 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Self-Sampled Correct and Partially-Correct Programs
May 28, 2022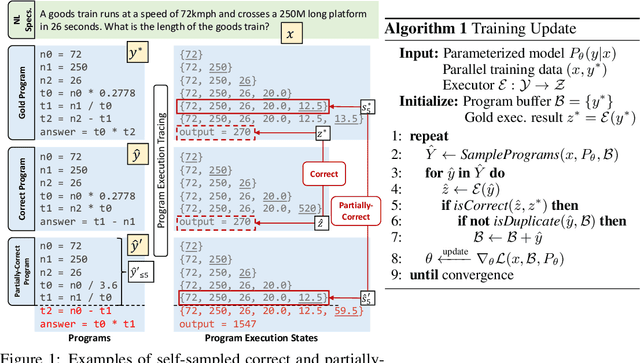

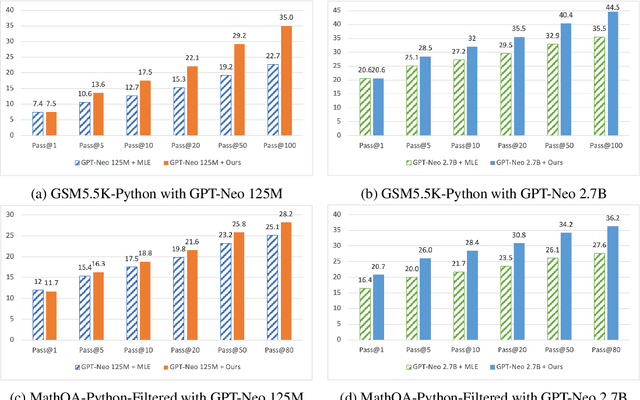
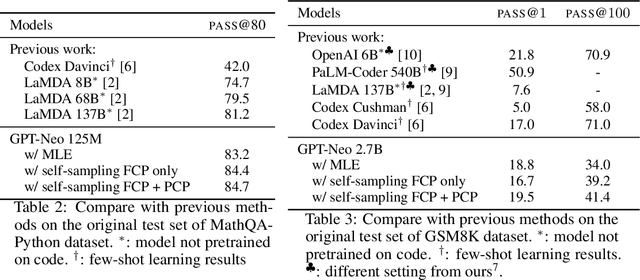
Program synthesis aims to generate executable programs that are consistent with the user specification. While there are often multiple programs that satisfy the same user specification, existing neural program synthesis models are often only learned from one reference program by maximizing its log-likelihood. This causes the model to be overly confident in its predictions as it sees the single solution repeatedly during training. This leads to poor generalization on unseen examples, even when multiple attempts are allowed. To mitigate this issue, we propose to let the model perform sampling during training and learn from both self-sampled fully-correct programs, which yield the gold execution results, as well as partially-correct programs, whose intermediate execution state matches another correct program. We show that our use of self-sampled correct and partially-correct programs can benefit learning and help guide the sampling process, leading to more efficient exploration of the program space. Additionally, we explore various training objectives to support learning from multiple programs per example and find they greatly affect the performance. Experiments on the MathQA and GSM8K datasets show that our proposed method improves the pass@k performance by 3.1% to 12.3% compared to learning from a single reference program with MLE.
Synchromesh: Reliable code generation from pre-trained language models
Jan 26, 2022

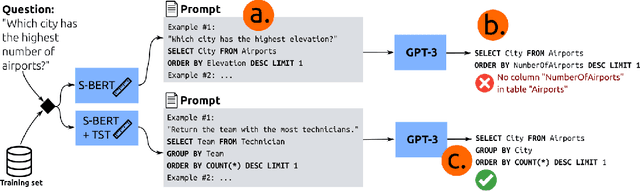
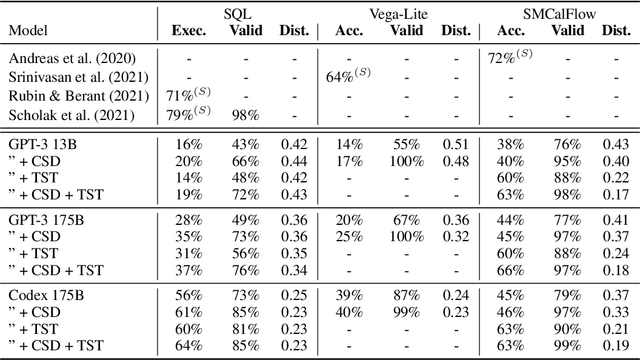
Large pre-trained language models have been used to generate code,providing a flexible interface for synthesizing programs from natural language specifications. However, they often violate syntactic and semantic rules of their output language, limiting their practical usability. In this paper, we propose Synchromesh: a framework for substantially improving the reliability of pre-trained models for code generation. Synchromesh comprises two components. First, it retrieves few-shot examples from a training bank using Target Similarity Tuning (TST), a novel method for semantic example selection. TST learns to recognize utterances that describe similar target programs despite differences in surface natural language features. Then, Synchromesh feeds the examples to a pre-trained language model and samples programs using Constrained Semantic Decoding (CSD): a general framework for constraining the output to a set of valid programs in the target language. CSD leverages constraints on partial outputs to sample complete correct programs, and needs neither re-training nor fine-tuning of the language model. We evaluate our methods by synthesizing code from natural language descriptions using GPT-3 and Codex in three real-world languages: SQL queries, Vega-Lite visualizations and SMCalFlow programs. These domains showcase rich constraints that CSD is able to enforce, including syntax, scope, typing rules, and contextual logic. We observe substantial complementary gains from CSD and TST in prediction accuracy and in effectively preventing run-time errors.
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
Nov 04, 2021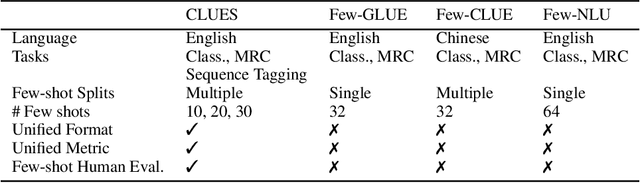
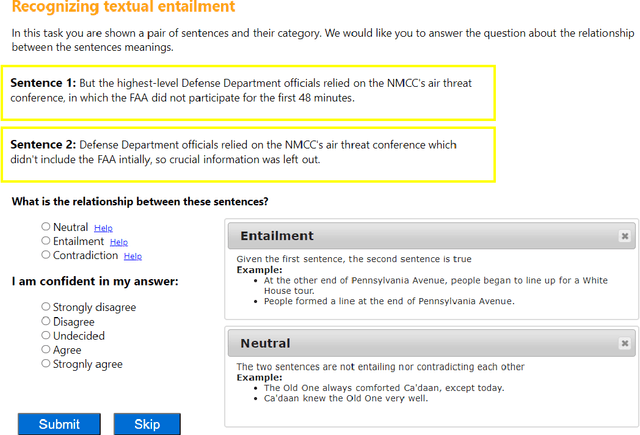

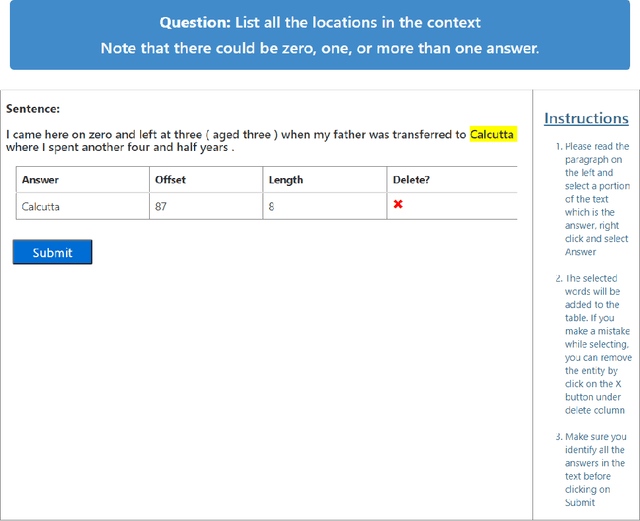
Most recent progress in natural language understanding (NLU) has been driven, in part, by benchmarks such as GLUE, SuperGLUE, SQuAD, etc. In fact, many NLU models have now matched or exceeded "human-level" performance on many tasks in these benchmarks. Most of these benchmarks, however, give models access to relatively large amounts of labeled data for training. As such, the models are provided far more data than required by humans to achieve strong performance. That has motivated a line of work that focuses on improving few-shot learning performance of NLU models. However, there is a lack of standardized evaluation benchmarks for few-shot NLU resulting in different experimental settings in different papers. To help accelerate this line of work, we introduce CLUES (Constrained Language Understanding Evaluation Standard), a benchmark for evaluating the few-shot learning capabilities of NLU models. We demonstrate that while recent models reach human performance when they have access to large amounts of labeled data, there is a huge gap in performance in the few-shot setting for most tasks. We also demonstrate differences between alternative model families and adaptation techniques in the few shot setting. Finally, we discuss several principles and choices in designing the experimental settings for evaluating the true few-shot learning performance and suggest a unified standardized approach to few-shot learning evaluation. We aim to encourage research on NLU models that can generalize to new tasks with a small number of examples. Code and data for CLUES are available at https://github.com/microsoft/CLUES.
NL-EDIT: Correcting semantic parse errors through natural language interaction
Mar 26, 2021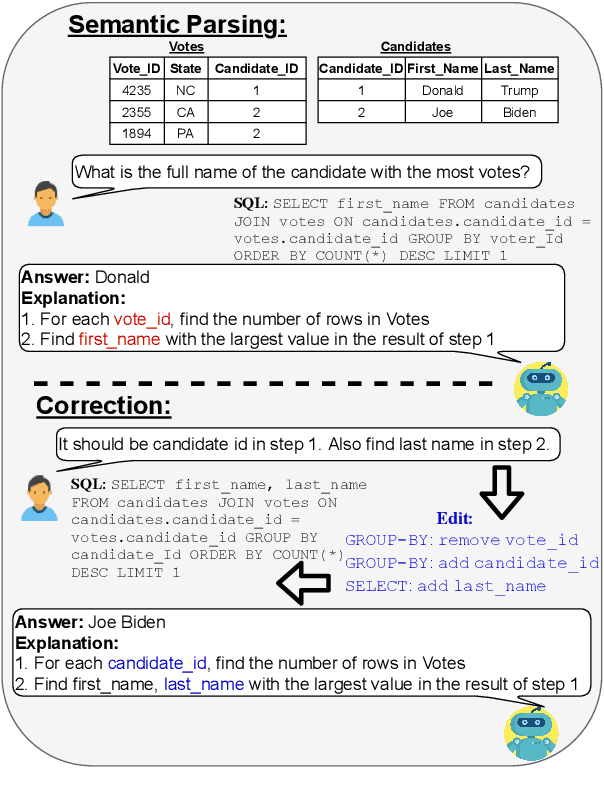


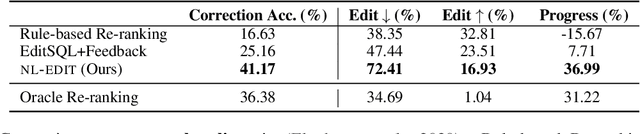
We study semantic parsing in an interactive setting in which users correct errors with natural language feedback. We present NL-EDIT, a model for interpreting natural language feedback in the interaction context to generate a sequence of edits that can be applied to the initial parse to correct its errors. We show that NL-EDIT can boost the accuracy of existing text-to-SQL parsers by up to 20% with only one turn of correction. We analyze the limitations of the model and discuss directions for improvement and evaluation. The code and datasets used in this paper are publicly available at http://aka.ms/NLEdit.
Structure-Grounded Pretraining for Text-to-SQL
Oct 24, 2020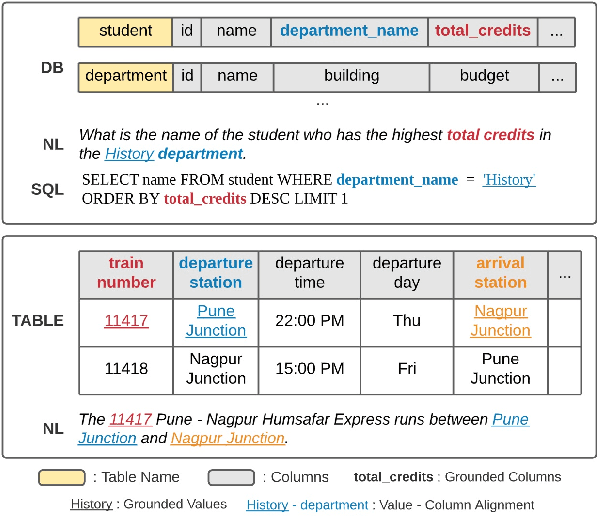
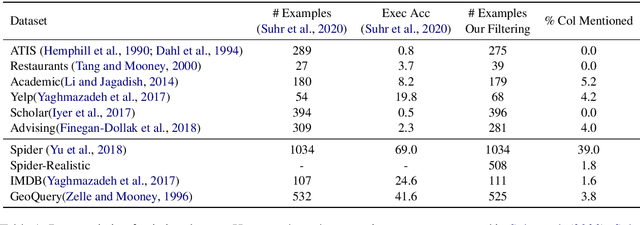
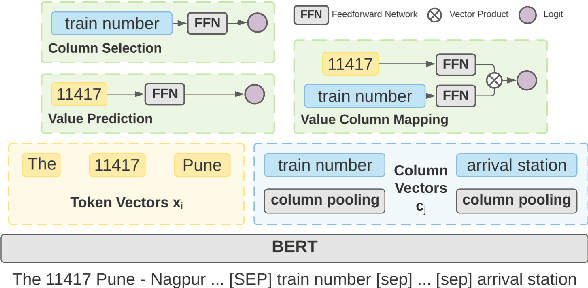

Learning to capture text-table alignment is essential for table related tasks like text-to-SQL. The model needs to correctly recognize natural language references to columns and values and to ground them in the given database schema. In this paper, we present a novel weakly supervised Structure-Grounded pretraining framework (StruG) for text-to-SQL that can effectively learn to capture text-table alignment based on a parallel text-table corpus. We identify a set of novel prediction tasks: column grounding, value grounding and column-value mapping, and train them using weak supervision without requiring complex SQL annotation. Additionally, to evaluate the model under a more realistic setting, we create a new evaluation set Spider-Realistic based on Spider with explicit mentions of column names removed, and adopt two existing single-database text-to-SQL datasets. StruG significantly outperforms BERT-LARGE on Spider and the realistic evaluation sets, while bringing consistent improvement on the large-scale WikiSQL benchmark.
Machine Teaching: A New Paradigm for Building Machine Learning Systems
Aug 11, 2017
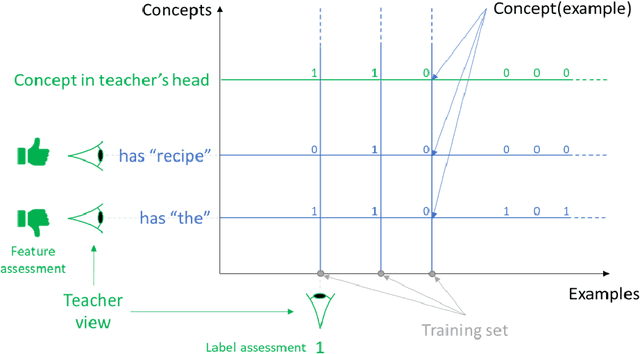
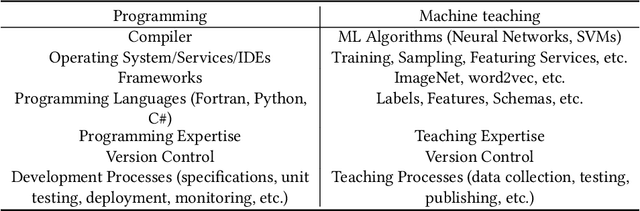
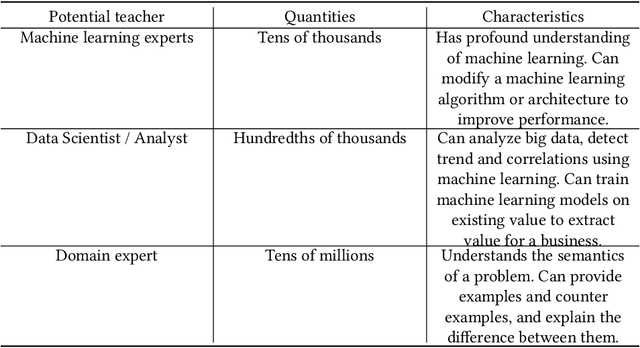
The current processes for building machine learning systems require practitioners with deep knowledge of machine learning. This significantly limits the number of machine learning systems that can be created and has led to a mismatch between the demand for machine learning systems and the ability for organizations to build them. We believe that in order to meet this growing demand for machine learning systems we must significantly increase the number of individuals that can teach machines. We postulate that we can achieve this goal by making the process of teaching machines easy, fast and above all, universally accessible. While machine learning focuses on creating new algorithms and improving the accuracy of "learners", the machine teaching discipline focuses on the efficacy of the "teachers". Machine teaching as a discipline is a paradigm shift that follows and extends principles of software engineering and programming languages. We put a strong emphasis on the teacher and the teacher's interaction with data, as well as crucial components such as techniques and design principles of interaction and visualization. In this paper, we present our position regarding the discipline of machine teaching and articulate fundamental machine teaching principles. We also describe how, by decoupling knowledge about machine learning algorithms from the process of teaching, we can accelerate innovation and empower millions of new uses for machine learning models.
A Characterization of Prediction Errors
Nov 18, 2016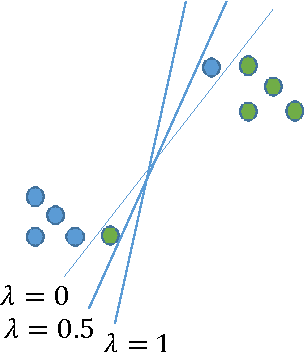
Understanding prediction errors and determining how to fix them is critical to building effective predictive systems. In this paper, we delineate four types of prediction errors and demonstrate that these four types characterize all prediction errors. In addition, we describe potential remedies and tools that can be used to reduce the uncertainty when trying to determine the source of a prediction error and when trying to take action to remove a prediction errors.
Analysis of a Design Pattern for Teaching with Features and Labels
Nov 18, 2016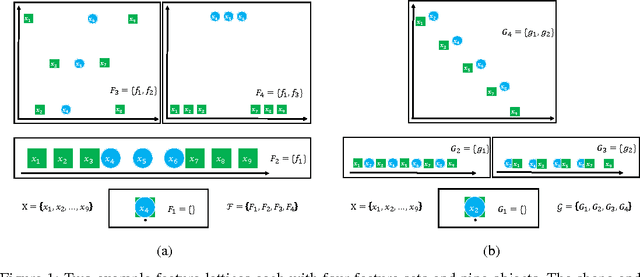
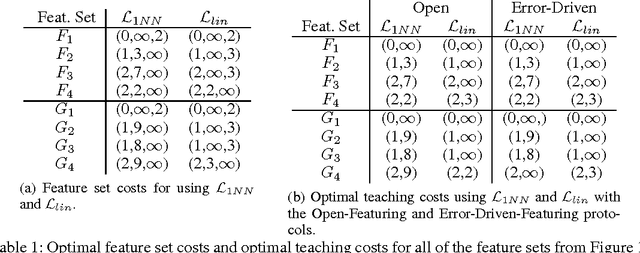

We study the task of teaching a machine to classify objects using features and labels. We introduce the Error-Driven-Featuring design pattern for teaching using features and labels in which a teacher prefers to introduce features only if they are needed. We analyze the potential risks and benefits of this teaching pattern through the use of teaching protocols, illustrative examples, and by providing bounds on the effort required for an optimal machine teacher using a linear learning algorithm, the most commonly used type of learners in interactive machine learning systems. Our analysis provides a deeper understanding of potential trade-offs of using different learning algorithms and between the effort required for featuring (creating new features) and labeling (providing labels for objects).
Selective Greedy Equivalence Search: Finding Optimal Bayesian Networks Using a Polynomial Number of Score Evaluations
Jun 06, 2015



We introduce Selective Greedy Equivalence Search (SGES), a restricted version of Greedy Equivalence Search (GES). SGES retains the asymptotic correctness of GES but, unlike GES, has polynomial performance guarantees. In particular, we show that when data are sampled independently from a distribution that is perfect with respect to a DAG ${\cal G}$ defined over the observable variables then, in the limit of large data, SGES will identify ${\cal G}$'s equivalence class after a number of score evaluations that is (1) polynomial in the number of nodes and (2) exponential in various complexity measures including maximum-number-of-parents, maximum-clique-size, and a new measure called {\em v-width} that is at least as small as---and potentially much smaller than---the other two. More generally, we show that for any hereditary and equivalence-invariant property $\Pi$ known to hold in ${\cal G}$, we retain the large-sample optimality guarantees of GES even if we ignore any GES deletion operator during the backward phase that results in a state for which $\Pi$ does not hold in the common-descendants subgraph.
Asymptotic Model Selection for Directed Networks with Hidden Variables
May 16, 2015We extend the Bayesian Information Criterion (BIC), an asymptotic approximation for the marginal likelihood, to Bayesian networks with hidden variables. This approximation can be used to select models given large samples of data. The standard BIC as well as our extension punishes the complexity of a model according to the dimension of its parameters. We argue that the dimension of a Bayesian network with hidden variables is the rank of the Jacobian matrix of the transformation between the parameters of the network and the parameters of the observable variables. We compute the dimensions of several networks including the naive Bayes model with a hidden root node.