 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Interactive Debugging and Steering of Multi-Agent AI Systems
Mar 03, 2025Fully autonomous teams of LLM-powered AI agents are emerging that collaborate to perform complex tasks for users. What challenges do developers face when trying to build and debug these AI agent teams? In formative interviews with five AI agent developers, we identify core challenges: difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for tool support to iterate on agent configuration. Based on these needs, we developed an interactive multi-agent debugging tool, AGDebugger, with a UI for browsing and sending messages, the ability to edit and reset prior agent messages, and an overview visualization for navigating complex message histories. In a two-part user study with 14 participants, we identify common user strategies for steering agents and highlight the importance of interactive message resets for debugging. Our studies deepen understanding of interfaces for debugging increasingly important agentic workflows.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024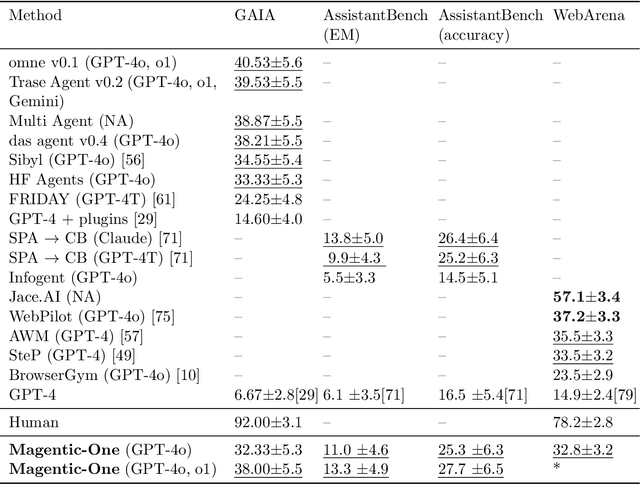
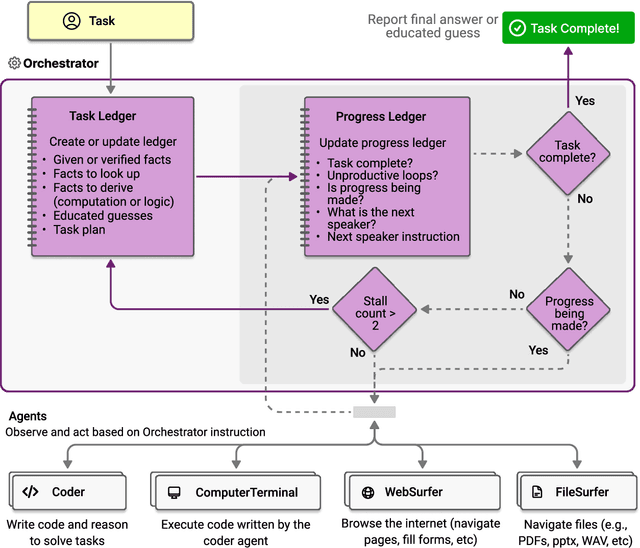
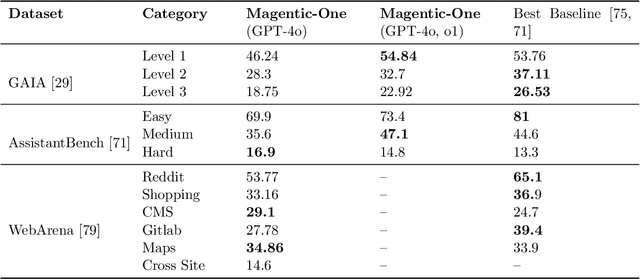
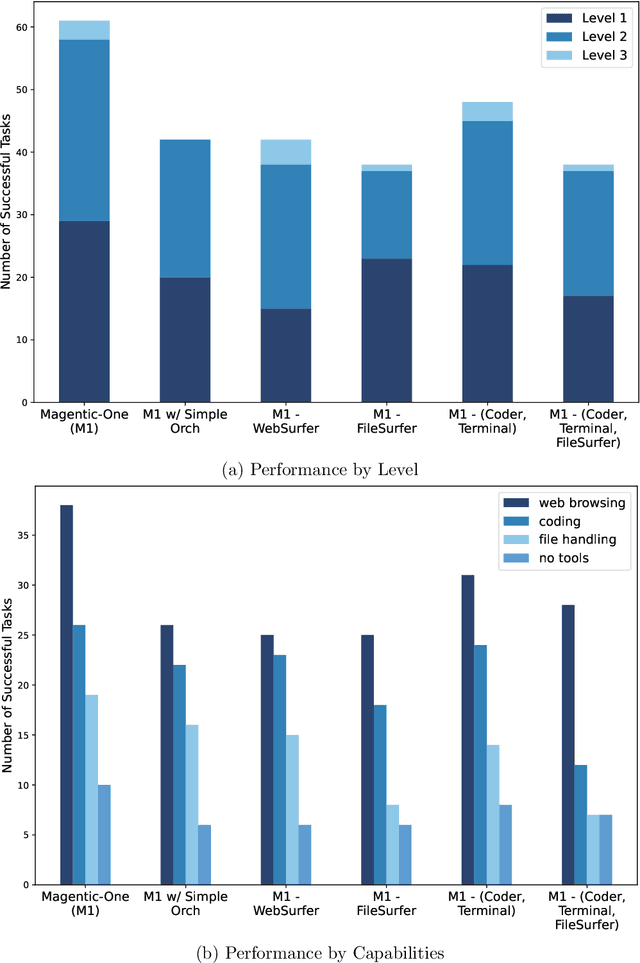
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
Jun 07, 2023Large language models (LLMs) can be used to generate text data for training and evaluating other models. However, creating high-quality datasets with LLMs can be challenging. In this work, we explore human-AI partnerships to facilitate high diversity and accuracy in LLM-based text data generation. We first examine two approaches to diversify text generation: 1) logit suppression, which minimizes the generation of languages that have already been frequently generated, and 2) temperature sampling, which flattens the token sampling probability. We found that diversification approaches can increase data diversity but often at the cost of data accuracy (i.e., text and labels being appropriate for the target domain). To address this issue, we examined two human interventions, 1) label replacement (LR), correcting misaligned labels, and 2) out-of-scope filtering (OOSF), removing instances that are out of the user's domain of interest or to which no considered label applies. With oracle studies, we found that LR increases the absolute accuracy of models trained with diversified datasets by 14.4%. Moreover, we found that some models trained with data generated with LR interventions outperformed LLM-based few-shot classification. In contrast, OOSF was not effective in increasing model accuracy, implying the need for future work in human-in-the-loop text data generation.
Supporting Human-AI Collaboration in Auditing LLMs with LLMs
Apr 19, 2023



Large language models are becoming increasingly pervasive and ubiquitous in society via deployment in sociotechnical systems. Yet these language models, be it for classification or generation, have been shown to be biased and behave irresponsibly, causing harm to people at scale. It is crucial to audit these language models rigorously. Existing auditing tools leverage either or both humans and AI to find failures. In this work, we draw upon literature in human-AI collaboration and sensemaking, and conduct interviews with research experts in safe and fair AI, to build upon the auditing tool: AdaTest (Ribeiro and Lundberg, 2022), which is powered by a generative large language model (LLM). Through the design process we highlight the importance of sensemaking and human-AI communication to leverage complementary strengths of humans and generative models in collaborative auditing. To evaluate the effectiveness of the augmented tool, AdaTest++, we conduct user studies with participants auditing two commercial language models: OpenAI's GPT-3 and Azure's sentiment analysis model. Qualitative analysis shows that AdaTest++ effectively leverages human strengths such as schematization, hypothesis formation and testing. Further, with our tool, participants identified a variety of failures modes, covering 26 different topics over 2 tasks, that have been shown before in formal audits and also those previously under-reported.
Aligning Offline Metrics and Human Judgments of Value of AI-Pair Programmers
Oct 29, 2022Large language models trained on massive amounts of natural language data and code have shown impressive capabilities in automatic code generation scenarios. Development and evaluation of these models has largely been driven by offline functional correctness metrics, which consider a task to be solved if the generated code passes corresponding unit tests. While functional correctness is clearly an important property of a code generation model, we argue that it may not fully capture what programmers value when collaborating with their AI pair programmers. For example, while a nearly correct suggestion that does not consider edge cases may fail a unit test, it may still provide a substantial starting point or hint to the programmer, thereby reducing total needed effort to complete a coding task. To investigate this, we conduct a user study with (N=49) experienced programmers, and find that while both correctness and effort correlate with value, the association is strongest for effort. We argue that effort should be considered as an important dimension of evaluation in code generation scenarios. We also find that functional correctness remains better at identifying the highest-value generations; but participants still saw considerable value in code that failed unit tests. Conversely, similarity-based metrics are very good at identifying the lowest-value generations among those that fail unit tests. Based on these findings, we propose a simple hybrid metric, which combines functional correctness and similarity-based metrics to capture different dimensions of what programmers might value and show that this hybrid metric more strongly correlates with both value and effort. Our findings emphasize the importance of designing human-centered metrics that capture what programmers need from and value in their AI pair programmers.
How Different Groups Prioritize Ethical Values for Responsible AI
May 16, 2022
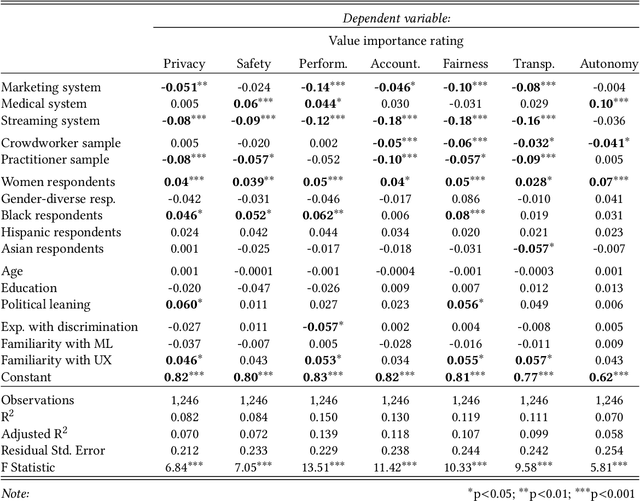
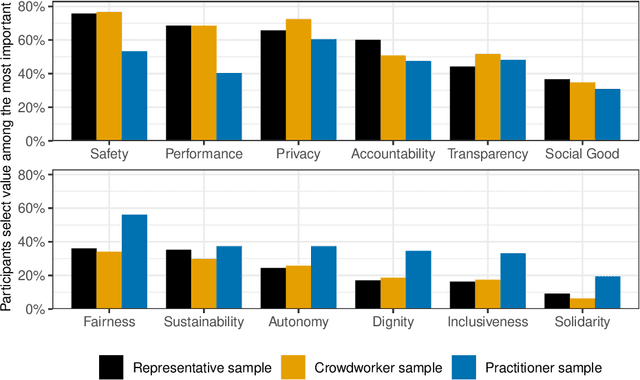
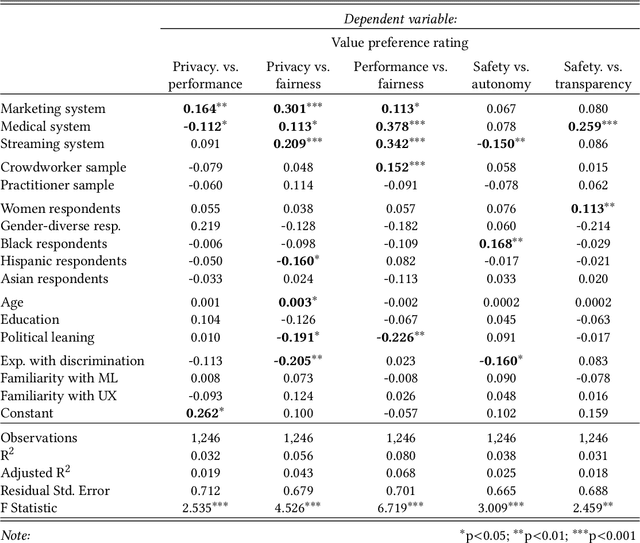
Private companies, public sector organizations, and academic groups have outlined ethical values they consider important for responsible artificial intelligence technologies. While their recommendations converge on a set of central values, little is known about the values a more representative public would find important for the AI technologies they interact with and might be affected by. We conducted a survey examining how individuals perceive and prioritize responsible AI values across three groups: a representative sample of the US population (N=743), a sample of crowdworkers (N=755), and a sample of AI practitioners (N=175). Our results empirically confirm a common concern: AI practitioners' value priorities differ from those of the general public. Compared to the US-representative sample, AI practitioners appear to consider responsible AI values as less important and emphasize a different set of values. In contrast, self-identified women and black respondents found responsible AI values more important than other groups. Surprisingly, more liberal-leaning participants, rather than participants reporting experiences with discrimination, were more likely to prioritize fairness than other groups. Our findings highlight the importance of paying attention to who gets to define responsible AI.
REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research
May 05, 2022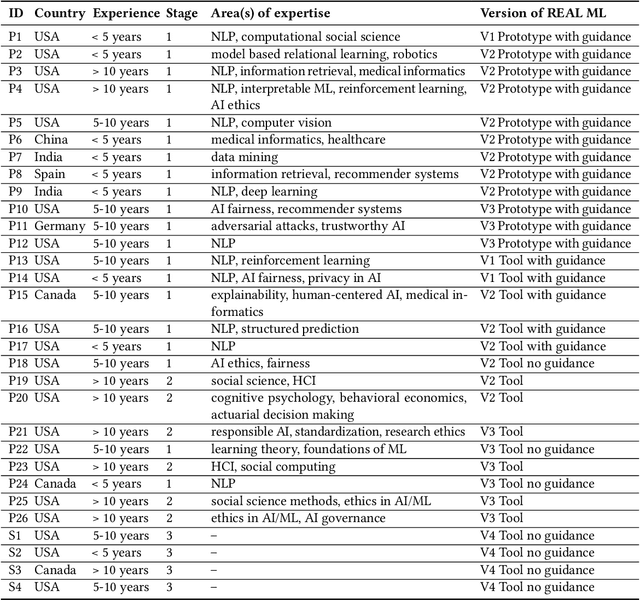
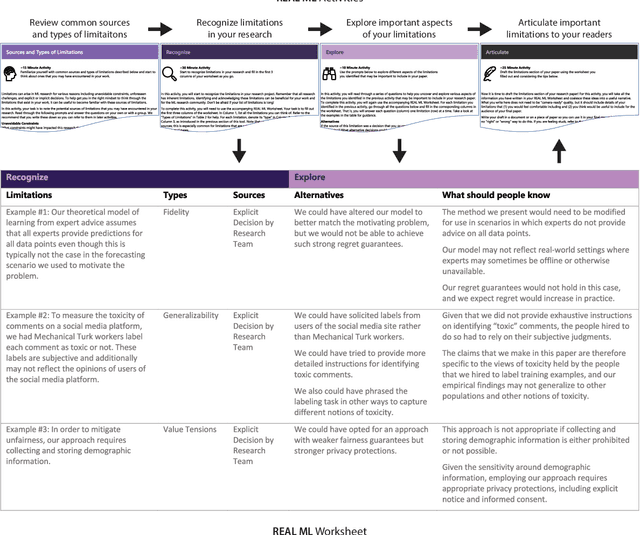
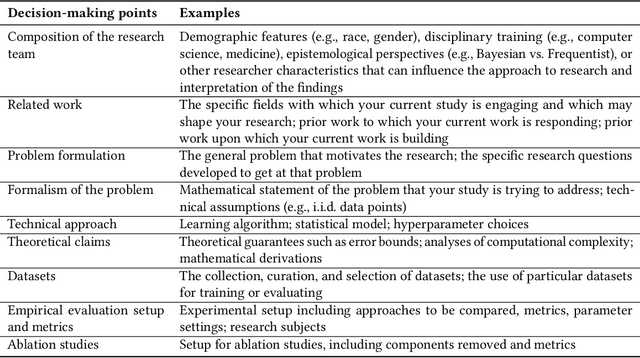

Transparency around limitations can improve the scientific rigor of research, help ensure appropriate interpretation of research findings, and make research claims more credible. Despite these benefits, the machine learning (ML) research community lacks well-developed norms around disclosing and discussing limitations. To address this gap, we conduct an iterative design process with 30 ML and ML-adjacent researchers to develop and test REAL ML, a set of guided activities to help ML researchers recognize, explore, and articulate the limitations of their research. Using a three-stage interview and survey study, we identify ML researchers' perceptions of limitations, as well as the challenges they face when recognizing, exploring, and articulating limitations. We develop REAL ML to address some of these practical challenges, and highlight additional cultural challenges that will require broader shifts in community norms to address. We hope our study and REAL ML help move the ML research community toward more active and appropriate engagement with limitations.
Machine Teaching: A New Paradigm for Building Machine Learning Systems
Aug 11, 2017
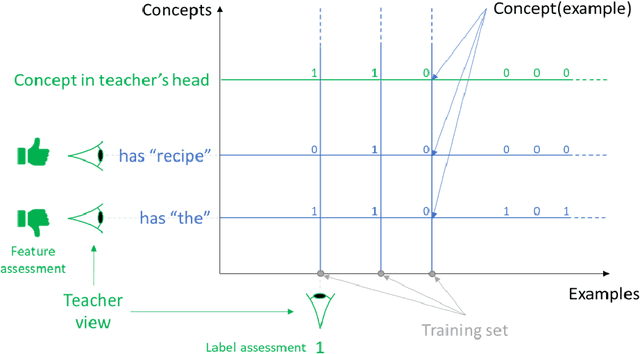
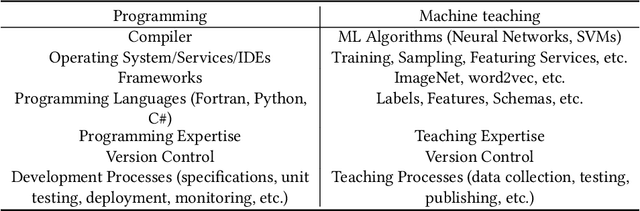
The current processes for building machine learning systems require practitioners with deep knowledge of machine learning. This significantly limits the number of machine learning systems that can be created and has led to a mismatch between the demand for machine learning systems and the ability for organizations to build them. We believe that in order to meet this growing demand for machine learning systems we must significantly increase the number of individuals that can teach machines. We postulate that we can achieve this goal by making the process of teaching machines easy, fast and above all, universally accessible. While machine learning focuses on creating new algorithms and improving the accuracy of "learners", the machine teaching discipline focuses on the efficacy of the "teachers". Machine teaching as a discipline is a paradigm shift that follows and extends principles of software engineering and programming languages. We put a strong emphasis on the teacher and the teacher's interaction with data, as well as crucial components such as techniques and design principles of interaction and visualization. In this paper, we present our position regarding the discipline of machine teaching and articulate fundamental machine teaching principles. We also describe how, by decoupling knowledge about machine learning algorithms from the process of teaching, we can accelerate innovation and empower millions of new uses for machine learning models.
ICE: Enabling Non-Experts to Build Models Interactively for Large-Scale Lopsided Problems
Sep 16, 2014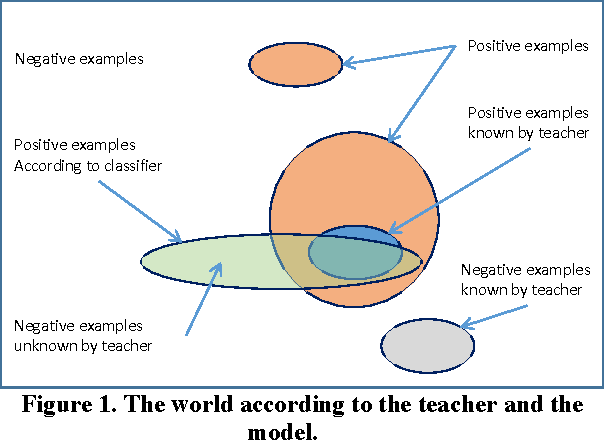
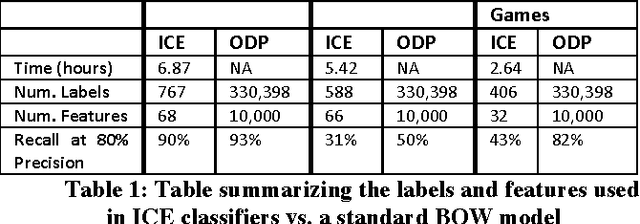
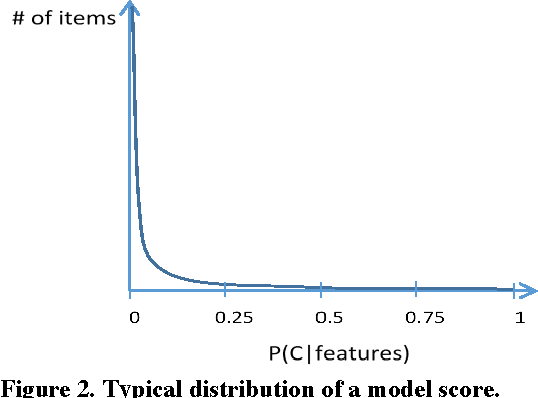
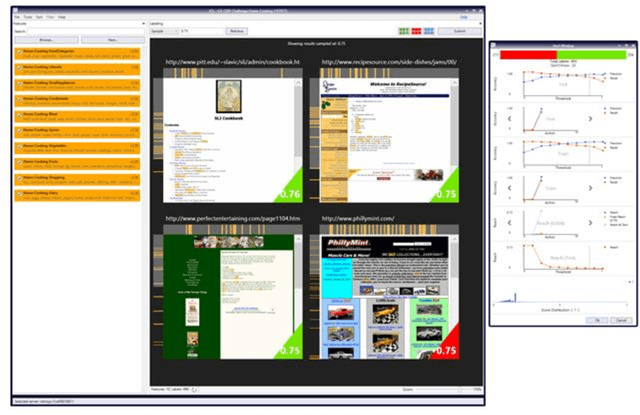
Quick interaction between a human teacher and a learning machine presents numerous benefits and challenges when working with web-scale data. The human teacher guides the machine towards accomplishing the task of interest. The learning machine leverages big data to find examples that maximize the training value of its interaction with the teacher. When the teacher is restricted to labeling examples selected by the machine, this problem is an instance of active learning. When the teacher can provide additional information to the machine (e.g., suggestions on what examples or predictive features should be used) as the learning task progresses, then the problem becomes one of interactive learning. To accommodate the two-way communication channel needed for efficient interactive learning, the teacher and the machine need an environment that supports an interaction language. The machine can access, process, and summarize more examples than the teacher can see in a lifetime. Based on the machine's output, the teacher can revise the definition of the task or make it more precise. Both the teacher and the machine continuously learn and benefit from the interaction. We have built a platform to (1) produce valuable and deployable models and (2) support research on both the machine learning and user interface challenges of the interactive learning problem. The platform relies on a dedicated, low-latency, distributed, in-memory architecture that allows us to construct web-scale learning machines with quick interaction speed. The purpose of this paper is to describe this architecture and demonstrate how it supports our research efforts. Preliminary results are presented as illustrations of the architecture but are not the primary focus of the paper.