 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Following by Boosting Attention of Large Language Models
Jun 16, 2025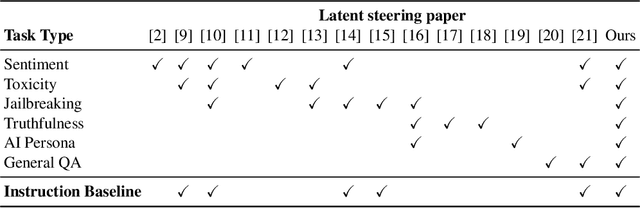
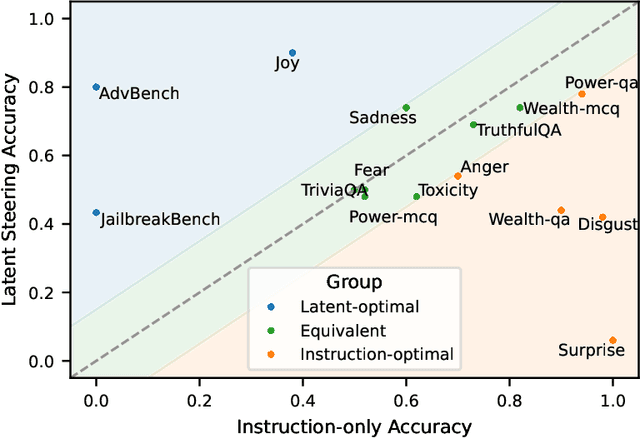
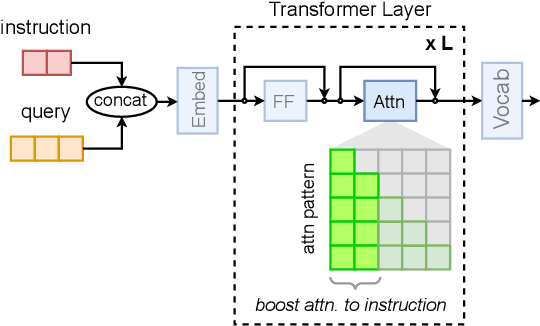

Controlling the generation of large language models (LLMs) remains a central challenge to ensure their safe and reliable deployment. While prompt engineering and finetuning are common approaches, recent work has explored latent steering, a lightweight technique that alters LLM internal activations to guide generation. However, subsequent studies revealed latent steering's effectiveness to be limited, often underperforming simple instruction prompting. To address this limitation, we first establish a benchmark across diverse behaviors for standardized evaluation of steering techniques. Building on insights from this benchmark, we introduce Instruction Attention Boosting (InstABoost), a latent steering method that boosts the strength of instruction prompting by altering the model's attention during generation. InstABoost combines the strengths of existing approaches and is theoretically supported by prior work that suggests that in-context rule following in transformer-based models can be controlled by manipulating attention on instructions. Empirically, InstABoost demonstrates superior control success compared to both traditional prompting and latent steering.
Logicbreaks: A Framework for Understanding Subversion of Rule-based Inference
Jun 21, 2024



We study how to subvert language models from following the rules. We model rule-following as inference in propositional Horn logic, a mathematical system in which rules have the form "if $P$ and $Q$, then $R$" for some propositions $P$, $Q$, and $R$. We prove that although transformers can faithfully abide by such rules, maliciously crafted prompts can nevertheless mislead even theoretically constructed models. Empirically, we find that attacks on our theoretical models mirror popular attacks on large language models. Our work suggests that studying smaller theoretical models can help understand the behavior of large language models in rule-based settings like logical reasoning and jailbreak attacks.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
KD-Lib: A PyTorch library for Knowledge Distillation, Pruning and Quantization
Nov 30, 2020

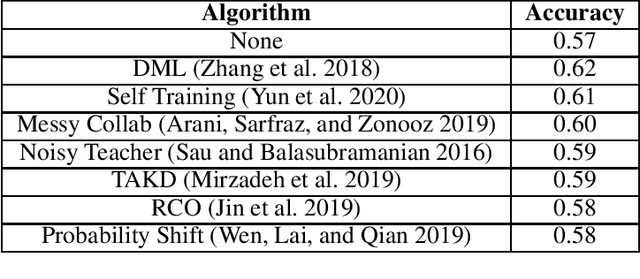
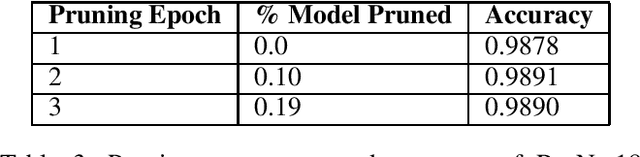
In recent years, the growing size of neural networks has led to a vast amount of research concerning compression techniques to mitigate the drawbacks of such large sizes. Most of these research works can be categorized into three broad families : Knowledge Distillation, Pruning, and Quantization. While there has been steady research in this domain, adoption and commercial usage of the proposed techniques has not quite progressed at the rate. We present KD-Lib, an open-source PyTorch based library, which contains state-of-the-art modular implementations of algorithms from the three families on top of multiple abstraction layers. KD-Lib is model and algorithm-agnostic, with extended support for hyperparameter tuning using Optuna and Tensorboard for logging and monitoring. The library can be found at - https://github.com/SforAiDl/KD_Lib.