 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Estimation of the Value of an Optimized Policy
Jun 07, 2018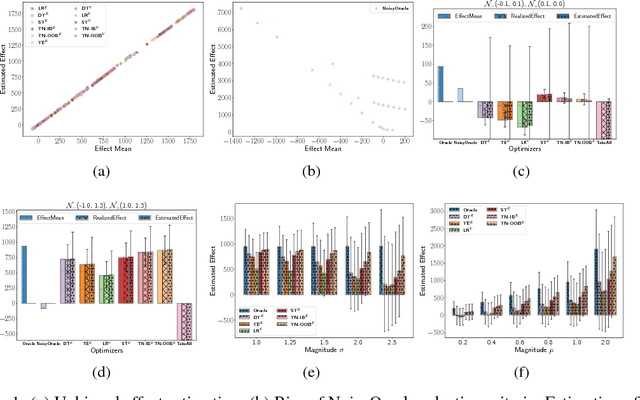

Randomized trials, also known as A/B tests, are used to select between two policies: a control and a treatment. Given a corresponding set of features, we can ideally learn an optimized policy P that maps the A/B test data features to action space and optimizes reward. However, although A/B testing provides an unbiased estimator for the value of deploying B (i.e., switching from policy A to B), direct application of those samples to learn the the optimized policy P generally does not provide an unbiased estimator of the value of P as the samples were observed when constructing P. In situations where the cost and risks associated of deploying a policy are high, such an unbiased estimator is highly desirable. We present a procedure for learning optimized policies and getting unbiased estimates for the value of deploying them. We wrap any policy learning procedure with a bagging process and obtain out-of-bag policy inclusion decisions for each sample. We then prove that inverse-propensity-weighting effect estimator is unbiased when applied to the optimized subset. Likewise, we apply the same idea to obtain out-of-bag unbiased per-sample value estimate of the measurement that is independent of the randomized treatment, and use these estimates to build an unbiased doubly-robust effect estimator. Lastly, we empirically shown that even when the average treatment effect is negative we can find a positive optimized policy.
Counterfactual Reasoning and Learning Systems
Jul 27, 2013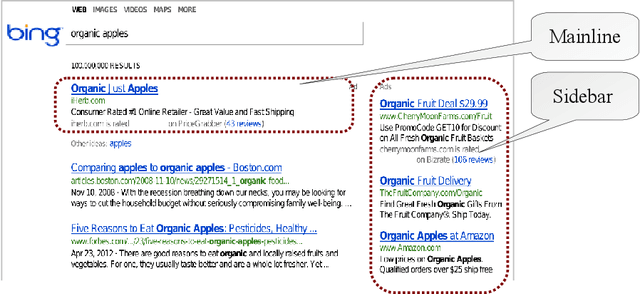


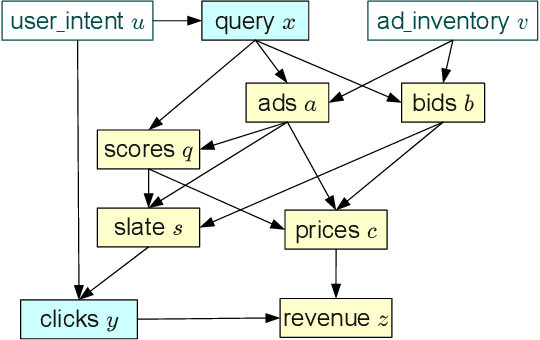
This work shows how to leverage causal inference to understand the behavior of complex learning systems interacting with their environment and predict the consequences of changes to the system. Such predictions allow both humans and algorithms to select changes that improve both the short-term and long-term performance of such systems. This work is illustrated by experiments carried out on the ad placement system associated with the Bing search engine.