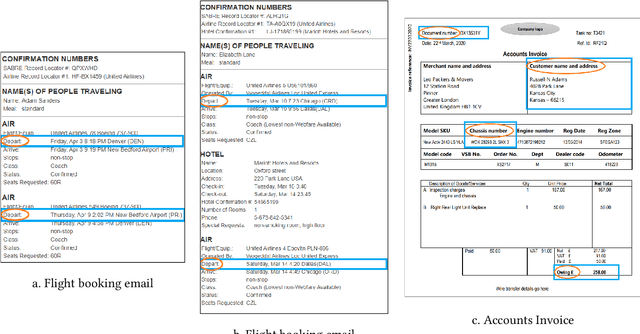
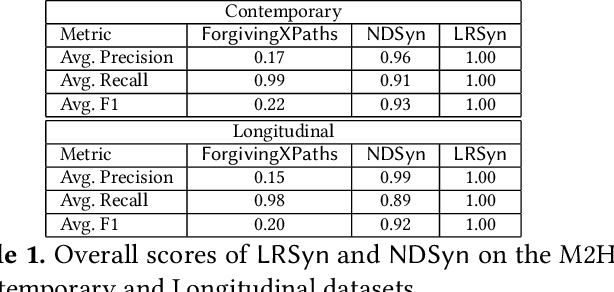
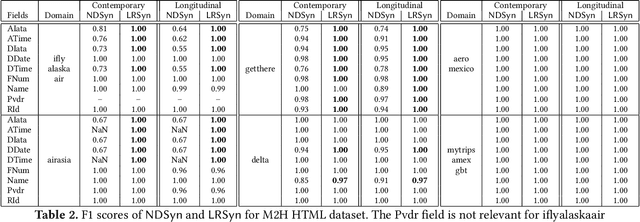
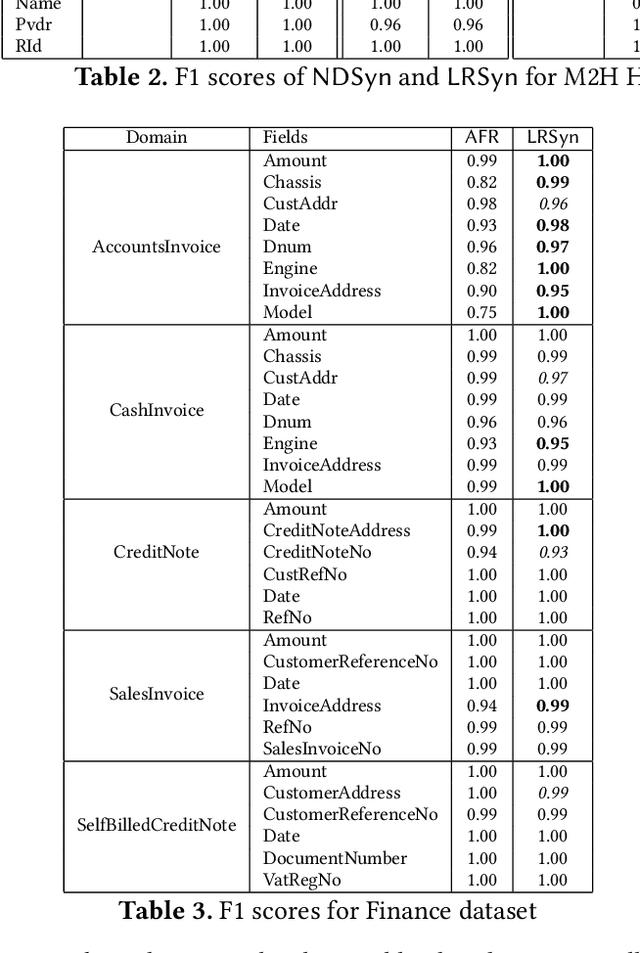
We propose a new approach to extracting data items or field values from semi-structured documents. Examples of such problems include extracting passenger name, departure time and departure airport from a travel itinerary, or extracting price of an item from a purchase receipt. Traditional approaches to data extraction use machine learning or program synthesis to process the whole document to extract the desired fields. Such approaches are not robust to format changes in the document, and the extraction process typically fails even if changes are made to parts of the document that are unrelated to the desired fields of interest. We propose a new approach to data extraction based on the concepts of landmarks and regions. Humans routinely use landmarks in manual processing of documents to zoom in and focus their attention on small regions of interest in the document. Inspired by this human intuition, we use the notion of landmarks in program synthesis to automatically synthesize extraction programs that first extract a small region of interest, and then automatically extract the desired value from the region in a subsequent step. We have implemented our landmark-based extraction approach in a tool LRSyn, and show extensive evaluation on documents in HTML as well as scanned images of invoices and receipts. Our results show that our approach is robust to various types of format changes that routinely happen in real-world settings.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021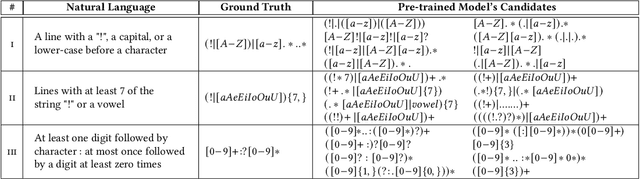


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.