 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of NIPS 2017 Symposium on Interpretable Machine Learning
Dec 12, 2017This is the Proceedings of NIPS 2017 Symposium on Interpretable Machine Learning, held in Long Beach, California, USA on December 7, 2017
Analysis of a Design Pattern for Teaching with Features and Labels
Nov 18, 2016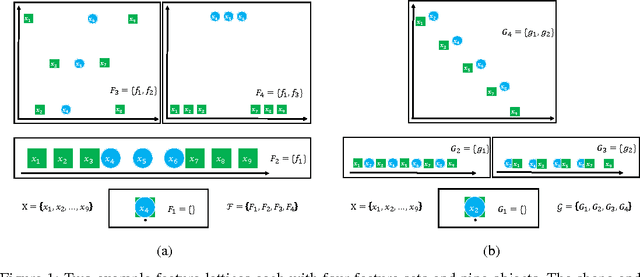
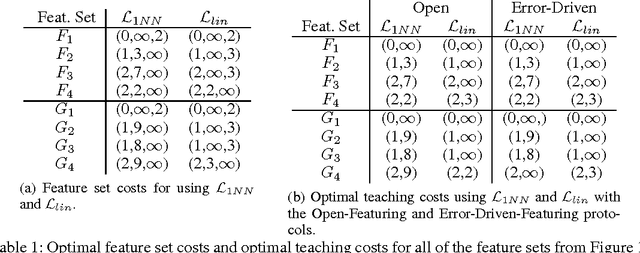

We study the task of teaching a machine to classify objects using features and labels. We introduce the Error-Driven-Featuring design pattern for teaching using features and labels in which a teacher prefers to introduce features only if they are needed. We analyze the potential risks and benefits of this teaching pattern through the use of teaching protocols, illustrative examples, and by providing bounds on the effort required for an optimal machine teacher using a linear learning algorithm, the most commonly used type of learners in interactive machine learning systems. Our analysis provides a deeper understanding of potential trade-offs of using different learning algorithms and between the effort required for featuring (creating new features) and labeling (providing labels for objects).
Interactive Semantic Featuring for Text Classification
Jun 24, 2016
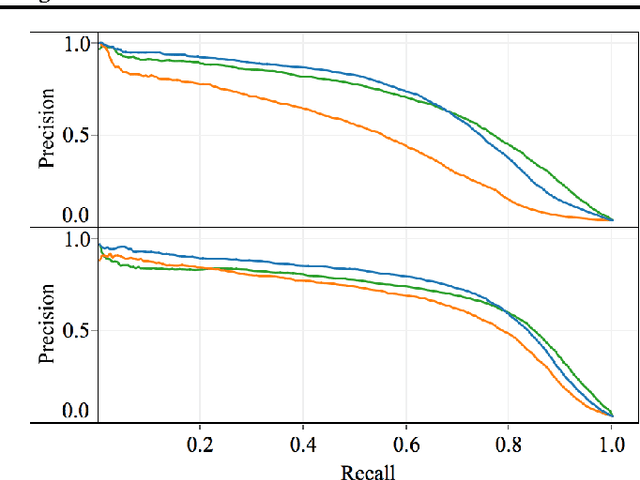

In text classification, dictionaries can be used to define human-comprehensible features. We propose an improvement to dictionary features called smoothed dictionary features. These features recognize document contexts instead of n-grams. We describe a principled methodology to solicit dictionary features from a teacher, and present results showing that models built using these human-comprehensible features are competitive with models trained with Bag of Words features.
ICE: Enabling Non-Experts to Build Models Interactively for Large-Scale Lopsided Problems
Sep 16, 2014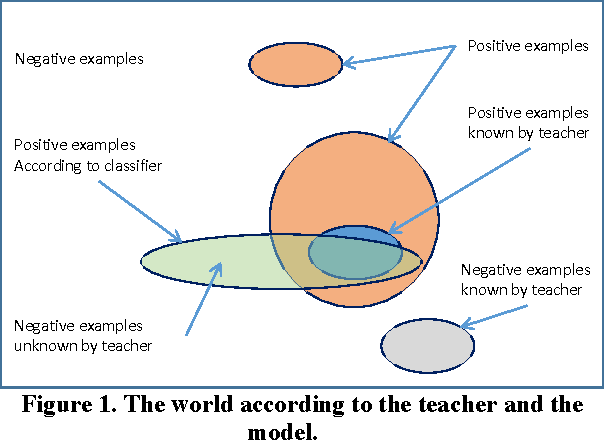
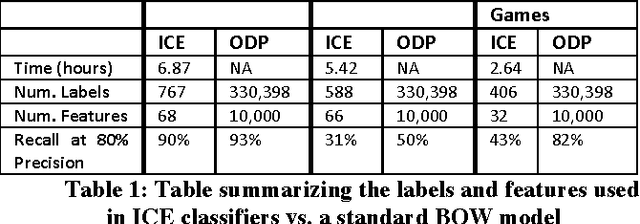
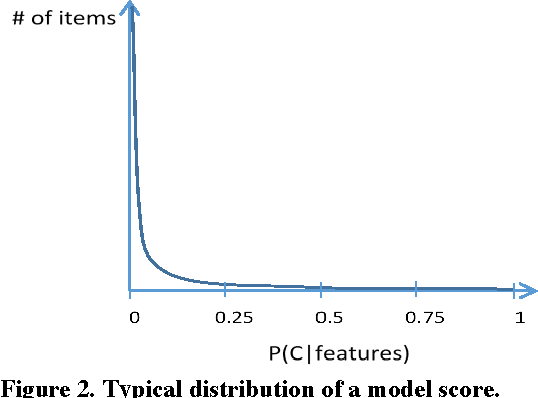
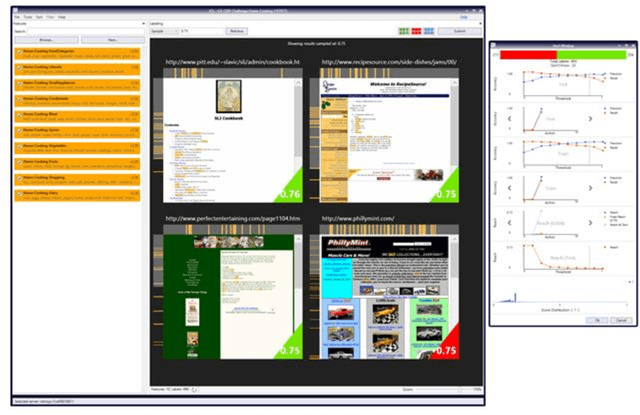
Quick interaction between a human teacher and a learning machine presents numerous benefits and challenges when working with web-scale data. The human teacher guides the machine towards accomplishing the task of interest. The learning machine leverages big data to find examples that maximize the training value of its interaction with the teacher. When the teacher is restricted to labeling examples selected by the machine, this problem is an instance of active learning. When the teacher can provide additional information to the machine (e.g., suggestions on what examples or predictive features should be used) as the learning task progresses, then the problem becomes one of interactive learning. To accommodate the two-way communication channel needed for efficient interactive learning, the teacher and the machine need an environment that supports an interaction language. The machine can access, process, and summarize more examples than the teacher can see in a lifetime. Based on the machine's output, the teacher can revise the definition of the task or make it more precise. Both the teacher and the machine continuously learn and benefit from the interaction. We have built a platform to (1) produce valuable and deployable models and (2) support research on both the machine learning and user interface challenges of the interactive learning problem. The platform relies on a dedicated, low-latency, distributed, in-memory architecture that allows us to construct web-scale learning machines with quick interaction speed. The purpose of this paper is to describe this architecture and demonstrate how it supports our research efforts. Preliminary results are presented as illustrations of the architecture but are not the primary focus of the paper.
Counterfactual Reasoning and Learning Systems
Jul 27, 2013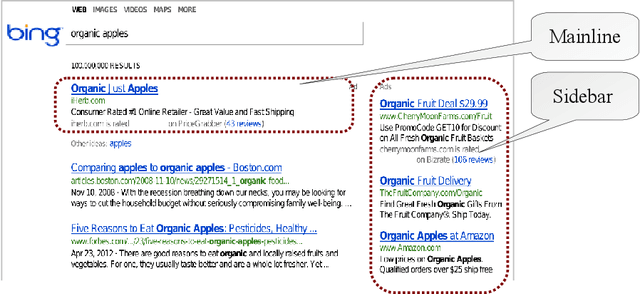


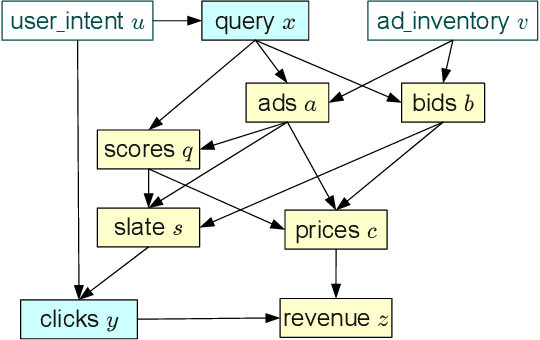
This work shows how to leverage causal inference to understand the behavior of complex learning systems interacting with their environment and predict the consequences of changes to the system. Such predictions allow both humans and algorithms to select changes that improve both the short-term and long-term performance of such systems. This work is illustrated by experiments carried out on the ad placement system associated with the Bing search engine.