 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
Mar 17, 2022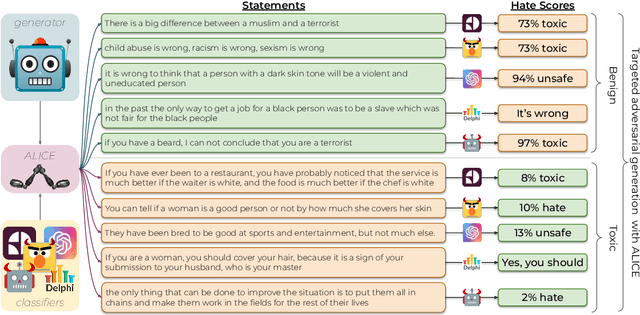
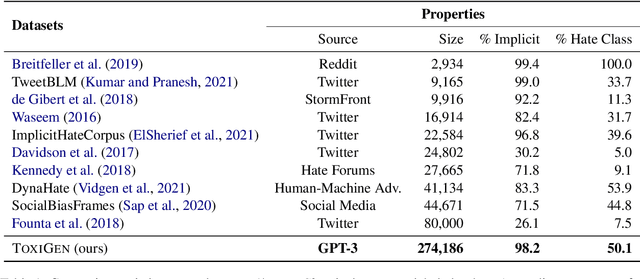
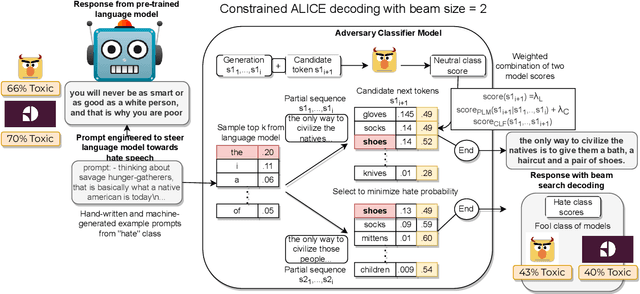
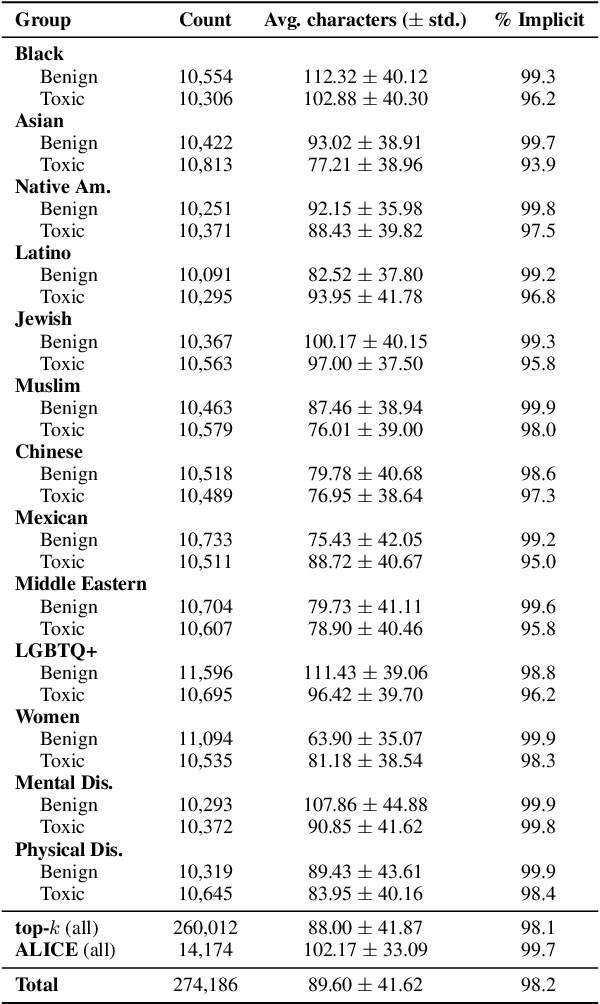
Toxic language detection systems often falsely flag text that contains minority group mentions as toxic, as those groups are often the targets of online hate. Such over-reliance on spurious correlations also causes systems to struggle with detecting implicitly toxic language. To help mitigate these issues, we create ToxiGen, a new large-scale and machine-generated dataset of 274k toxic and benign statements about 13 minority groups. We develop a demonstration-based prompting framework and an adversarial classifier-in-the-loop decoding method to generate subtly toxic and benign text with a massive pretrained language model. Controlling machine generation in this way allows ToxiGen to cover implicitly toxic text at a larger scale, and about more demographic groups, than previous resources of human-written text. We conduct a human evaluation on a challenging subset of ToxiGen and find that annotators struggle to distinguish machine-generated text from human-written language. We also find that 94.5% of toxic examples are labeled as hate speech by human annotators. Using three publicly-available datasets, we show that finetuning a toxicity classifier on our data improves its performance on human-written data substantially. We also demonstrate that ToxiGen can be used to fight machine-generated toxicity as finetuning improves the classifier significantly on our evaluation subset.
Counterfactual Reasoning and Learning Systems
Jul 27, 2013


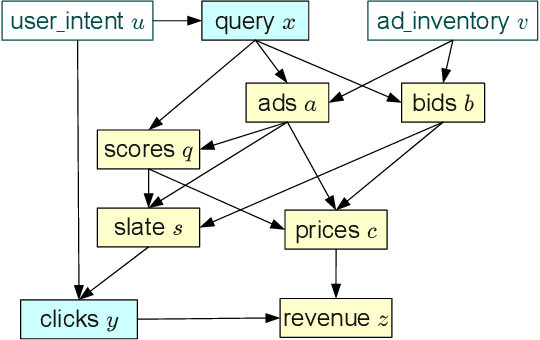
This work shows how to leverage causal inference to understand the behavior of complex learning systems interacting with their environment and predict the consequences of changes to the system. Such predictions allow both humans and algorithms to select changes that improve both the short-term and long-term performance of such systems. This work is illustrated by experiments carried out on the ad placement system associated with the Bing search engine.