 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond
Nov 06, 2024



Run-time steering strategies like Medprompt are valuable for guiding large language models (LLMs) to top performance on challenging tasks. Medprompt demonstrates that a general LLM can be focused to deliver state-of-the-art performance on specialized domains like medicine by using a prompt to elicit a run-time strategy involving chain of thought reasoning and ensembling. OpenAI's o1-preview model represents a new paradigm, where a model is designed to do run-time reasoning before generating final responses. We seek to understand the behavior of o1-preview on a diverse set of medical challenge problem benchmarks. Following on the Medprompt study with GPT-4, we systematically evaluate the o1-preview model across various medical benchmarks. Notably, even without prompting techniques, o1-preview largely outperforms the GPT-4 series with Medprompt. We further systematically study the efficacy of classic prompt engineering strategies, as represented by Medprompt, within the new paradigm of reasoning models. We found that few-shot prompting hinders o1's performance, suggesting that in-context learning may no longer be an effective steering approach for reasoning-native models. While ensembling remains viable, it is resource-intensive and requires careful cost-performance optimization. Our cost and accuracy analysis across run-time strategies reveals a Pareto frontier, with GPT-4o representing a more affordable option and o1-preview achieving state-of-the-art performance at higher cost. Although o1-preview offers top performance, GPT-4o with steering strategies like Medprompt retains value in specific contexts. Moreover, we note that the o1-preview model has reached near-saturation on many existing medical benchmarks, underscoring the need for new, challenging benchmarks. We close with reflections on general directions for inference-time computation with LLMs.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023
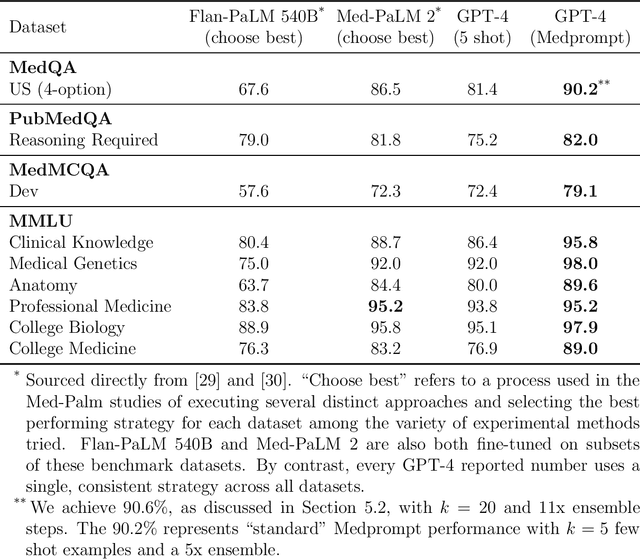


Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Supporting Human-AI Collaboration in Auditing LLMs with LLMs
Apr 19, 2023



Large language models are becoming increasingly pervasive and ubiquitous in society via deployment in sociotechnical systems. Yet these language models, be it for classification or generation, have been shown to be biased and behave irresponsibly, causing harm to people at scale. It is crucial to audit these language models rigorously. Existing auditing tools leverage either or both humans and AI to find failures. In this work, we draw upon literature in human-AI collaboration and sensemaking, and conduct interviews with research experts in safe and fair AI, to build upon the auditing tool: AdaTest (Ribeiro and Lundberg, 2022), which is powered by a generative large language model (LLM). Through the design process we highlight the importance of sensemaking and human-AI communication to leverage complementary strengths of humans and generative models in collaborative auditing. To evaluate the effectiveness of the augmented tool, AdaTest++, we conduct user studies with participants auditing two commercial language models: OpenAI's GPT-3 and Azure's sentiment analysis model. Qualitative analysis shows that AdaTest++ effectively leverages human strengths such as schematization, hypothesis formation and testing. Further, with our tool, participants identified a variety of failures modes, covering 26 different topics over 2 tasks, that have been shown before in formal audits and also those previously under-reported.
Capabilities of GPT-4 on Medical Challenge Problems
Mar 20, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation across various domains, including medicine. We present a comprehensive evaluation of GPT-4, a state-of-the-art LLM, on medical competency examinations and benchmark datasets. GPT-4 is a general-purpose model that is not specialized for medical problems through training or engineered to solve clinical tasks. Our analysis covers two sets of official practice materials for the USMLE, a three-step examination program used to assess clinical competency and grant licensure in the United States. We also evaluate performance on the MultiMedQA suite of benchmark datasets. Beyond measuring model performance, experiments were conducted to investigate the influence of test questions containing both text and images on model performance, probe for memorization of content during training, and study probability calibration, which is of critical importance in high-stakes applications like medicine. Our results show that GPT-4, without any specialized prompt crafting, exceeds the passing score on USMLE by over 20 points and outperforms earlier general-purpose models (GPT-3.5) as well as models specifically fine-tuned on medical knowledge (Med-PaLM, a prompt-tuned version of Flan-PaLM 540B). In addition, GPT-4 is significantly better calibrated than GPT-3.5, demonstrating a much-improved ability to predict the likelihood that its answers are correct. We also explore the behavior of the model qualitatively through a case study that shows the ability of GPT-4 to explain medical reasoning, personalize explanations to students, and interactively craft new counterfactual scenarios around a medical case. Implications of the findings are discussed for potential uses of GPT-4 in medical education, assessment, and clinical practice, with appropriate attention to challenges of accuracy and safety.